
Pandas模組入門(一)——Series結構介紹
阿新 • • 發佈:2019-02-03
Pandas模組是Python用於資料匯入及整理的模組,對資料探勘前期資料的處理工作十分有用,因此這些基礎的東西還是要好好的學學。
Pandas模組的資料結構主要有兩:1、Series ;2、DataFrame
這次就先了解一下Series結構。
1. 介紹
The Series is the primary building block of pandas and represents a one-dimensional labeled array based on the NumPy ndarray;(從書上搬來的,逃~) 大概就是說Series結構是基於NumPy的ndarray結構,是一個一維的標籤矩陣(感覺跟python裡的字典結構有點像)
2. 相關操作
a.建立
a.1、pd.Series([list],index=[list])//以list為引數,引數為一list;index為可選引數,若不填則預設index從0開始;若添則index長度與value長度相等
import pandas as pd
s=pd.Series([1,2,3,4,5],index=['a','b','c','f','e'])
print s
a.2、pd.Series({dict})//以一字典結構為引數
import pandas as pd
s=pd.Series({'a':3,'b':4,'c':5,'f':6,'e':8})
print 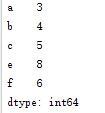
b.取值
s[index] or s[[index的list]]
取值操作類似陣列,當取不連續的多個值時可以以一list為引數
import pandas as pd
import numpy as np
v=np.random.random_sample(50)
s=pd.Series(v)
s1=s[[3,7,33]]
s2=s[1:5]
s3=s[49]
print "s1\n",s1
print "s2\n",s2
print "s3\n",s3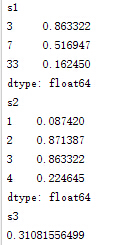
c..head(n);.tail(n)//取出頭n行或尾n行,n為可選引數,若不填預設5
v=np.random 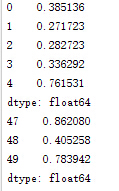
d、.index; .values//取出index 與values ,返回list
e、Size、shape、uniqueness、counts of values
v=[10,3,2,2,np.nan]
v=pd.Series(v);
print "len():",len(v)#Series長度,包括NaN
print "shape():",np.shape(v)#矩陣形狀,(,)
print "count():",v.count()#Series長度,不包括NaN
print "unique():",v.unique()#出現不重複values值
print "value_counts():\n",v.value_counts()#統計value值出現次數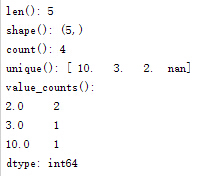
f.加運算
相同index的value相加,若index並非共有的則該index對應value變為NaN
import pandas as pd
s1=pd.Series([1,2,3,4],index=[1,2,3,4])
s2=pd.Series([1,1,1,1])
s3=s1+s2
print s3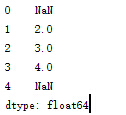
<原創文章,轉載請註明出處>