
Python Django Celery 實現非同步任務(二)使用rabbitmq 作為broker
之前在上一篇文章中Python Celery 實現非同步任務是使用Django預設作為borker (訊息分發),因為升級最新的celery後,不再支援Django作為borker ,所以測試平臺更換為rabbitmq 。以下簡單介紹下更換的方法,其實很簡單。
在django 專案下,把全域性的settings.py 中修改以下程式碼
# 使用rabbitmq 作為任務代理 (broker)
BROKER_URL = "amqp://"
# 預設是以本機的mq服務作為broker。如果你需要配置成遠端的mq,請填寫完整的
BROKER_URL = amqp://userid:password@hostname:port/virtual_host rabbitmq 的安裝方法,網上有很多,請Google後安裝,並且啟動mq 服務。
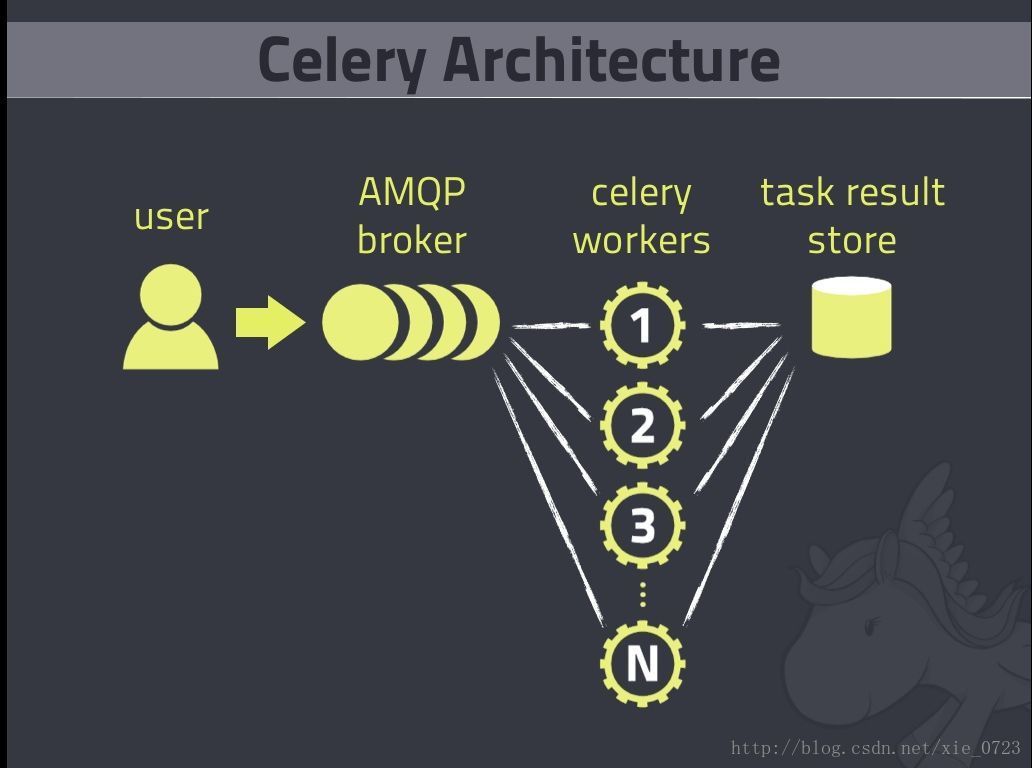
結構圖
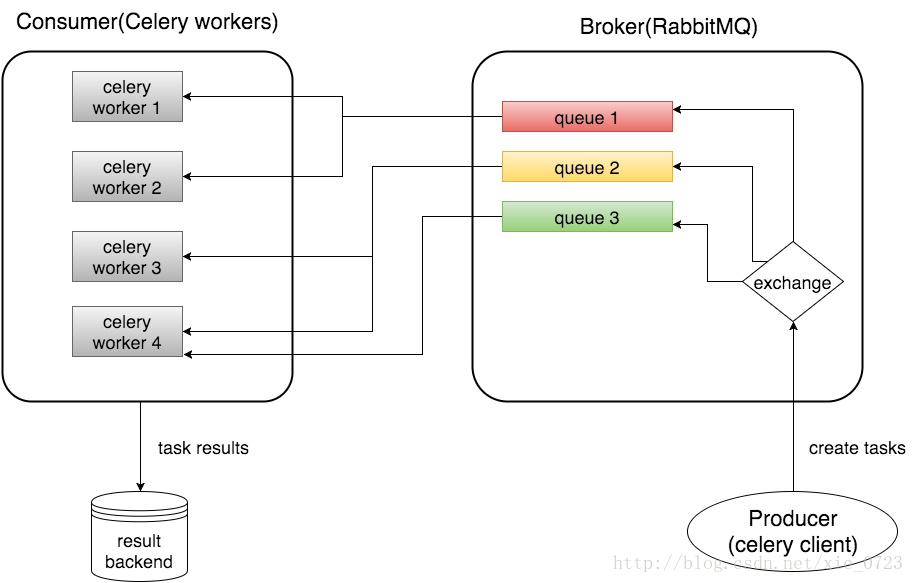
celey 結構
相關推薦
Python Django Celery 實現非同步任務(二)使用rabbitmq 作為broker
之前在上一篇文章中Python Celery 實現非同步任務是使用Django預設作為borker (訊息分發),因為升級最新的celery後,不再支援Django作為borker ,所以測試平臺更換為
ASP.NET Core 3.x啟動時執行非同步任務(二)
這一篇是接著前一篇在寫的。如果沒有看過前一篇文章,建議先去看一下前一篇,這兒是傳送門 一、前言 前一篇文章,我們從應用啟動時非同步執行任務開始,說到了必要性,也說到了幾種解決方法,及各自的優缺點。最後,還提出了一個比較合理的解決方法:通過在Program.cs里加入程式碼,來實現IWebHost啟動
Python--Django使用celery實現非同步任務
Django使用celery實現非同步任務 celery使用: 以傳送簡訊為例 在專案目錄下下建立celery_tasks用於儲存celery非同步任務。 在celery_tasks目錄下建立config.py檔案,用於儲存celery的配置資訊 # redi
Django 使用 Celery 實現非同步任務
對於網站來說,給使用者一個較好的體驗是很重要的事情,其中最重要的指標就是網站的瀏覽速度。因此服務端要從各個方面對網站效能進行優化,比如可採用CDN載入一些公共靜態檔案,如js和css;合併css或者js從而減少靜態檔案的請求等等…..還有一種方法是將一些不需要立即返回給使用者,
django —— Celery實現非同步和定時任務
1. 環境 python==2.7 djang==1.11.2 # 1.8, 1.9, 1.10應該都沒問題 celery-with-redis==3.0 # 需要用到redis作為中間人
Flask + Ajax + Mysql 實現網頁非同步載入(二)
Flask + Ajax + Mysql 實現網頁非同步載入(一) 二、jquery 和Ajax 實現前端請求 <script src="static/js/jquery.min.js" > </script> <script type="text/java
[Python] 利用Django進行Web開發系列(二)
回到頂部 1 編寫第一個靜態頁面——Hello world頁面 Step1:建立檢視檔案 在編寫第一個頁面之前,我們首先要在mysite目錄下建立一個名稱為views.py的檔案。當然,命名是沒有要求的,你也可以命名為a.py,b.py...
flask中celery介紹及使用celery實現非同步任務
Celery簡介 除Celery是一個非同步任務的排程工具。 Celery 是 Distributed Task Queue,分散式任務佇列,分散式決定了可以有多個 worker 的存在,隊列表示其是非同步操作,即存在一個產生任務提出需求的工頭,和一群等著
Django中使用django-celery完成非同步任務(1)
許多Django應用需要執行非同步任務, 以便不耽誤http request的執行. 我們也可以選擇許多方法來完成非同步任務, 使用Celery是一個比較好的選擇, 因為Celery有著大量的社群支援, 能夠完美的擴充套件, 和Django結合的也很好. Cel
django+celery實現非同步訊息佇列
步驟:1. 建立專案 django-admin startproject project2. 建立apppython manage.py startapp sendemail3. 配置settings.pyDEBUG = False ALLOWED_HOSTS = ['12
Django-CRM項目學習(二)-模仿admin實現stark
sco auto add 有一個 分享圖片 loading nbsp als -i 開始今日份整理 1.stark模塊基本操作 1.1 stark模塊的啟動 保證django自動的加載每一個app下的stark.py文件 創建django項目,創建stark項目
Vue結合Django-Rest-Frameword結合實現登入認證(二)
>作者:小土豆biubiubiu > >部落格園:https://www.cnblogs.com/HouJiao/ > >掘金:https://juejin.im/user/2436173500265335 > > >微信公眾號:土豆媽的碎碎念(掃碼關注,一起吸貓,一起聽故事,一起學習前端技術)
python基礎-------進程線程(二)
lob size 擁有 利用 oba tar 優點 port pre Python中的進程線程(二) 一、python中的“鎖” 1.GIL鎖(全局解釋鎖) 含義: Python中的線程是操作系統的原生線程,Python虛擬機使用一個全局解釋器鎖(Global Inte
python 命令行參數學習(二)
Coding odi increase logs 說明 code des urn 數學 照著例子看看打打,碼了就會。寫了個命令行參數調用進行運算的腳本。 參考文章鏈接:http://www.jianshu.com/p/a50aead61319 #-*-coding:utf
Spark轉GemFire任務(二)
rip spec parent region turn source desc 6.2 include ADMG-2.2.1.3 - BRAVO CoA Mapping - TB Revision 7/11: If Bravo code is not numeric,
Python Selenium 文件上傳(二)
rip info python 拼接 type 項目 shee editor 可執行文件 今天補充一種文件上傳的方法 主要是因為工作中使用SendKeys方法不穩定,具體方法見: Python Selenium 文件上傳(一) 這種方法直接通過命令行執行腳
Python WebDriver 文件上傳(二)
html 默認 定位 com http 圖形用戶界面 網站 如果 應用 今天補充一種文件上傳的方法 主要是因為工作中使用SendKeys方法不穩定,具體方法見: Python WebDriver 文件上傳(一) 這種方法直接通過命令行執行腳本時沒有問題,可以成功上
Python爬蟲框架Scrapy實例(二)
head sports spi 工作目錄 http 鏈接 進入 效果 tex 目標任務:使用Scrapy框架爬取新浪網導航頁所有大類、小類、小類裏的子鏈接、以及子鏈接頁面的新聞內容,最後保存到本地。 大類小類如下圖所示: 點擊國內這個小類,進入頁面後效果如下圖(部分截圖)
Android進階筆記:AIDL內部實現詳解 (二)
ucc == 筆記 null stack 直接 android 最好 public 接著上一篇分析的aidl的流程解析。知道了aidl主要就是利用Ibinder來實現跨進程通信的。既然是通過對Binder各種方法的封裝,那也可以不使用aidl自己通過Binder來實現跨進
python基本數據類型(二)-python3.0學習筆記
tin 基本數據 abcde 返回 屬性方法 mat sizeof 不可變 map python基本數據類型 序列類型的自帶方法 1.列表的常用方法 2.元祖的常用方法 3.字符串的常用方法 1.列表常用的方法 L.append(obj) #在列表末尾添加新的對