
基於spark streaming的流資料處理和分析
阿新 • • 發佈:2019-02-02
Stream context 相當於spark context
做實時處理就得用到
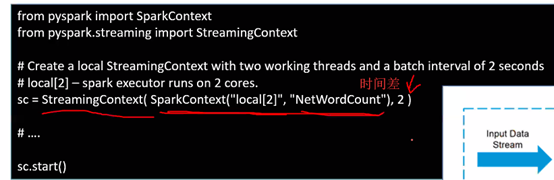
setup之後如果close你需要重新建立一個,重啟是不行的

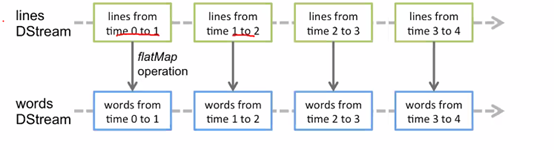
詞頻統計,stream context
ssc.start()執行之後,上面程式碼段才會執行
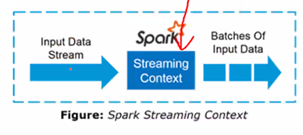
一系列不停的RDD
Receives接收器
建立多個receivers 你需要 在cluster裡
Nifi可以往kafka送,或者sparksteaming從nifi拿
在spark-shell實現wc
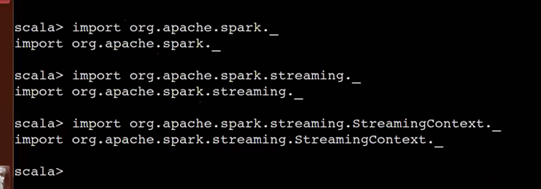
導包
![]()

如果已經常建立streamingcontext的話

![]()

隨便給一個埠

開啟網口

原始碼放出
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
RDD的join

Join必須是k,v
Rdd分解成若干個分割槽
不同的分割槽在不同的程序或者機器上
一個rdd很多分割槽,一個節點建立connection不可以傳到另一個機器上,為了安全性考慮
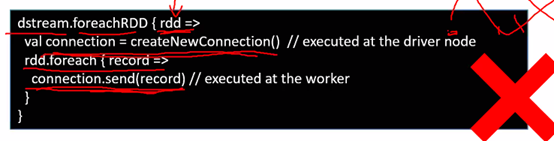
所以連線是不可以被序列化或者反序列化

所以在一臺機器上建立的connection不可以在多個分割槽上
所以要foreach每一個
![]()
聚合計算處理不一定基於bykey bywindow
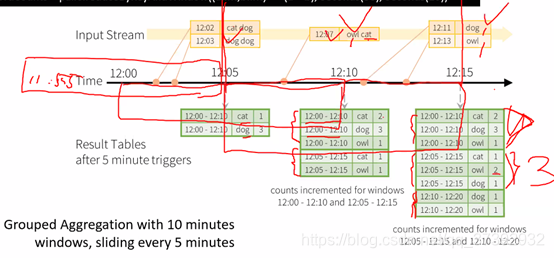

只要有這些引數會自動進行視窗的儲存
這是內建功能

下面可以自動還原 stream connection
如何實施 checkpointing
可以是kafka也可以是flume等等
結構和程式碼功能雷同

視窗滑動5-10次應該呼叫一下這個方法