
單軸快排(SinglePivotQuickSort)和雙軸快排(DualPivotQuickSort)及其JAVA實現
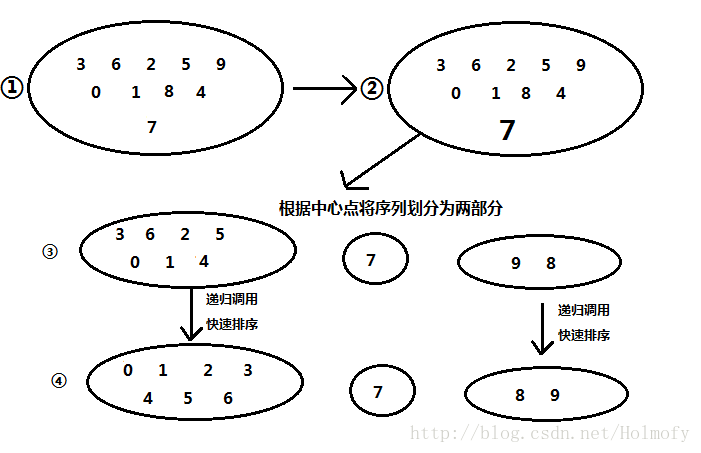
快速排序使用的是分治思想,將原問題分成若干個子問題進行遞迴解決。通過一趟排序將要排序的資料分割成獨立的兩部分,其中一部分的所有資料都比另外一部分的所有資料都要小,然後再按此方法對這兩部分資料分別進行快速排序,整個排序過程可以遞迴進行,以此達到整個資料變成有序序列。
單軸快排(SinglePivotQuickSort)
單軸快速排序是快速排序最簡單的實現。
步驟如下:
- 如果待排序的陣列項數為0或1,直接返回。(遞迴出口)
- 在待排序的陣列中任選一個元素,作為中心點(pivot)。
- 將小於pivot的元素,大於pivot的元素劃分為開來。也就是將小於中心點的元素放在中心點前面,大於中心點的元素放在中心點後面。
- 對前面小於pivot的元素進行快速排序,對大於pivot的元素進行快速排序。
根據上面的步驟可以看出,如何將大於pivot和小於pivot的元素進行劃分是實現快速排序的關鍵
元素劃分的方式
兩端掃描交換方式
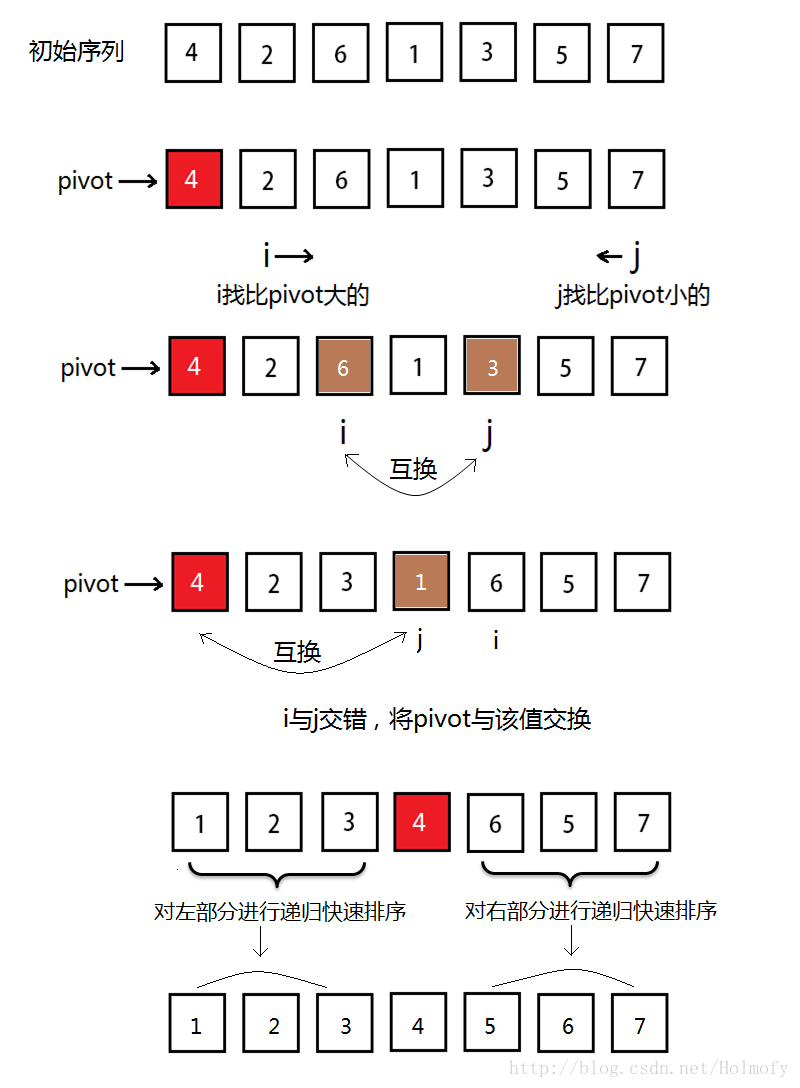
注意 :i 與 j 必須交錯,如果兩者相遇之後就停止比較,那相遇點所在的元素就沒有和中心點進行比較。
實現程式碼:
/**
* 雙端掃描交換 Double-End Scan and Swap
*
* @param items
* 待排序陣列
*/
public void deScanSwapSort(int[] items) {
deScanSwapSort(items, 0 賦值填充方式 —- 一端挖坑一端填充
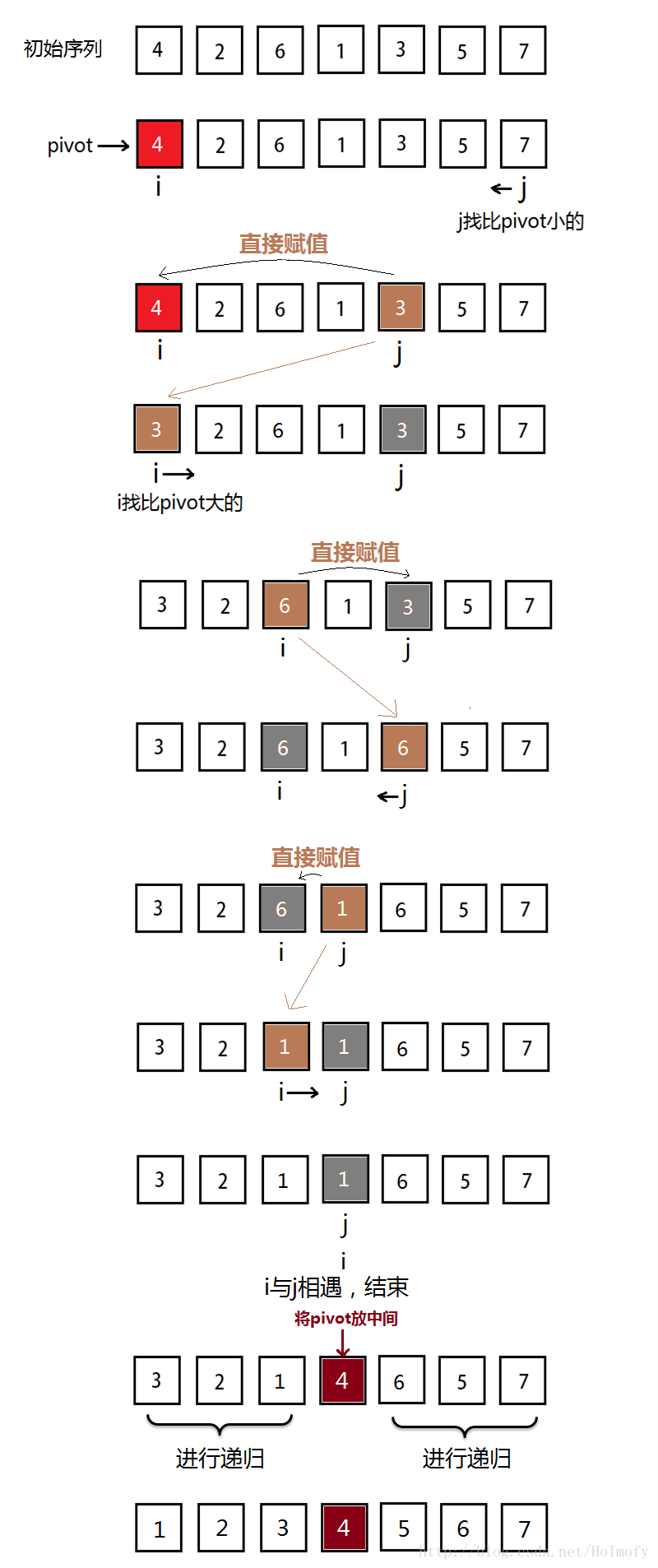
注意:最後 i 和 j 相遇,所在的位置是個坑。
實現程式碼:
/**
* 賦值填充方式
* 一端挖坑一端填充
*
* @param items
* 待排序陣列
*/
public void fillSort(int[] items) {
fillSort(items, 0, items.length - 1);
}
public void fillSort(int[] items, int start, int end) {
if (start < end) {
int pivot = items[start];
int i = start, j = end;
while (i < j) {
while (i < j && items[j] > pivot)
j--;
items[i] = items[j];
while (i < j && items[i] <= pivot)
i++;
items[j] = items[i];
}
// 相遇後i == j,此處是個坑
items[i] = pivot;
fillSort(items, start, i - 1);
fillSort(items, i + 1, end);
}
}單向掃描劃分方式
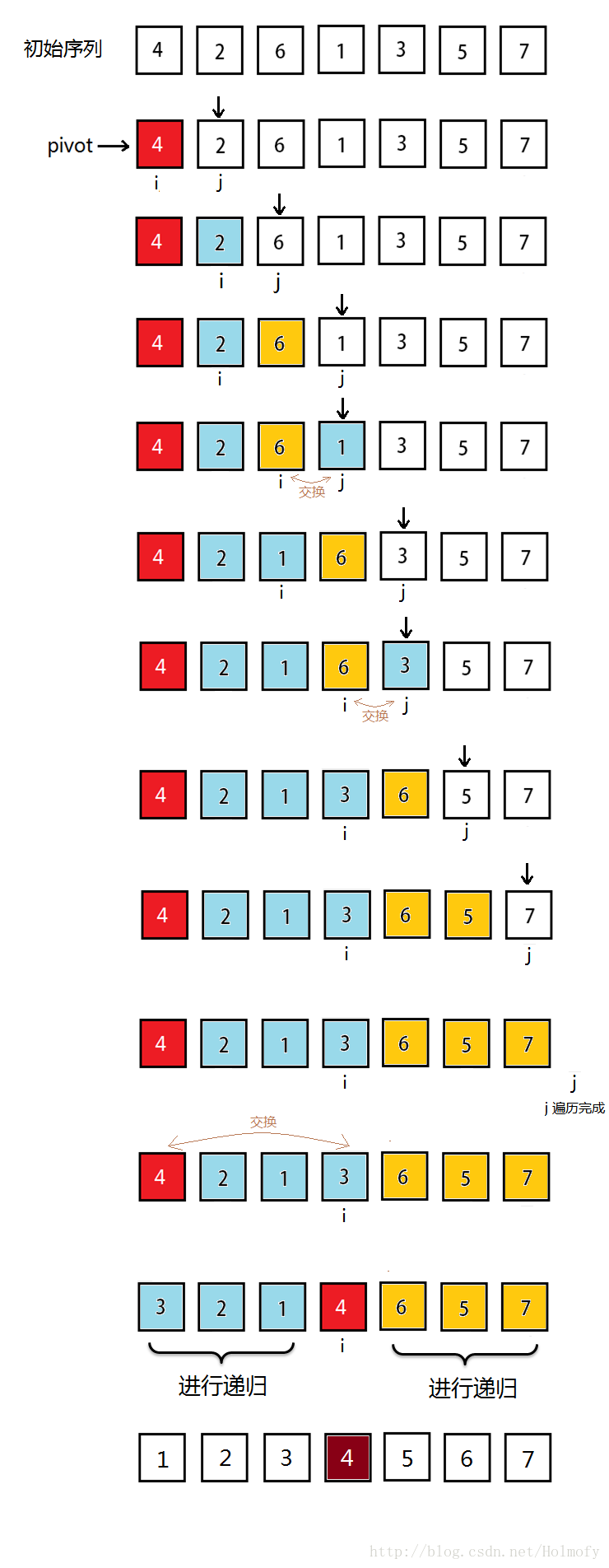
前面的i,j標記都是相向而行,i標記負責找比pivot大的元素,j標記負責比pivot小的元素。下面要說的這種實現方式中思想與前兩者不太一樣:
初始時,i=start,j=start+1;j 負責掃描整個序列。
掃描過程中始終保持:序列中start+1~ i 是小於pivot;i+1~ j 是大於pivot的。
為了保持2的特性,j掃描時遇到小於pivot的元素,i++,並將i元素與j元素進行交換,然後掃描下一個元素;
遇到大於pivot的元素,直接掃描下一個元素。
整個序列掃描完成後,將第一個元素pivot與小於pivot的元素的最後一個進行交換。
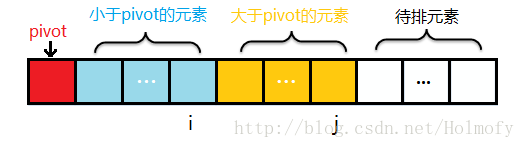
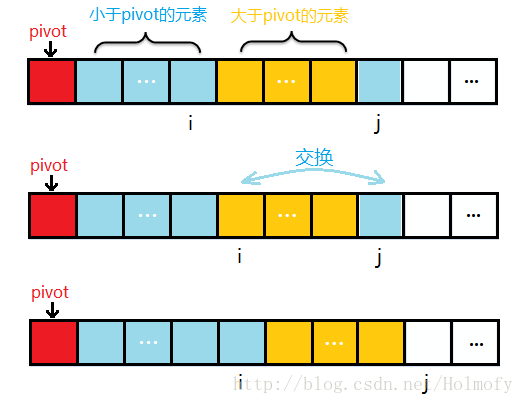
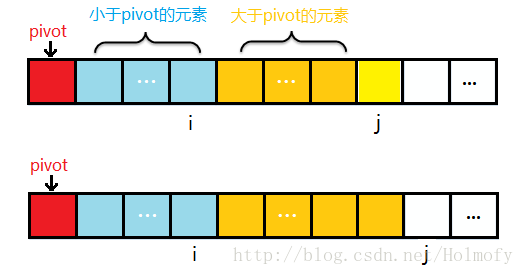
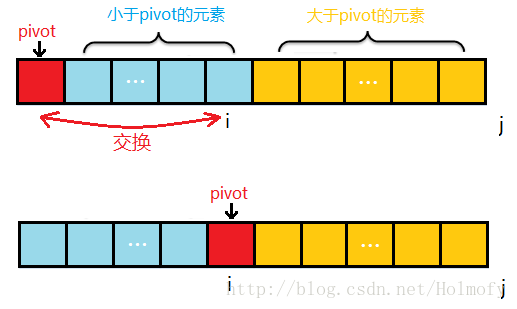
示例過程圖如下:
實現程式碼:
/**
* 單向掃描劃分方式
*
* @param items
* 待排序陣列
*/
public void forwardScanSort(int[] items) {
forwardScanSort(items, 0, items.length - 1);
}
public void forwardScanSort(int[] items, int start, int end) {
if (start < end) {
int pivot = items[start];
int i = start, j = start + 1;
while (j <= end) {
if (items[j] < pivot) {
i++;
swap(items, i, j);
}
j++;
}
swap(items, start, i);
forwardScanSort(items, start, i - 1);
forwardScanSort(items, i + 1, end);
}
}單軸快排的一種優化方式—-三分單向掃描
先來看一個例子:
對於這樣一個序列2,2,2,2,3,1,我們使用上面提到的單軸快排中最簡單的實現對其進行排序:選擇第一個元素2作為pivot中心點,劃分後得到兩段子序列分別為:1和2,2,3,2,接著繼續遞迴對子序列進行排序,對於2,2,3,2子序列又是將2作為pivot中心點… 你會發現對於這種大量元素等於pivot的序列,單軸快排並沒有起到很好的劃分作用。如果我們將等於pivot的元素也作為一個劃分區段,則可以將序列劃分為3段:小於pivot的元素,等於pivot的元素,大於pivot的元素。看下圖:
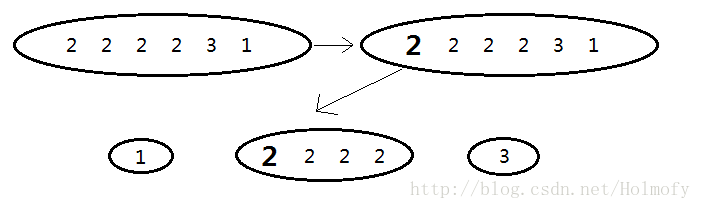
很明顯的看出這種處理方式,會大大節省遞迴次數。
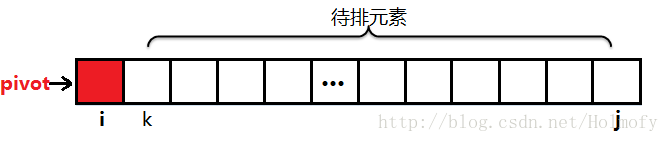
如何實現該演算法呢,很顯然我們不能使用像上面單軸快排中前兩種相向掃描的方式,我們要結合上面的幾種實現方式—-單向掃描,雙向靠攏,看下面的很容易理解。不過為了將序列劃分為三個區段我們需要三個變數i,j,k。大致過程如下:
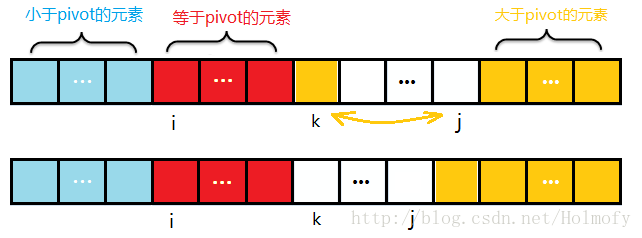
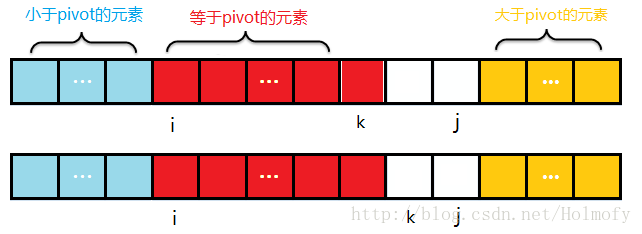
初始化時,i=start,j=end,k=start+1。k負責掃描。
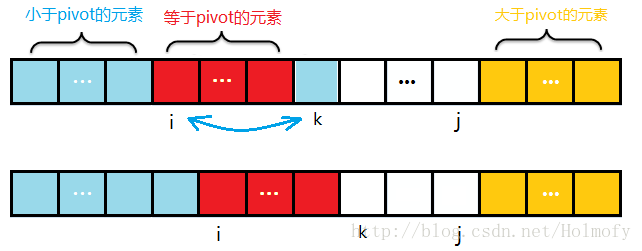
掃描過程中始終保持:start~i是小於pivot的元素,i~k是等於pivot的元素,j~end是大於pivot的元素
掃描過程中,遇到小於pivot的元素,i與k元素進行交換,i++,然後k掃描下一個元素;
遇到大於pivot的元素,k與j交換,j–,k不需加一,繼續掃描k處元素。
掃描過程遇到等於pivot的元素,直接掃描下一個元素。
- pivot已經包含在等於pivot的分段中,無需交換。最後k>j的時候停止掃描。

實現程式碼:
/**
* 三分單向掃描
*/
public void div3ScanSort(int[] items) {
div3ScanSort(items, 0, items.length - 1);
}
public void div3ScanSort(int[] items, int start, int end) {
if (start < end) {
int pivot = items[start];
int i = start, j = end, k = start + 1;
while (k <= j) {
if (items[k] < pivot) {
swap(items, i, k);
i++;
k++;
} else if (items[k] > pivot) {
swap(items, j, k);
j--;
} else {
k++;
}
}
div3ScanSort(items, start, i - 1);
div3ScanSort(items, j + 1, end);
}
}另一種優化—-三分雙向掃描
在上面的實現中,掃描到大於pivot的元素,將最後一個未掃描的元素(j所在的位置)與當前元素(k所在的位置)進行交換。那如果這個未掃描的元素正好是比pivot大的元素呢,這無疑增加了交換的次數。
所以j索引應當掃描到一個不比pivot大的元素,再做判斷,如果==pivot,將k與j進行交換,如果
/**
* 雙端掃描三分排序
*/
public void div3DeScanSort(int[] items) {
div3DeScanSort(items, 0, items.length - 1);
}
public void div3DeScanSort(int[] items, int start, int end) {
if (start < end) {
int pivot = items[start];
int i = start, j = end, k = start + 1;
OUT_LOOP: while (k <= j) {
if (items[k] < pivot) {
swap(items, i, k);
i++;
k++;
} else if (items[k] == pivot) {
k++;
} else {
// j向左掃描,直到一個不大於pivot的元素
while (items[j] > pivot) {
j--;
if (k > j) {
// 後面的待排元素全大於pivot,直接結束排序
break OUT_LOOP;
}
}
if (items[j] < pivot) {
swap(items, j, k);
swap(items, i, k);
i++;
} else {
swap(items, j, k);
}
k++;
j--;
}
}
div3DeScanSort(items, start, i - 1);
div3DeScanSort(items, j + 1, end);
}
}雙軸快排(DualPivotQuickSort)
雙軸快排思想
理解了前面的三分單向掃描和三分雙向掃描,雙軸快速排序就很好理解了。
雙軸快速排序,顧名思義,取兩個中心點pivot1,pivot2,且pivot≤pivot2,可將序列分成三段:x<pivot1、pivot1≤x≤pivot2,x<pivot2,然後分別對三段進行遞迴。基本過程如下圖:

既然要兩個中心點,我們一般將第一個元素和最後一個元素作為兩個中心點。實現大致過程如下:
初始化時,i=start,j=end,k=start+1,k負責掃描。序列第一個值大於序列最後一個值,需要進行交換。然後pivot1=items[start],pivot2=items[end]。
掃描過程中保持:1~i是小於pivot1的元素,i~k是大於等於pivot1、小於等於pivot2的元素,j~end-1是大於pivot2的元素。
掃描過程與前面的三分雙向掃描類似。
最後掃描完成,將pivot1與pivot2移到中間(這和之前講的都差不多,就不在這進行過多的解釋了)。


實現程式碼:
/**
* 雙軸快排
*
* @param items
*/
public void dualPivotQuickSort(int[] items) {
dualPivotQuickSort(items, 0, items.length - 1);
}
public void dualPivotQuickSort(int[] items, int start, int end) {
if (start < end) {
if (items[start] > items[end]) {
swap(items, start, end);
}
int pivot1 = items[start], pivot2 = items[end];
int i = start, j = end, k = start + 1;
OUT_LOOP: while (k < j) {
if (items[k] < pivot1) {
swap(items, ++i, k++);
} else if (items[k] <= pivot2) {
k++;
} else {
while (items[--j] > pivot2) {
if (j <= k) {
// 掃描終止
break OUT_LOOP;
}
}
if (items[j] < pivot1) {
swap(items, j, k);
swap(items, ++i, k);
} else {
swap(items, j, k);
}
k++;
}
}
swap(items, start, i);
swap(items, end, j);
dualPivotQuickSort(items, start, i - 1);
dualPivotQuickSort(items, i + 1, j - 1);
dualPivotQuickSort(items, j + 1, end);
}
}各種實現速度大比拼
我們測試的序列長度為10000
private final int[] testItems = new int[10000];為了更精確的測量耗時,我們使用的單位是納秒
start = System.nanoTime();
xxxSort(tmp);
end = System.nanoTime();對多重複元素的序列進行排序
for (int i = 0; i < testItems.length; i++) {
testItems[i] = (int) (Math.random() * 100);
}這裡我們隨機生成100以內的數字,這個序列中肯定有大量重複的數字,這裡取5次測試
forwardScanSort: 5478840 5378672 5097875 3898327 5543293 平均:5077401
fillSort : 6060962 5830248 6263760 5737880 6264992 平均:6031568
deScanSwapSort: 8733057 5184906 9776196 6462043 8275323 平均:7686305
div3ScanSort: 3749307 4663541 4904929 4225924 4642604 平均:4437261
div3DeScanSort: 3935273 4457049 4770688 3951695 4396291 平均:4302199
dualPivotQuickSort:8891518 5160274 5430809 4968971 5393451 平均:5969004
Arrays.sort: 3513666 3856864 3460299 3684855 3888063 平均:3680749對稀疏序列進行排序
這次生成的隨機數是10萬以內的。
for (int i = 0; i < testItems.length; i++) {
testItems[i] = (int) (Math.random() * 100000);
}測試結果
forwardScanSort: 3088775 3257911 3402414 2415518 3579351 平均:3148793
fillSort : 3606444 3495603 3665970 2871609 6503916 平均:4028708
deScanSwapSort: 9766343 9425198 4219766 3890937 7017070 平均:6863862
div3ScanSort: 5138927 4565016 6069582 4714857 5053538 平均:5108384
div3DeScanSort: 4303513 4722246 5923026 3613423 4158188 平均:4544079
dualPivotQuickSort:5681229 3971810 4823645 3376963 4739078 平均:4518545
arrays.sort: 5820806 5953815 6402928 7119290 7506824 平均:6560732Arrays.sort底層使用的也是DualPivotQuickSort,這個類對雙軸快排在策略上進行了一個改動(不僅僅是雙軸快排,還是用到了其他的排序,如直接插入排序,對於byte,char,short基本型別還用到了計數排序)。關於其他排序演算法的實現可以參考這篇文章。