
mysql 查詢兩表使用join on和使用子查詢in的比較
阿新 • • 發佈:2019-02-03
有兩個表
promotion_full_reduction
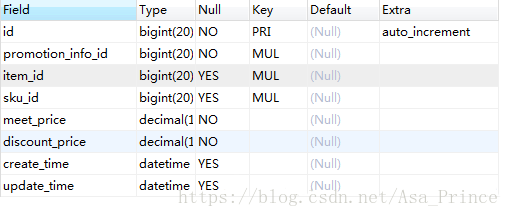
base_user_favorite_item
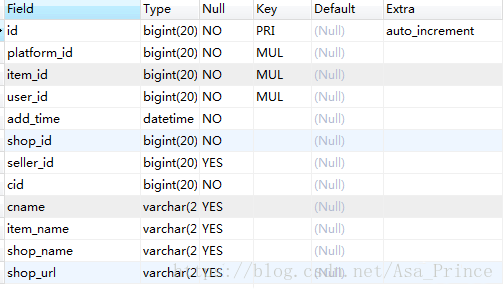
現在要查詢使用者收藏的商品中參加促銷了的商品個數,有兩種寫法,一種是使用in子查詢:
SELECT COUNT(1) FROM promotion_full_reduction fr WHERE fr.item_id IN ( SELECT ufi.item_id FROM base_user_favorite_item ufi WHERE ufi.platform_id = 222 AND ufi.user_id = 111 )
使用 explain 檢視mysql執行計劃:

此sql以promotion_full_reduction 為驅動表,雖然執行計劃顯示走了索引,但是由於外層查詢沒有where條件(因為子查詢還未執行),結果就是將promotion_full_reduction 全表資料都掃描了出來load到了記憶體,然後進行nested loop,迴圈執行子查詢,根據子查詢結果對外層查詢結果進行過濾,總共要迴圈99次(子查詢到底是讀99次磁碟還是隻讀一次這個我不確定,希望瞭解的人解釋一下)。
再看使用兩表關聯進行查詢:
SELECT count(1) FROM promotion_full_reduction pr JOIN base_user_favorite_item bi ON pr.item_id = bi.item_id WHERE bi.user_id = 111 AND bi.platform_id = 2222
使用 explain 檢視mysql執行計劃:

執行計劃顯示mysql選擇了 base_user_favorite_item 作為驅動表,由於帶有where條件,驅動表查詢出來的結果只有兩條,顯然磁碟io次數少了,nested loop迴圈次數也降了下來。
結論:不要輕易使用in子查詢,由於in子查詢總是以外層查詢的table作為驅動表,所以如果想用in子查詢的話,一定要將外層查詢的結果集降下來,降低io次數,降低nested loop迴圈次數,即:永遠用小結果集驅動大的結果集。