聚類索引和非聚類索引
-
為什麼要給表加上主鍵?
-
為什麼加索引後會使查詢變快?
-
為什麼加索引後會使寫入、修改、刪除變慢?
-
什麼情況下要同時在兩個欄位上建索引?
聚集索引和非聚集索引的根本區別是表記錄的排列順序和與索引的排列順序是否一致,
聚集索引儲存記錄是物理上連續存在,而非聚集索引是邏輯上的連續,物理儲存並不連續
聚集索引
在某些關係資料庫中, 如果建表時不指定主鍵,資料庫會拒絕建表的語句執行。 事實上, 一個加了主鍵的表,並不能被稱之為「表」。一個沒加主鍵的表,它的資料無序的放置在磁碟儲存器上,一行一行的排列的很整齊。如果給表上了主鍵,那麼表在磁碟上的儲存結構就由整齊排列的結構轉變成了樹狀結構,也就是「平衡樹」結構,換句話說,就是整個表就變成了一個索引。沒錯, 再說一遍, 整個表變成了一個索引,也就是所謂的「聚集索引」。 這就是為什麼一個表只能有一個主鍵, 一個表只能有一個「聚集索引」,因為主鍵的作用就是把「表」的資料格式轉換成「索引(平衡樹)」的格式放置。

上圖就是帶有主鍵的表(聚集索引)的結構圖。其中樹的所有結點(底部除外)的資料都是由主鍵欄位中的資料構成,也就是通常我們指定主鍵的id欄位。最下面部分是真正表中的資料。

索引能讓資料庫查詢資料的速度上升, 而使寫入資料的速度下降,原因很簡單的, 因為平衡樹這個結構必須一直維持在一個正確的狀態, 增刪改資料都會改變平衡樹各節點中的索引資料內容,破壞樹結構, 因此,在每次資料改變時, DBMS必須去重新梳理樹(索引)的結構以確保它的正確,這會帶來不小的效能開銷,也就是為什麼索引會給查詢以外的操作帶來副作用的原因。
非聚集索引
也就是我們平時經常提起和使用的常規索引。非聚集索引和聚集索引一樣, 同樣是採用平衡樹作為索引的資料結構。索引樹結構中各節點的值來自於表中的索引欄位, 假如給user表的name欄位加上索引 , 那麼索引就是由name欄位中的值構成,在資料改變時, DBMS需要一直維護索引結構的正確性。如果給表中多個欄位加上索引 , 那麼就會出現多個獨立的索引結構,每個索引(非聚集索引)互相之間不存在關聯。 如下圖

每次給欄位建一個新索引, 欄位中的資料就會被複制一份出來, 用於生成索引。 因此, 給表新增索引,會增加表的體積, 佔用磁碟儲存空間。
非聚集索引和聚集索引的區別在於, 通過聚集索引可以查到需要查詢的資料, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查詢到需要的資料,如下圖

不管以任何方式查詢表, 最終都會利用主鍵通過聚集索引來定位到資料, 聚集索引(主鍵)是通往真實資料所在的唯一路徑。
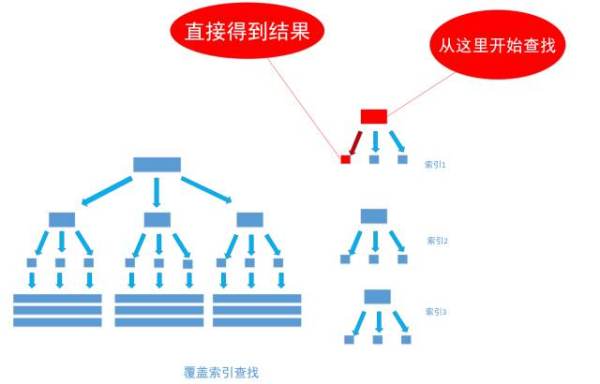
然而, 有一種例外可以不使用聚集索引就能查詢出所需要的資料, 這種非主流的方法 稱之為「覆蓋索引」查詢, 也就是平時所說的複合索引或者多欄位索引查詢。 文章上面的內容已經指出, 當為欄位建立索引以後, 欄位中的內容會被同步到索引之中, 如果為一個索引指定兩個欄位, 那麼這個兩個欄位的內容都會被同步至索引之中。
先看下面這個SQL語句
create index index_birthday on user_info(birthday);//建立索引
select user_name from user_info where birthday = '1991-11-1' ; //查詢生日在1991年11月1日出生使用者的使用者名稱
這句SQL語句的執行過程如下
首先,通過非聚集索引index_birthday查詢birthday等於1991-11-1的所有記錄的主鍵ID值
然後,通過得到的主鍵ID值執行聚集索引查詢,找到主鍵ID值對就的真實資料(資料行)儲存的位置
最後, 從得到的真實資料中取得user_name欄位的值返回, 也就是取得最終的結果
我們把birthday欄位上的索引改成雙欄位的覆蓋索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
這句SQL語句的執行過程就會變為
通過非聚集索引index_birthday_and_user_name查詢birthday等於1991-11-1的葉節點的內容,然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name欄位的值也在裡面, 因此不需要通過主鍵ID值的查詢資料行的真實所在, 直接取得葉節點中user_name的值返回即可。 通過這種覆蓋索引直接查詢的方式, 可以省略不使用覆蓋索引查詢的後面兩個步驟, 大大的提高了查詢效能,如下圖