
Java併發程式設計(四)Java記憶體模型
前言
此前我們講到了執行緒、同步以及volatile關鍵字,對於Java的併發程式設計我們有必要了解下Java的記憶體模型,因為Java執行緒之間的通訊對於工程師來言是完全透明的,記憶體可見性問題很容易使工程師們覺得困惑,這篇文章我們來主要的講下Java記憶體模型的相關概念。
1.共享記憶體和訊息傳遞
執行緒之間的通訊機制有兩種:共享記憶體和訊息傳遞;在共享記憶體的併發模型裡,執行緒之間共享程式的公共狀態,執行緒之間通過寫-讀記憶體中的公共狀態來隱式進行通訊。在訊息傳遞的併發模型裡,執行緒之間沒有公共狀態,執行緒之間必須通過明確的傳送訊息來顯式進行通訊。
同步是指程式用於控制不同執行緒之間操作發生相對順序的機制。在共享記憶體併發模型裡,同步是顯式進行的。工程師必須顯式指定某個方法或某段程式碼需要線上程之間互斥執行。在訊息傳遞的併發模型裡,由於訊息的傳送必須在訊息的接收之前,因此同步是隱式進行的。
Java的併發採用的是共享記憶體模型,Java執行緒之間的通訊總是隱式進行,整個通訊過程對工程師完全透明。
2.Java記憶體模型的抽象
在java中,所有例項域、靜態域和陣列元素儲存在堆記憶體中,堆記憶體線上程之間共享(本文使用“共享變數”這個術語代指例項域,靜態域和陣列元素)。區域性變數,方法定義引數和異常處理器引數不會線上程之間共享,它們不會有記憶體可見性問題,也不受記憶體模型的影響。
Java執行緒之間的通訊由Java記憶體模型(本文簡稱為JMM)控制,JMM決定一個執行緒對共享變數的寫入何時對另一個執行緒可見。從抽象的角度來看,JMM定義了執行緒和主記憶體之間的抽象關係:執行緒之間的共享變數儲存在主記憶體中,每個執行緒都有一個私有的本地記憶體,本地記憶體中儲存了該執行緒以讀/寫共享變數的副本。本地記憶體是JMM的一個抽象概念,並不真實存在。它涵蓋了快取,寫緩衝區,暫存器以及其他的硬體和編譯器優化。Java記憶體模型的抽象示意圖如下:
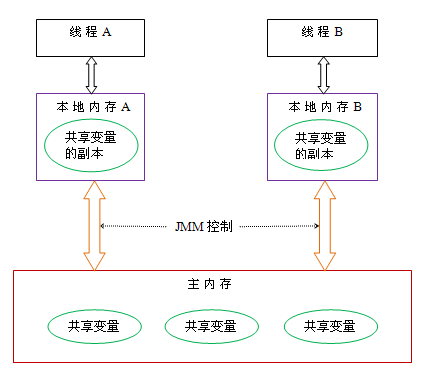
從上圖來看,執行緒A與執行緒B之間如要通訊的話,必須要經歷下面2個步驟:
- 執行緒A把本地記憶體A中更新過的共享變數重新整理到主記憶體中去。
- 執行緒B到主記憶體中去讀取執行緒A之前已更新過的共享變數。
3.從原始碼到指令序列的重排序
在執行程式時為了提高效能,編譯器和處理器常常會對指令做重排序。重排序分三種類型:
- 編譯器優化的重排序。編譯器在不改變單執行緒程式語義的前提下,可以重新安排語句的執行順序。
- 指令級並行的重排序。現代處理器採用了指令級並行技術來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序。
- 記憶體系統的重排序。由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。
從java原始碼到最終實際執行的指令序列,會分別經歷下面三種重排序:

上述的1屬於編譯器重排序,2和3屬於處理器重排序。這些重排序都可能會導致多執行緒程式出現記憶體可見性問題。對於編譯器,JMM的編譯器重排序規則會禁止特定型別的編譯器重排序(不是所有的編譯器重排序都要禁止)。對於處理器重排序,JMM的處理器重排序規則會要求java編譯器在生成指令序列時,插入特定型別的記憶體屏障指令,通過記憶體屏障指令來禁止特定型別的處理器重排序(不是所有的處理器重排序都要禁止)。
JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
4.happens-before簡介
happens-before是JMM最核心的概念,對於Java工程師來說,理解happens-before是理解JMM的關鍵。
JMM的設計意圖
在設計JMM需要考慮兩個關鍵因素:
- 工程師對記憶體模型的使用,希望記憶體模型易於理解和程式設計,工程師希望基於一個強記憶體模型來編寫程式碼。
- 編譯器和處理器對記憶體的實現,希望記憶體模型對他們的束縛越少越好,編譯器和處理器希望實現一個弱記憶體模型。
這兩個因素是互相矛盾的,所以JSR-133專家組設計時需要考慮到一個好的平衡點:一方面為工程師提供足夠強的記憶體可見性,另一方面要對編譯器和處理器的限制要儘量鬆些。
我們來舉了例子:
int a=10; //A
int b=20; //B
int c=a*b; //C上面是一個簡單的乘法運算,並存在3個happens-before關係:
- A happens-before B
- B happens-before C
- A happens-before C
這三個happens-before關係中,2和3是必須的,但1是不必要的。因此,JMM把happens-before要求禁止的重排序分為兩類:
- 會改變程式執行結果的重排序。
- 不會改變程式執行結果的重排序。
JMM對這兩種不同性質的重排序,採取了不同的策略:
- 對於會改變程式執行結果的重排序,JMM要求編譯器和處理器必須禁止這種重排序。
- 對於不會改變程式執行結果的重排序,JMM要求編譯器和處理器不做要求,可以允許這種重排序。
happens-before的定義與規則
JSR-133使用happens-before的概念來指定兩個操作之間的執行順序,由於這兩個操作可以在一個執行緒內,也可以在不同的執行緒之間。因此,JMM可以通過happens-before關係向工程師提供跨執行緒的記憶體可見性保證。
happens-before規則如下:
1. 程式順序規則:一個執行緒中的每個操作,happens- before 於該執行緒中的任意後續操作。
2. 監視器鎖規則:對一個監視器鎖的解鎖,happens- before 於隨後對這個監視器鎖的加鎖。
3. volatile變數規則:對一個volatile域的寫,happens- before 於任意後續對這個volatile域的讀。
4. 傳遞性:如果A happens- before B,且B happens- before C,那麼A happens- before
C。
5.順序一致性
順序一致性記憶體模型是一個理論參考模型,在設計的時候,處理器的記憶體模型和程式語言的記憶體模型都會以順序一致性記憶體模型為參考。
資料競爭與順序一致性
當程式未正確同步時,就會存在資料競爭。資料競爭指的是:在一個執行緒中寫一個變數,在另一個執行緒讀同一個變數,而且寫和讀沒有通過同步來排序。
當代碼中包含資料競爭時,程式的執行往往產生違反直覺的結果。如果一個多執行緒程式能正確同步,這個程式將是一個沒有資料競爭的程式。
JMM對正確同步的多執行緒程式的記憶體一致性做了如下保證:
如果程式是正確同步的,程式的執行將具有順序一致性(sequentially consistent),即程式的執行結果與該程式在順序一致性記憶體模型中的執行結果相同。這裡的同步是指廣義上的同步,包括對常用同步原語(synchronized,volatile和final)的正確使用。
順序一致性模型
順序一致性記憶體模型是一個被電腦科學家理想化了的理論參考模型,它為程式設計師提供了極強的記憶體可見性保證。順序一致性記憶體模型有兩大特性:
- 一個執行緒中的所有操作必須按照程式的順序來執行。
- (不管程式是否同步)所有執行緒都只能看到一個單一的操作執行順序。在順序一致性記憶體模型中,每個操作都必須原子執行且立刻對所有執行緒可見。
順序一致性記憶體模型為程式設計師提供的檢視如下:
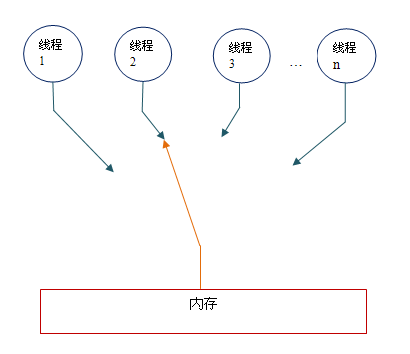
在概念上,順序一致性模型有一個單一的全域性記憶體,這個記憶體通過一個左右擺動的開關可以連線到任意一個執行緒。同時,每一個執行緒必須按程式的順序來執行記憶體讀/寫操作。從上圖我們可以看出,在任意時間點最多隻能有一個執行緒可以連線到記憶體。當多個執行緒併發執行時,圖中的開關裝置能把所有執行緒的所有記憶體讀/寫操作序列化。
順序一致性記憶體模型中的每個操作必須立即對任意執行緒可見,但是在JMM中就沒有這個保證。未同步程式在JMM中不但整體的執行順序是無序的,而且所有執行緒看到的操作執行順序也可能不一致。比如,在當前執行緒把寫過的資料快取在本地記憶體中,且還沒有重新整理到主記憶體之前,這個寫操作僅對當前執行緒可見;從其他執行緒的角度來觀察,會認為這個寫操作根本還沒有被當前執行緒執行。只有當前執行緒把本地記憶體中寫過的資料重新整理到主記憶體之後,這個寫操作才能對其他執行緒可見。在這種情況下,當前執行緒和其它執行緒看到的操作執行順序將不一致。
同步程式的順序一致性
我們接下來看看正確同步的程式如何具有順序一致性。
class SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a;
……
}
}
}上面示例程式碼中,假設A執行緒執行writer()方法後,B執行緒執行reader()方法。這是一個正確同步的多執行緒程式。根據JMM規範,該程式的執行結果將與該程式在順序一致性模型中的執行結果相同。下面是該程式在兩個記憶體模型中的執行時序對比圖:
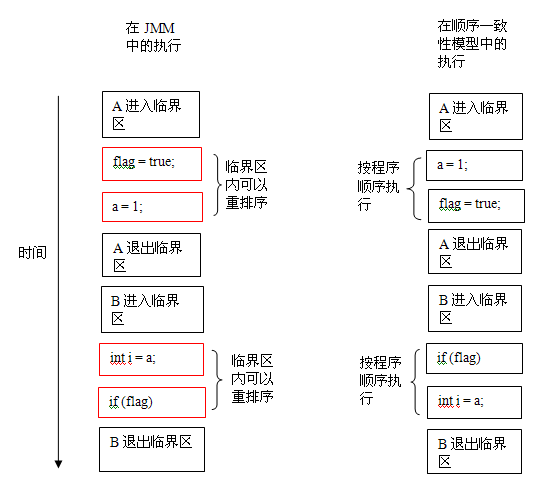
在順序一致性模型中,所有操作完全按程式的順序序列執行。而在JMM中,臨界區內的程式碼可以重排序(但JMM不允許臨界區內的程式碼“逸出”到臨界區之外,那樣會破壞監視器的語義)。JMM會在退出監視器和進入監視器這兩個關鍵時間點做一些特別處理,使得執行緒在這兩個時間點具有與順序一致性模型相同的記憶體檢視。雖然執行緒A在臨界區內做了重排序,但由於監視器的互斥執行的特性,這裡的執行緒B根本無法“觀察”到執行緒A在臨界區內的重排序。這種重排序既提高了執行效率,又沒有改變程式的執行結果。
從這裡我們可以看到JMM在具體實現上的基本方針:在不改變(正確同步的)程式執行結果的前提下,儘可能的為編譯器和處理器的優化開啟方便之門。
未同步程式的順序一致性
JMM不保證未同步程式的執行結果與該程式在順序一致性模型中的執行結果一致。因為未同步程式在順序一致性模型中執行時,整體上是無序的,其執行結果無法預知。保證未同步程式在兩個模型中的執行結果一致毫無意義。
和順序一致性模型一樣,未同步程式在JMM中的執行時,整體上也是無序的,其執行結果也無法預知。
同時,未同步程式在這兩個模型中的執行特性有下面幾個差異:
- 順序一致性模型保證單執行緒內的操作會按程式的順序執行,而JMM不保證單執行緒內的操作會按程式的順序執行(比如上面正確同步的多執行緒程式在臨界區內的重排序)。
- 順序一致性模型保證所有執行緒只能看到一致的操作執行順序,而JMM不保證所有執行緒能看到一致的操作執行順序。
- JMM不保證對64位的long型和double型變數的讀/寫操作具有原子性,而順序一致性模型保證對所有的記憶體讀/寫操作都具有原子性。
對於第三個差異:在一些32位的處理器上,如果要求對64位資料的讀/寫操作具有原子性,會有比較大的開銷。為了照顧這種處理器,java語言規範鼓勵但不強求JVM對64位的long型變數和double型變數的讀/寫具有原子性。當JVM在這種處理器上執行時,會把一個64位long/ double型變數的讀/寫操作拆分為兩個32位的讀/寫操作來執行。這兩個32位的讀/寫操作可能會被分配到不同的匯流排事務中執行,此時對這個64位變數的讀/寫將不具有原子性。
當單個記憶體操作不具有原子性,將可能會產生意想不到後果。請看下面示意圖:
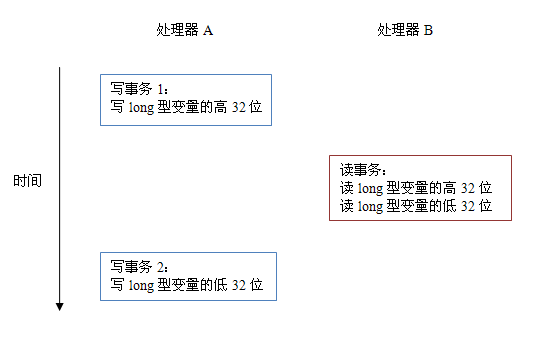
如上圖所示,假設處理器A寫一個long型變數,同時處理器B要讀這個long型變數。處理器A中64位的寫操作被拆分為兩個32位的寫操作,且這兩個32位的寫操作被分配到不同的寫事務中執行。同時處理器B中64位的讀操作被拆分為兩個32位的讀操作,且這兩個32位的讀操作被分配到同一個的讀事務中執行。當處理器A和B按上圖的時序來執行時,處理器B將看到僅僅被處理器A“寫了一半“的無效值。