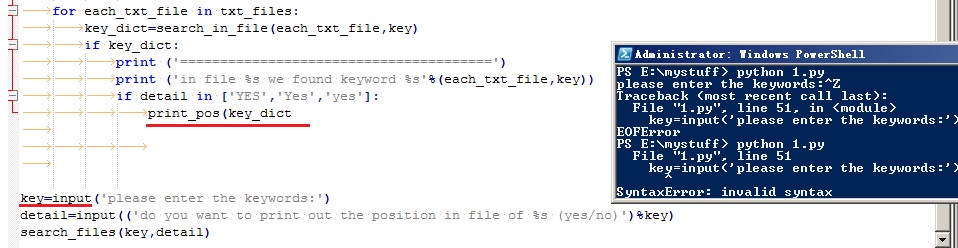
Python 小甲魚教程 課後練習30 番外篇_需要謹記!!!
這題的要求是搜尋當前目錄內,包含所輸入關鍵字的txt檔案,並標註出,是在檔案的第幾行,和第幾個位置
這道題目中,碰到了好幾個基礎知識缺失的地方,以及後期除錯中莫名其妙的報錯,經過一個上午的糾結,找到了報錯真實位置,並看到一些規律,這裡記錄下。
程式碼如下:
import os
def print_pos(key_dict):
keys = key_dict.keys() #這裡是將字典裡的鍵值迭代出來,注意,keys()函式返回的是一個dict_keys的型別,類似於list,可以被迭代!!
keys = sorted(keys) #由於字典是無序的,出來的數字我們要排序一下
for each_key in keys:
print ('keyword is in %s line, %s position'%(each_key,str(key_dict[each_key]))) #這裡有一個巨型坑,這句話的最後一個括號,我一開始漏了,但是執行時候報
#我在文末最後寫一點東西,記錄一下這個錯誤,太糟心了。
def pos_in_line(line, key):
pos = []
begin = line.find(key) #find函式
while begin != -1: #這句話的意思是,當找到匹配值時
pos.append(begin + 1) #將這個位置新增到列表裡去(然後python的索引是從0開始,但是對使用者來說,是從1開始)
begin = line.find(key, begin+1) #這句很關鍵,在上一個索引返回後,繼續從下一個開始搜尋匹配
return pos
def search_in_file(file_name,key): #我覺得第二個要寫的部分是這裡,搜尋行數
f=open(file_name)
count=0 #計數器初始化為0
key_dict=dict()
for each_line in f:
count+=1 #後面每搜尋一行,計數器count就自己加1
if key in each_line:
pos = pos_in_line(each_line,key) #呼叫pos_in_line函式,巢狀好多次啊,太複雜了.......
key_dict[count]=pos #這裡嚴重筆記!如果一行內出現多次關鍵字,那不是字典內一個key要對應好幾個value嗎?請記住!!!key是可以對應列表 #list的,所以,這裡是把一個count,也就是行數,對應一個列表,在列表內部,才是出現的具體位置
f.close()
return key_dict
def search_files(key,detail): #最先寫的應該是這部分,因為你首先是定位到,哪些是txt文件,然後再進入內部搜尋.
all_files=os.walk(os.getcwd()) #os.walk函式,歷遍當前目錄和子目錄,返回三個物件,1:str形式的當前目錄,2:list形式的資料夾目錄,3:list形式的檔案目錄
txt_files=[]
for i in all_files:
for each_file in i[2]: #將當前目錄內的所有檔案迭代出來
if os.path.splitext(each_file)[1]=='.txt': #分割字尾名和檔案,如果字尾為.txt
each_file=os.path.join(i[0],each_file) #更新each_file這個變數,他原來只是檔名,現在通過join函式拼接,成為完成路徑名
txt_files.append(each_file)
for each_txt_file in txt_files:
key_dict=search_in_file(each_txt_file,key) #這裡呼叫下一個函式search_in_file
if key_dict: #這裡的意思是,如果在key_dict裡面有值,那麼就列印一行===,並繼續列印具體檔案路徑和關鍵字
print ('=======================================')
print ('in file %s we found keyword %s'%(each_txt_file,key))
if detail in ['YES','Yes','yes']:
print_pos(key_dict) #這裡呼叫另外一個函式,列印具體位置,我覺得寫程式碼的時候肯定是先在這做一個伏筆,等後續上面的函式寫完, #再來替換的
key=input('please enter the keywords:')
detail=input(('do you want to print out the position in file of %s (yes/no)')%key)
search_files(key,detail)
最後的最後,新增一下上面碰到的天坑錯誤和自己做的試驗
看到下面的報錯了嗎?我找了2小時,沒明白這個def語句這一行有什麼錯誤,包括縮排什麼的,都沒問題,找到最後,結果發現是上面一行的print語句最後一個括號給漏了
但是他給我報錯報在下一行!!!
然後,見圖2,我做了個試驗,在其他程式碼裡,只要最後一句是print,漏了右邊括號的話,他就會自動報錯報在下面一行的開頭。。。。WTF

牢記錯誤。。。。。。。。。。