
dso詳解--dso原理的"大卸八塊"
注:
- 為了讀懂本文,我們假定讀者已具有視覺SLAM的基本知識,否則,請先閱讀相關材料。另外,如果讀過DSO論文或程式碼,可能對本文有更好的理解。
- 由於知乎平臺解析度限制,插圖可能不夠清晰。如果能影象質量有更高要求,請聯絡作者:gao.xiang.thu at gmail dot com.
- 由於本文較長,我會花幾次時間進行更新,應讀者要求先發布草稿版。
以下是本文的提綱:
提綱
- 概述
- 流程框架
- 滑動視窗
- 光度標定
- 評述
- 資料與參考文獻
- 概述(已看get)
DSO屬於稀疏直接法的視覺里程計。它不是完整的SLAM,因為它不包含迴環檢測、地圖複用的功能。因此,它不可避免地會出現累計誤差,儘管很小,但不能消除。DSO目前開源了單目實現,雙目DSO的論文已被ICCV接收,但目前未知是否開源。
DSO是少數使用純直接法(Fully direct)計算視覺里程計的系統之一。相比之下,SVO[2]屬於半直接法,僅在前端的Sparse model-based Image Alignment部分使用了直接法,之後的位姿估計、bundle adjustment,則仍舊使用傳統的最小化重投影誤差的方式。而ORB-SLAM2[3],則屬於純特徵法,計算結果完全依賴特徵匹配。從方法上來說,DSO是新穎、獨樹一幟的。
直接法相比於特徵點法,有兩個非常不同的地方:
- 特徵點法通過最小化重投影誤差來計算相機位姿與地圖點的位置,而直接法則最小化光度誤差(photometric error)。所謂光度誤差是說,最小化的目標函式,通常由影象之間的誤差來決定,而非重投影之後的幾何誤差。
- 直接法將資料關聯(data association)與位姿估計(pose estimation)放在了一個統一的非線性優化問題中,而特徵點法則分步求解,即,先通過匹配特徵點求出資料之間關聯,再根據關聯來估計位姿。這兩步通常是獨立的,在第二步中,可以通過重投影誤差來判斷資料關聯中的外點,也可以用於修正匹配結果(例如[4]中提到的類EM的方法)。
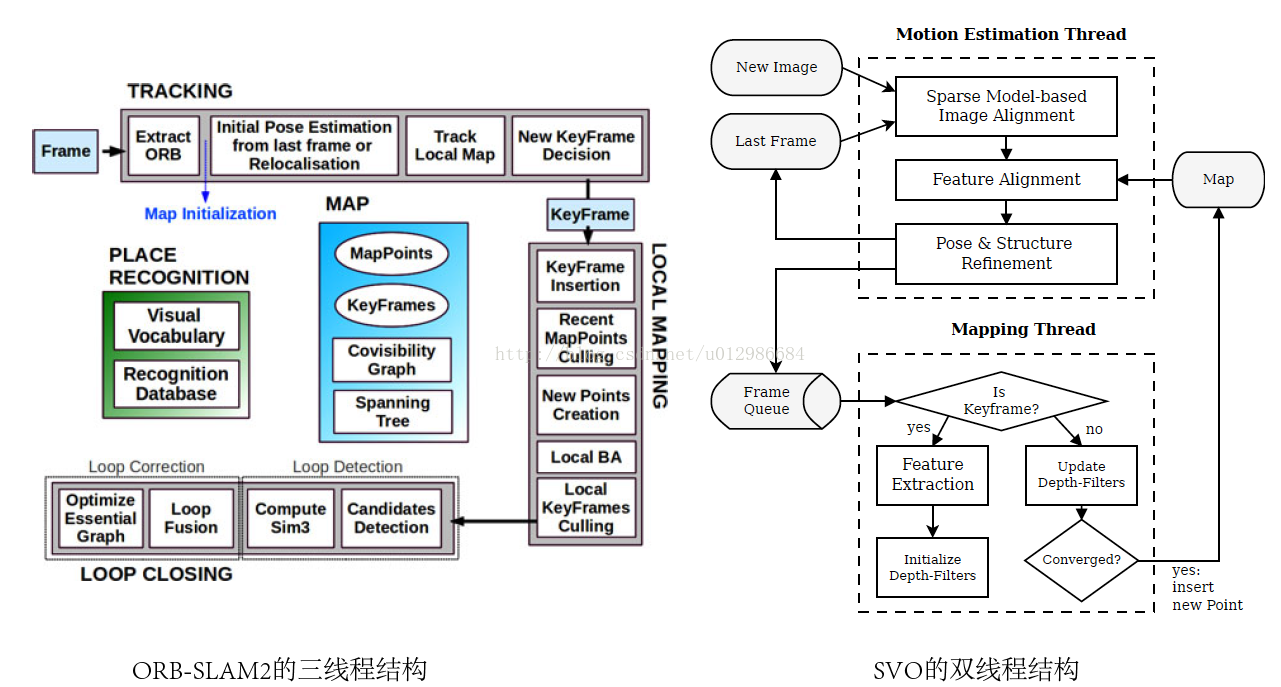
從後端來看,DSO使用一個由若干個關鍵幀組成的滑動視窗作為它的後端。這個視窗在整個VO過程中一直存在,並有一套方法來管理新資料的加入以及老資料的去除。具體來說,這個視窗通常保持5到7個關鍵幀。前端追蹤部分,會通過一定的條件,來判斷新來的幀是否可作為新的關鍵幀插入後端。同時,如果後端發現關鍵幀數已經大於視窗大小,也會通過特定的方法,選擇其中一個幀進行去除。請注意被去除的幀並不一定是時間線上最舊的那個幀,而是會有一些複雜條件的。
後端除了維護這個視窗中的關鍵幀與地圖點外,還會維護與優化相關的結構。特別地,這裡指Gauss-Newton或Levenburg-Marquardt方法中的Hessian矩陣和b向量(僅先驗部分)。當我們增加新的關鍵幀時,就必須擴充套件H和b的維度;反之,如果需要去掉某個關鍵幀(以及它攜帶的地圖點)時,也需要降低H和b的維度。這個過程還需要將被刪掉幀和點的資訊,轉移到視窗內剩餘幀當中,這一步被稱為邊緣化(Marginalization)。
由於直接法需要比較影象資訊,其結果容易受光照干擾。於是,DSO提出了光度標定,認為對相機的曝光時間、暗角、伽馬響應等引數進行標定後,能夠讓直接法更加魯棒。對於未進行光度標定的相機,DSO也會在優化中動態估計光度引數(具體來說,是一個仿射變化的引數,記作a和b)。這個過程建模了相機的成像過程,因此對於由相機曝光不同引起的影象明暗變化,會有更好的表現。但是,如果由於環境光源發生變化,光度標定也是無能為力的。
本文第2節介紹DSO基本框架和流程。第3節介紹滑動視窗內的最小二乘問題、雅可比、邊緣化。第4節介紹光度標定。第5節會給出我個人對DSO的一些評述。最後列出參考文獻。DSO相關的實驗、比較結果,請參見作者原始論文,在此不作敘述。
2. 框架流程
2.1 程式碼框架與資料表示
現在我們來看DSO的大體框架。我去除了一些不重要的類和結構,方便讀者閱讀。

DSO整體程式碼由四個部分組成:系統與各演算法集成於src/FullSystem,後端優化位於src/OptimizationBackend,這二者組成了DSO大部分核心內容。src/utils和src/IOWrapper為一些去畸變、資料集讀寫和視覺化UI程式碼。先來看核心部分的FullSystem和OptimizationBackend。
如上圖上半部分所示,在FullSystem裡,DSO致力於維護一個滑動視窗內部的關鍵幀序列。每個幀的資料儲存於FrameHessian結構體中,FrameHessian即是一個帶著狀態變數與Hessian資訊的幀。然後,每個幀亦攜帶一些地圖點的資訊,包括:
- pointHessians是所有活躍點的資訊。所謂活躍點,是指它們在相機的視野中,其殘差項仍在參與優化部分的計算;
- pointHessiansMarginalized是已經邊緣化的地圖點。
- pointHessiansOut是被判為外點(outlier)的地圖點。
- 以及immaturePoints為未成熟地圖點的資訊。
在單目SLAM中,所有地圖點在一開始被觀測到時,都只有一個2D的畫素座標,其深度是未知的。這種點在DSO中稱為未成熟的地圖點:Immature Points。隨著相機的運動,DSO會在每張影象上追蹤這些未成熟的地圖點,這個過程稱為trace——實際上是一個沿著極線搜尋的過程,十分類似於svo的depth filter。Trace的過程會確定每個Immature Point的逆深度和它的變化範圍。如果Immature Point的深度(實際中為深度的倒數,即逆深度)在這個過程中收斂,那麼我們就可以確定這個未成熟地圖點的三維座標,形成了一個正常的地圖點。具有三維座標的地圖點,在DSO中稱為PointHessian。與FrameHessian相對,PointHessian亦記錄了這個點的三維座標,以及Hessian資訊。
與很多其他SLAM方案不同,DSO使用單個引數描述一個地圖點,即它的逆深度。而ORB-SLAM等多數方案,則會記錄地圖點的x,y,z三個座標。逆深度引數化形式具有形式簡單、類似高斯分佈、對遠處場景更為魯棒等優點[5],但基於逆深度引數化的Bundle adjustment,每個殘差項需要比通常的BA多計算一個雅可比矩陣。為了使用逆深度,每個PointHessian必須擁有一個主導幀(host frame),說明這個點是由該幀反投影得到的。
於是,滑動視窗的所有資訊,可以由若干個FrameHessian,加上每個幀帶有的PointHessian來描述。所有的PointHessian又可以在除主導幀外的任意一幀中進行投影,形成一個殘差項,記錄於PointHessian::residuals中。所有的殘差加起來,就構成了DSO需要求解的優化問題。當然,由於運動、遮擋的原因,並非每個點都可以成功地投影到其餘任意一幀中去,於是我們還需要設定每個點的狀態:有效的/被邊緣化的/無效的。不同狀態的點,被儲存於它主導幀的pointHessians/pointHessianMarginalized/PointHessiansOut三個容器內。
除此之外,DSO將相機的內參、曝光引數等資訊,亦作為優化變數考慮在內。相機內參由針孔相機引數fx, fy, cx, cy表達,曝光引數則由兩個引數a,b描述。這部分內容在光度標定一節內。
後端優化部分單獨具有獨立的Frame, Point, Residual結構。由於DSO的優化目標是最小化能量(energy,和誤差類似),所以有關後端的類均以EF開頭,且與FullSystem中儲存的例項一一對應,互相持有對方的指標。優化部分由EnergyFunctional類統一管理。它從FullSystem中獲取所有幀和點的資料,進行優化後,再將優化結果返回。它也包含整個滑動視窗內的所有幀和點資訊,負責處理實際的非線性優化矩陣運算。
2.2 VO流程
每當新的影象到來時,DSO將處理此影象的資訊,流程如下:
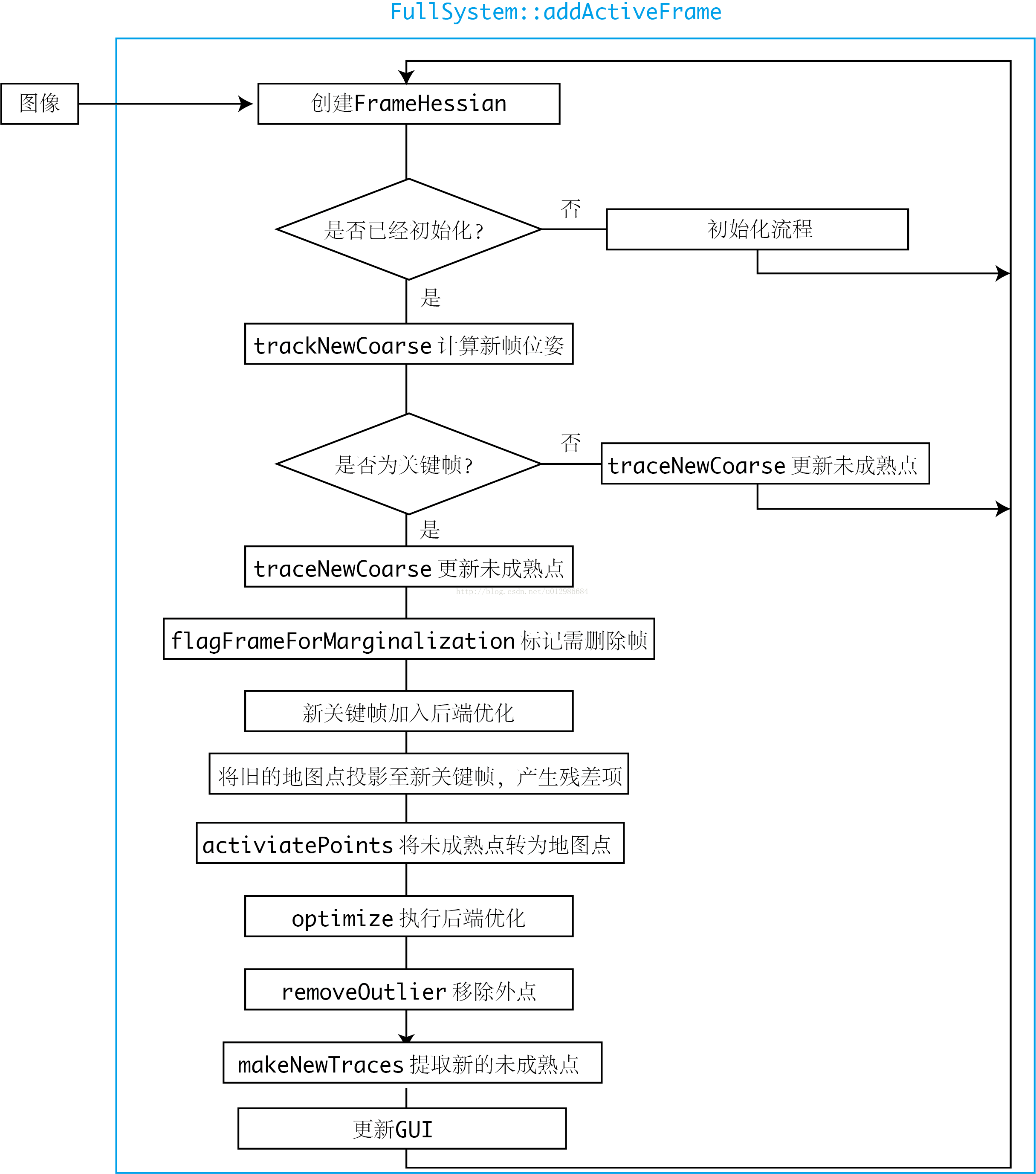
儘管沒有解釋每一步的具體用意,但可以看出DSO的大致流程。從上圖可以簡單總結出DSO的行為:
- 對於非關鍵幀,DSO僅計算它的位姿,並用該幀影象更新每個未成熟點的深度估計;
- 後端僅處理關鍵幀部分的優化。除去一些記憶體維護操作,對每個關鍵幀主要做的處理有:增加新的殘差項、去除錯誤的殘差項、提取新未成熟點。
- 整個流程在一個執行緒內,但內部可能有多執行緒的操作。
3. DSO詳細介紹
3.1 殘差的構成與雅可比(公式未細看)
在VO過程中,DSO會維護一個滑動視窗,通常由5-7個關鍵幀組成,流程如前所述。DSO試圖將每個先前關鍵幀中的地圖點投影到新關鍵幀中,形成殘差項。同時,會在新關鍵幀中提取未成熟點,並希望它們演變成正常地圖點。在實際當中,由於運動、遮擋的原因,部分殘差項會被當作outlier,最終剔除;也有部分未成熟地圖點無法演化成正常地圖點,最終被剔除。
滑動視窗內部構成了一個非線性最小二乘問題。表示成因子圖(或圖優化)的形式,如下所示:
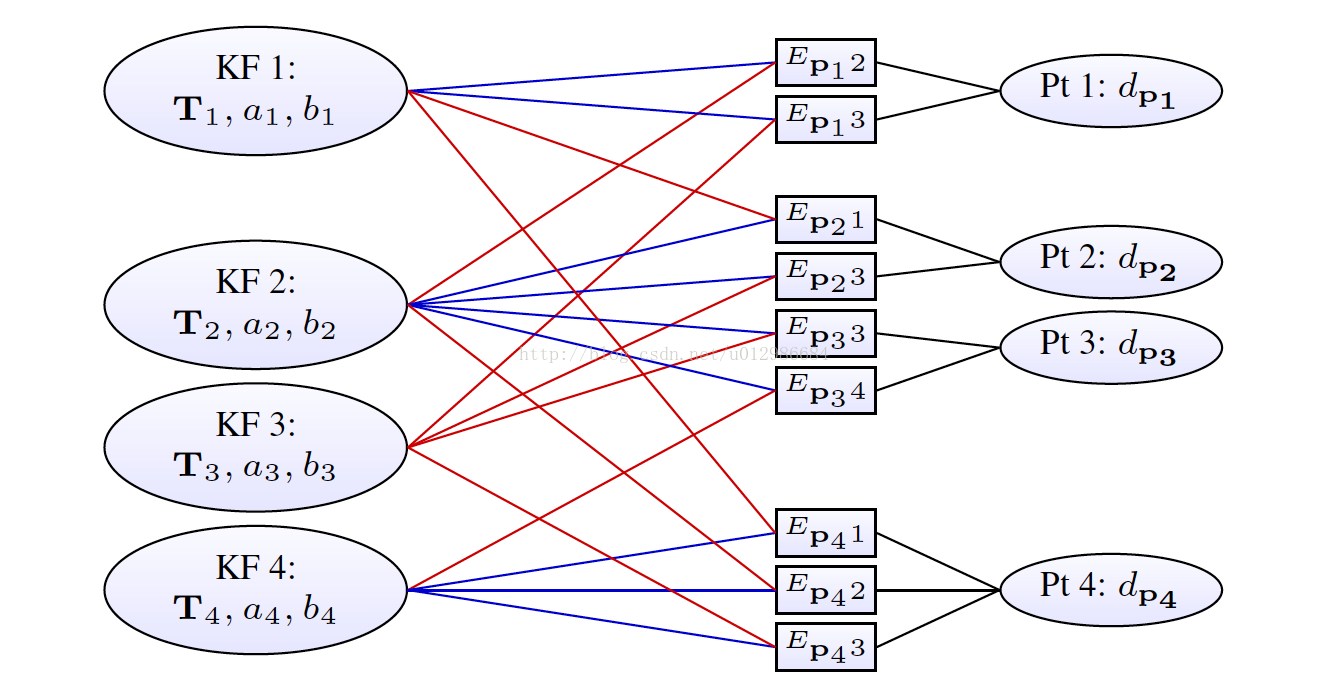
每一個關鍵幀的狀態為八維:六自由度的運動位姿加上兩個描述光度的引數;每個地圖點的狀態變數為一維,即該點在主導幀(Host)裡的逆深度。於是,每個殘差項(或能量項E),將關聯兩個關鍵幀與一個逆深度。事實上,還有一個全域性的相機內參數亦參與了優化,但未在此圖中表示。
現在我們來考慮如何計算殘差。這部分推導和LSD-SLAM的會議論文[6],以及我的書[7]是類似的。如果讀者覺得有困難,可以參照它們。
設相機模型由針孔模型描述,那麼內參矩陣為:
設有兩個幀,一個稱為Host,一個稱Target,它們各自到世界座標的變換矩陣記為
,這二者又可以拆開為旋轉和平移。考慮Host幀中一個畫素點:
其中 為該點的畫素座標,這裡使用了齊次座標以方便矩陣運算。同時,該點的逆深度為:
其中 為該點的深度值。那麼,這個點在Target幀中的投影為:
注:(i). 為方便起見,我們略去了此公式中的齊次座標至非齊次的轉換,預設它們是自動轉換的;(ii). 我們定義了中間變數
,即點的世界座標,以及Host至Target的相對變換。
由此可以定義該點的殘差。設Host和Target的影象分別是 ,那麼殘差為:
但是在實現中,DSO會同時估計影象的光度引數a,b,所以在計算誤差時,會用到去掉光度引數之後的那個值。但是這裡我們先不談光度標定部分,所以暫時把
看成原始影象。
接下來我們要談論雅可比。在完整DSO中,雅可比由三部分組成:
- 影象雅可比,即影象梯度;
- 幾何雅可比,描述各量相對幾何量,例如旋轉和平移的變化率;
- 光度雅可比,描述各個量相對光度引數的雅可比;
作者認為,幾何和光度的雅可比,相對自變數來說通常是光滑函式;而影象雅可比則依賴影象資料,不夠光滑;所以,在優化過程中,幾何和光度的雅可比僅在迭代開始時計算一次,此後固定不變[1]。而影象雅可比則隨著迭代更新。這種做法稱為First-Estimate-Jacobian(FEJ),在VIO中也會經常用到[8]。它可以減小計算量、防止優化往錯誤的地方走太多,也可以在邊緣化過程中保證零空間的維度不會降低,後者我們還要在後文繼續談。
下面來看幾何雅可比的具體計算。記 為李代數表示的
,並定義:
根據[7]的推導加一些變化,可知:
再考慮對於Host幀中的逆深度 之雅可比:
顯然:
對於後者,首先記:
那麼:
其中下標1表示取第一行,3表示第三行。於是
最後的式子中我們重新把 代回去,使得式子更加簡潔。同理有:
於是得:
接下來考慮殘差相對於相機內參的雅可比,這部分相對於其餘部分稍為複雜,我們僅展示殘差對 之導數,其餘部分類似可得,因此留給讀者。由於:
該式略去了 的下標,以保持行文簡潔。展開後式,有:
於是:
現在想要求第一行關於 之導數,由鏈式法則:
而
第一項中,由前述,有:
於是
第二項:
因此:
於是,得到了投影點關於 的導數。關於
的結論可類似推出,不再贅述。以上計算均實現於PointFrameResidual::linearize函式。
值得一提的是,在DSO中,每個投影點,除了自身的位置之外,一共提供八維殘差,這是為了更好利用該點的資訊。這八維殘差由這個點與周圍幾個點組成的Pattern定義,如下圖所示:
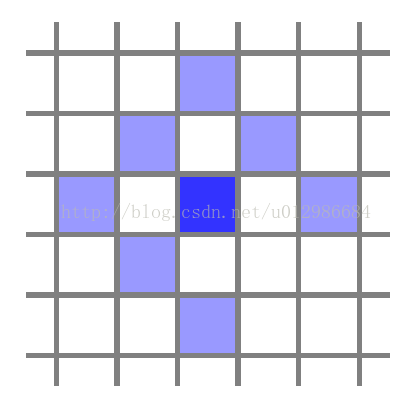
選八個點是為了方便SSE(Super Strong Erection)(霧),其實在settings.cpp中還有許多別的Pattern。所以,在DSO的直接法中,我們實際上假設了這八個點在不同影象中保持灰度不變。並且,它們在優化中共享中間點的深度,所以也不能簡單地看成八個獨立的點。
3.2 滑動視窗的維護與邊緣化(重要點:邊緣化概念)
若干和關鍵幀,與它們關聯的地圖點組成的殘差項,構成了整個滑動視窗中的內容。為了優化這些幀和點,我們會利用Gauss-Newton或Levernberg-Marquardt方法進行迭代。在迭代中,所有的殘差項可以拼成一個大型的線性方程:
其中 分別為拼接後的雅可比、權重和殘差,
為整體的優化更新量。左側可以記成:
,即Hessian矩陣。這個矩陣在整個優化過程中都會一直維護於記憶體中。注意這種做法和ORB-SLAM2是不同的。在ORB-SLAM2的後端中,我們會不停地重構整個優化問題,求解,然後儲存優化後的結果,但這個H矩陣是不會一直存在的。而在DSO中,由於H是一直維護的,所以之後的優化可以利用先前的結果,或者說,先前的優化為下一步提供了先驗(Prior)。但是,為了維護這個H資訊,DSO必須手動地增加/刪除每一個幀和點,而不像ORB-SLAM2那樣,可以無視幀和點的變化。
我們知道,H實際上有一個特殊的形狀(箭頭形矩陣,Arrow-like Matrix)[1,7,9],如下圖所示:
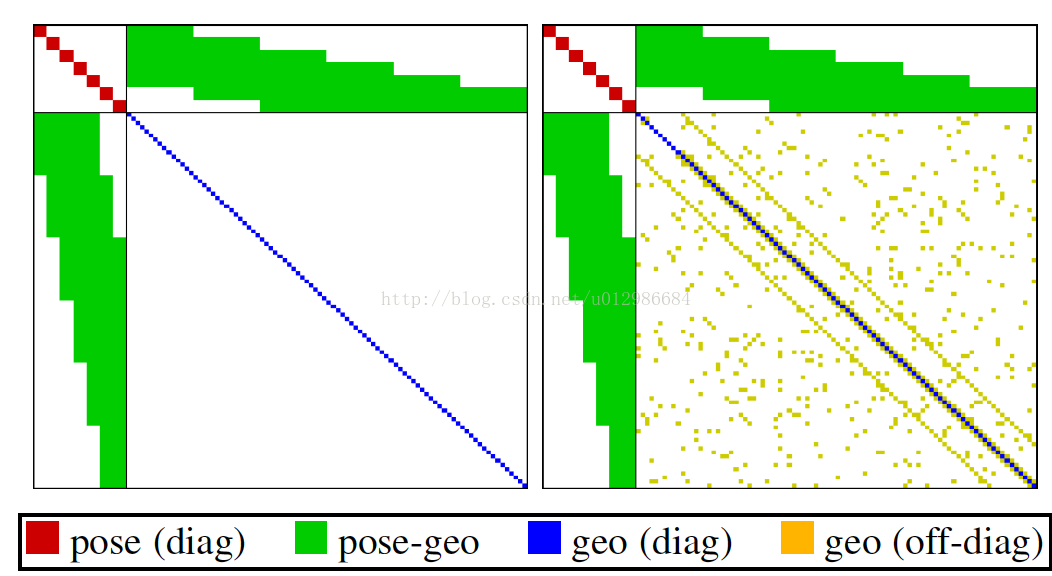
眾所周知,這個形狀是由BA本身的結構導致的。把它的分塊記為:
那麼右下角的 是一個對角塊矩陣(因為沒有結構的先驗,即點——點的殘差)。塊的大小取決於地圖點的引數化維度,在DSO中是一維,在ORB-SLAM2中是三維。接下來,在傳統BA中(類似於ORB-SLAM2)的做法是這樣的:
- 通過圖優化構建這個H;
- 用高斯消元法(即舒爾補)將右下角部分消元:
即:
- 此時方程解耦,於是先解左上部分(維度很小);再用左上部分的結果解右下部分。
這個過程也稱為邊緣化(Marginalization),此時我們邊緣化掉了所有的點,將他們的資訊歸到了位姿部分中,形成了相機位姿部分的先驗。這部分知識,對於每位SLAM研究者來說應當是熟知的。
那麼在DSO中,有哪些地方用了邊緣化?
首先,DSO的BA,也和傳統BA一樣,有上述步驟。因此DSO在解BA時,邊緣化了所有點的資訊,計算優化的更新量。然而,與傳統BA不同的是,DSO的左上角部分,即公式中的
,並非為對角塊,而是有先驗的。傳統BA中,這部分為對角塊,主要原因是不知道相機運動的先驗,而DSO的滑動視窗,則通過一定手段計算了這個先驗。這裡的先驗主要來自兩個部分:
- 邊緣化某個點時,這個點的共視幀之間產生先驗;
- 邊緣化某個幀時,在視窗內其他幀之間產生先驗;
這裡的“邊緣化”,具體的操作和上面講的邊緣化,是一樣的。也就是說,通過舒爾補,用矩陣的一部分去消元另一部分。然而實際操作的含義卻有所不同。在BA的邊緣化中,我們希望用邊緣化加速整個問題的求解,但是解完問題後,這些幀和點仍舊是存在於視窗中的!而滑動視窗中的邊緣化,是指我們不再需要這個點/這個幀。當它被邊緣化時,我們將它的資訊傳遞到了之後的先驗中,而不會再利用這個點/這個幀了!請讀者務必理清這層區別,否則在理解過程中會遇到問題。我們不妨將後者稱為“永久邊緣化”,以示區分。
那麼DSO如何永久邊緣化某個幀或點?它遵循以下幾個準則:
- 如果一個點已經不在相機視野內,就邊緣化這個點;
- 如果滑動視窗內的幀數量已經超過設定閾值,那麼選擇其中一個幀進行邊緣化;
- 當某個幀被邊緣化時,以它為主導的地圖點將被移除,不再參與以後的計算。否則這個點將與其他點形成結構先驗,破壞BA中的稀疏結構[10]。
在邊緣化的過程,DSO維護了幀與幀間的先驗資訊(見EnergyFunctional::HM和bM),並將這些資訊利用到BA的求解中去。
3.3 零空間,FEJ
在SLAM中,GN或LM優化過程中,狀態變數事實上是存在零空間(nullspace)的。所謂零空間,就是說,如果在這個子空間內改變狀態變數的值,不會影響到優化的目標函式取值。在純視覺SLAM中,典型的零空間就是場景的絕對尺度,以及相機的絕對位姿。可以想象,如果將相機和地圖同時擴大一個尺度,或者同時作一次旋轉和平移,整個目標函式應該不發生改變。零空間的存在也會導致在優化過程中,線性方程的解不唯一。儘管每次迭代的步長都很小,但是時間長了,也容易讓整個系統在這個零空間中游蕩,令尺度發生漂移。
另一方面,由於邊緣化的存在,如果一個點被邊緣化,那它的雅可比等矩陣就要被固定於被邊緣化之時刻,而其他點的雅可比還會隨著時間更新,就使得整個系統中不同變數被線性化的時刻是不同的。這會導致零空間的降維——本應存在的零空間,由於線性化時刻的不同,反而消失了!而我們的估計也會變得過於樂觀。
DSO作者提出了一個很好的例子以展現這件事情。見下圖。
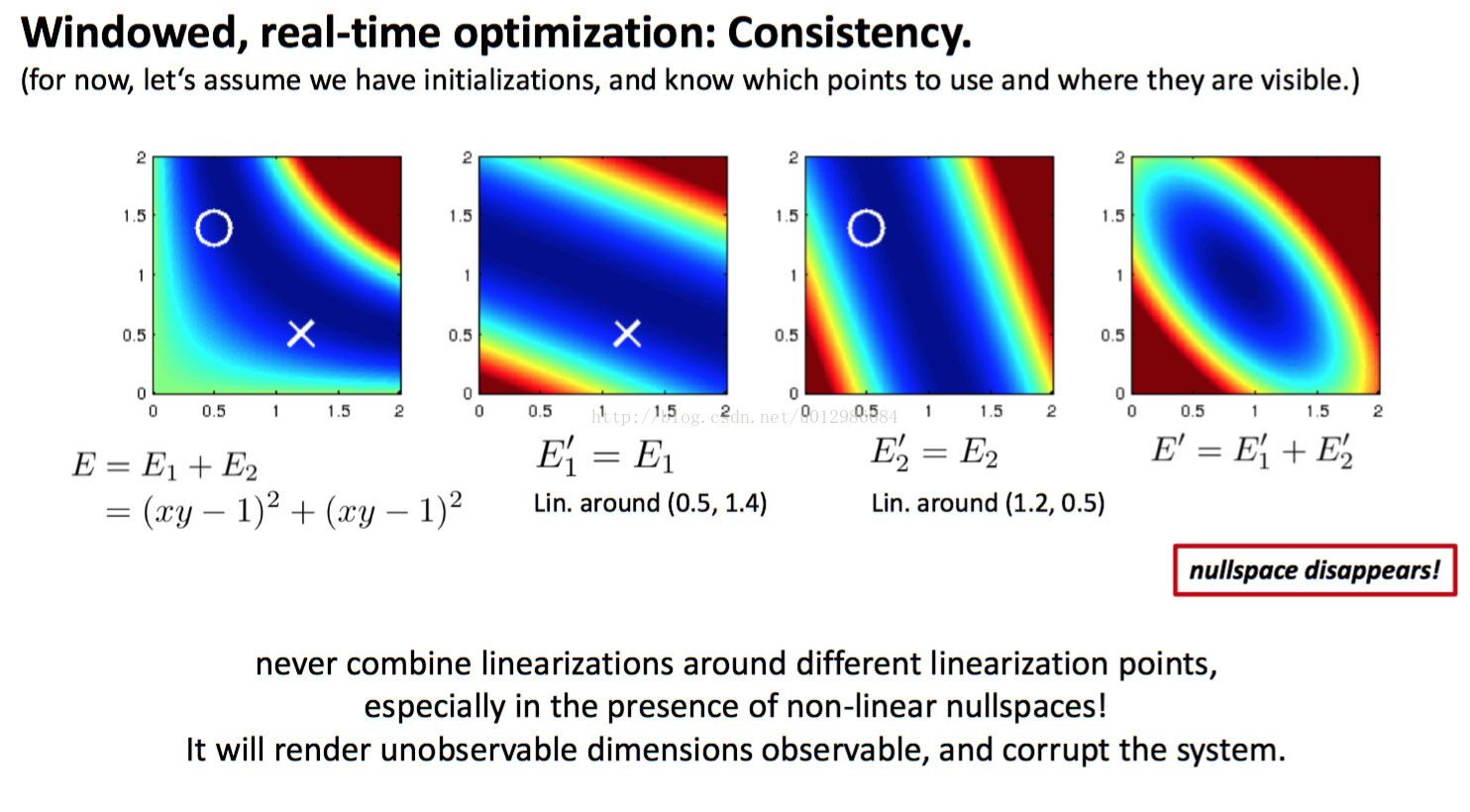
在這個例子中,我們最小化
,那麼顯然
這條曲線就是優化問題的最優解,正好是一維的零空間。但是,如果
和
在不同點上線性化,那麼求得的
可能會讓這一維的零空間消失(如圖例),這時最優解變成了一個點。
因此,在DSO實際使用時,僅在優化的初始時刻計算幾何和光度的雅可比,並讓它們在隨後的迭代過程中保持不變,即First-Estimate-Jacobian。FEJ強制讓每個點在同一個時刻線性化,從而回避了零空間降維的問題,同時可以降低很多計算量。DSO中的每個地圖點,由前面定義的pattern產生8個殘差項,這些殘差項也會共享FEJ。由於幾何和光度函式都比較光滑,實踐當中FEJ近似是十分好用的。
3.4 其他零散的模組和演算法
除去上述主幹以外,DSO還有一些枝節上的演算法,例如:
- DSO是怎麼初始化的?
- DSO的CoarseTracker如何估計新幀的位姿?
- 未成熟點是如何轉換到正常地圖點的?
(TODO: 待更新)
4. 光度標定(已轉載)
我發現已經有一些文章介紹DSO的光度標定了[11],所以我考慮不再重複介紹一遍了。如果需要的話我會補上。
5. 評述
DSO的出現將直接法推進到一個相當成熟可用的地位,許多實驗已表明它的精度與魯棒性均優於現在的ORB-SLAM2,而相比之下LSD-SLAM則顯然沒有那麼成熟。在我自己的實物相機實驗中,我發現LSD-SLAM很難一次上手即通,而DSO則魯棒的多。
在大部分資料集上,DSO均有較好的表現。雖然DSO要求全域性曝光相機,但即使是捲簾快門的相機,只要運動不快,模糊不明顯,DSO也能順利工作。但是,如果出現明顯的模糊、失真,DSO也會丟失。
我認為,直接法相比傳統特徵點法,最大的貢獻在於,直接法以更整體、更優雅的方式處理了資料關聯問題。特徵點法需要依賴重複性較強的特徵提取器,以及正確的特徵匹配,才能得正確地計算相機運動。在環境紋理較好,角點較多時,這當然是可行的——不過直接法在這種環境下也能正常工作。然而,如果環境中出現了下列情況,對特徵點法就不那麼友善:
- 環境中存在許多重複紋理;
- 環境中缺乏角點,出現許多邊緣或光線變數不明顯區域;
這在實際影象中很常見,我們以道路環境為例(取自kitti):

顯然,路面上角點甚少,僅有車道線的起始/終止處存在角點,其他地方紋理不足;天空通常也沒有紋理;路旁欄杆和障礙物重複紋理非常明顯。這些都是特徵點法必須面對的問題,所以特徵點法通常只能依賴一些車輛、行人、交通告示板來確定明顯的特徵匹配,這會影響整個SLAM系統的穩定性。其根本原因在於:無法找到有用的匹配點、或者容易找到錯誤的匹配點。例如,車道線邊緣上的點外觀都非常相似,欄杆附近的點則由於欄杆本身紋理重複,容易出現錯配。
而直接法,如前所示,則並不要求一一對應的匹配。只要先前的點在當前影象當中具有合理的投影殘差,我們就認為這次投影是成功的。而成功與否,主要取決於我們對地圖點深度以及相機位姿的判斷,並不在於影象區域性看起來是什麼樣子。舉個例子,如果用特徵法或光流法追蹤某個位於邊緣的畫素,由於沿著邊緣方向影象區域性很相似,所以這個匹配或追蹤的結果,可能被計算成此邊緣方向的另一個點——這主要是因為影象區域性的相似性;而直接法的約束則來自更為整體的相機位姿,所以即使單個點無法給出足夠的資訊,還可以靠其他點來修正它的投影關係,從而找到正確的投影點。
這是一把雙刃劍。直接法給予我們追蹤邊緣、平滑區塊的能力,但同時也要付出代價——正確的直接法追蹤需要有一個相當不錯的初始估計,還需要一個質量較好的影象。由於DSO嚴重依賴於使用梯度下降的優化問題求解,而它成功的前提,是目標函式從初始值到最優值之間一直是下降的。在影象質量不佳或者相機初始位姿給的不對的情況下,這件事情往往無法得到保證,所以DSO也會丟失。
這種做法一個顯而易見的後果是,除非儲存所有的關鍵幀影象,否則很難利用先前建好的地圖。退一步說,即使有辦法儲存所有關鍵幀的影象,那麼在重用地圖時,我們還需要對位姿有一個比較準確的初始估計——這通常是困難的,因為你不知道誤差已經累計到了多大的程度。而在特徵點法中,地圖重用則相對簡單。我們只需儲存空間中所有的特徵點和它們的特徵描述,然後匹配當前影象中看到的特徵,計算位姿即可。
我們看到,資料關聯和位姿估計,在直接法中是耦合的,而在特徵點法中則是解耦的。耦合的好處,在於能夠更整體性地處理資料關聯;而解耦的好處,在於能夠在位姿不確定的情況下,僅利用影象資訊去解資料關聯問題。所以直接法理應更擅長求解連續影象的定位,而特徵點法則更適和全域性的匹配與迴環檢測。讀者應該明瞭二者優缺點的來由。
當然DSO也不是萬能的。最容易看到的缺點,就是它不是個完整的SLAM——它沒有迴環檢測、地圖重用、丟失後的重定位,而這些在實際場景中往往又是必不可少的功能。DSO的初始化部分也比較慢,當然雙目或RGBD相機會容易很多。如果你想要拓展DSO的功能,首先你需要十分了解DSO的程式碼結構。希望本文能夠起到一定的作用。
資料與參考文獻:
[1]. Engel J, Koltun V, Cremers D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[2]. Forster, C.; Pizzoli, M. & Scaramuzza, D., SVO: Fast semi-direct monocular visual odometry,Robotics and Automation (ICRA), 2014 IEEE International Conference on,2014, 15-22.
[3]. Mur-Artal, R.; Montiel, J. & Tardós, J. D. ORB-slam: a versatile and accurate monocular slam system,IEEE Transactions on Robotics, IEEE,2015, 31, 1147-1163.
[4]. Bowman, S. L.; Atanasov, N.; Daniilidis, K. & Pappas, G. J. Probabilistic data association for semantic SLAMRobotics and Automation (ICRA), 2017 IEEE International Conference on,2017, 1722-1729.
[5]. Civera, J.; Davison, A. J. & Montiel, J. M. Inverse depth parametrization for monocular SLAM,IEEE transactions on robotics, IEEE,2008, 24, 932-945.
[6]. Engel, J.; Sturm, J. & Cremers, D. Semi-dense visual odometry for a monocular cameraProceedings of the IEEE international conference on computer vision,2013, 1449-1456
[7]. 高翔, 張濤, 劉毅, 顏沁睿, 視覺SLAM十四講:從理論與實踐,電子工業出版社, 2017
[8]. Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R. & Furgale, P. Keyframe-based visual-inertial odometry using nonlinear optimizationINTERNATIONAL JOURNAL OF ROBOTICS RESEARCH,2015, 34:314-334
[9]. Barfoot, T. State Estimation for Robotics: A Matrix Lie Group Approach,Cambridge University Press,2017
[12]高翔,知乎:半閒居士
[13]dso詳解 :https://zhuanlan.zhihu.com/p/29177540