
深入解析HashMap、ConcurrentHashMap丶HashTable丶ArrayList
Java集合類是個非常重要的知識點,HashMap、HashTable、ConcurrentHashMap等算是集合類中的重點,可謂“重中之重”,首先來看個問題,如面試官問你:HashMap和HashTable有什麼區別,一個比較簡單的回答是:
1、HashMap是非執行緒安全的,HashTable是執行緒安全的。
2、HashMap的鍵和值都允許有null值存在,而HashTable則不行。
3、因為執行緒安全的問題,HashMap效率比HashTable的要高
能答出上面的三點,簡單的面試,算是過了,但是如果再問:Java中的另一個執行緒安全的與HashMap極其類似的類是什麼?同樣是執行緒安全,它與HashTable線上程同步上有什麼不同?能把第二個問題完整的答出來,說明你的基礎算是不錯的了。帶著這個問題深入解HashMap和HashTable類應用而生
一、HashMap的內部儲存結構
Java中資料儲存方式最底層的兩種結構,一種是陣列,另一種就是連結串列,陣列的特點:連續空間,定址迅速,但是在刪除或者新增元素的時候需要有較大幅度的移動,所以查詢速度快,增刪較慢。而連結串列正好相反,由於空間不連續,定址困難,增刪元素只需修改指標,所以查詢慢、增刪快。有沒有一種資料結構來綜合一下陣列和連結串列,以便發揮他們各自的優勢?答案是肯定的!就是:雜湊表。雜湊表具有較快(常量級)的查詢速度,及相對較快的增刪速度,所以很適合在海量資料的環境中使用。一般實現雜湊表的方法採用“拉鍊法”,我們可以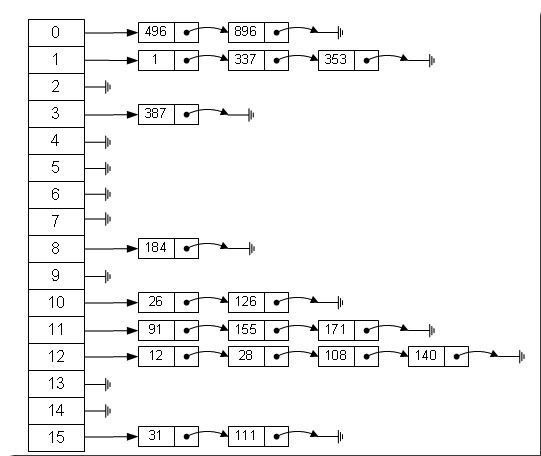
從上圖中,我們可以發現雜湊表是由陣列+連結串列組成的,一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。那麼這些元素是按照什麼樣的規則儲存到陣列中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的雜湊值對陣列長度取模得到。比如上述雜湊表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都儲存在陣列下標為12的位置。它的內部其實是用一個Entity陣列來實現的,屬性有key、value、next。接下來我會從初始化階段詳細的講解HashMap的內部結構。
1、初始化
首先來看三個常量:
static final int DEFAULT_INITIAL_CAPACITY = 16; 初始容量:16
static final int MAXIMUM_CAPACITY = 1
<< 30; 最大容量:2的30次方:1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f;
裝載因子,後面再說它的作用
來看個無參構造方法,也是我們最常用的:
[java] view plain copy
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int - 1
- 2
- 3
- 4
- 5
- 6
- 7
loadFactor、threshold的值在此處沒有起到作用,不過他們在後面的擴容方面會用到,此處只需理解table=new Entry[DEFAULT_INITIAL_CAPACITY].說明,預設就是開闢16個大小的空間。另外一個重要的構造方法:
ublic HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
就是說傳入引數的構造方法,我們把重點放在:while (capacity <
initialCapacity)
capacity <<= 1; - 1
- 2
上面,該程式碼的意思是,實際的開闢的空間要大於傳入的第一個引數的值。舉個例子:
new HashMap(7,0.8),loadFactor為0.8,capacity為7,通過上述程式碼後,capacity的值為:8.(1 << 2的結果是4,2 << 2的結果為8<此處感謝網友wego1234的指正>)。所以,最終capacity的值為8,最後通過new Entry[capacity]來建立大小為capacity的陣列,所以,這種方法最紅取決於capacity的大小。
2、put(Object key,Object value)操作
當呼叫put操作時,首先判斷key是否為null,如下程式碼1處:
<p>public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}</p><p> modCount++;
addEntry(hash, key, value, i);
return null;
}</p>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如果key是null,則呼叫如下程式碼:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
就是說,獲取Entry的第一個元素table[0],並基於第一個元素的next屬性開始遍歷,直到找到key為null的Entry,將其value設定為新的value值。
如果沒有找到key為null的元素,則呼叫如上述程式碼的addEntry(0, null, value, 0);增加一個新的entry,程式碼如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
} - 1
- 2
- 3
- 4
- 5
- 6
先獲取第一個元素table[bucketIndex],傳給e物件,新建一個entry,key為null,value為傳入的value值,next為獲取的e物件。如果容量大於threshold,容量擴大2倍。
如果key不為null,這也是大多數的情況,重新看一下原始碼:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());//---------------2---------------
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//--------------3-----------
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}//-------------------4------------------
modCount++;//----------------5----------
addEntry(hash, key, value, i);-------------6-----------
return null;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
看原始碼中2處,首先會進行key.hashCode()操作,獲取key的雜湊值,hashCode()是Object類的一個方法,為本地方法,內部實現比較複雜,我們
會在後面作單獨的關於Java中Native方法的分析中介紹。hash()的原始碼如下
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
int i = indexFor(hash, table.length);的意思,相當於int i = hash % Entry[].length;得到i後,就是在Entry陣列中的位置,(上述程式碼5和6處是如果Entry陣列中不存在新要增加的元素,則執行5,6處的程式碼,如果存在,即Hash衝突,則執行 3-4處的程式碼,此處HashMap中採用鏈地址法解決Hash衝突。此處經網友bbycszh指正,發現上述陳述有些問題)。重新解釋:其實不管Entry陣列中i位置有無元素,都會去執行5-6處的程式碼,如果沒有,則直接新增,如果有,則將新元素設定為Entry[0],其next指標指向原有物件,即原有物件為Entry[1]。具體方法可以解釋為下面的這段文字:(3-4處的程式碼只是檢查在索引為i的這條鏈上有沒有key重複的,有則替換且返回原值,程式不再去執行5-6處的程式碼,無則無處理)
上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。如, 第一個鍵值對A進來,通過計算其key的hash得到的i=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其i也等於0,現在怎麼辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,i也等於0,那麼C.next = B,Entry[0] = C;這樣我們發現i=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性連結在一起,也就是說陣列中儲存的是最後插入的元素。
到這裡為止,HashMap的大致實現,我們應該已經清楚了。當然HashMap裡面也包含一些優化方面的實現,這裡也說一下。比如:Entry[]的長度一定後,隨著map裡面資料的越來越長,這樣同一個i的鏈就會很長,會不會影響效能?HashMap裡面設定一個因素(也稱為因子),隨著map的size越來越大,Entry[]會以一定的規則加長長度。
2、get(Object key)操作
get(Object key)操作時根據鍵來獲取值,如果瞭解了put操作,get操作容易理解,先來看看原始碼的實現:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))//-------------------1----------------
return e.value;
}
return null;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
意思就是:1、當key為null時,呼叫getForNullKey(),原始碼如下:
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
當key不為null時,先根據hash函式得到hash值,在更具indexFor()得到i的值,迴圈遍歷連結串列,如果有:key值等於已存在的key值,則返回其value。如上述get()程式碼1處判斷。
總結下HashMap新增put和獲取get操作:
//儲存時:
int hash = key.hashCode();
int i = hash % Entry[].length;
Entry[i] = value;
//取值時:
int hash = key.hashCode();
int i = hash % Entry[].length;
return Entry[i];
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
理解了就比較簡單。
此處附一個簡單的HashMap小演算法應用:
package com.xtfggef.hashmap;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 列印在陣列中出現n/2以上的元素
* 利用一個HashMap來存放陣列元素及出現的次數
* @author erqing
*
*/
public class HashMapTest {
public static void main(String[] args) {
int [] a = {2,3,2,2,1,4,2,2,2,7,9,6,2,2,3,1,0};
Map<Integer, Integer> map = new HashMap<Integer,Integer>();
for(int i=0; i<a.length; i++){
if(map.containsKey(a[i])){
int tmp = map.get(a[i]);
tmp+=1;
map.put(a[i], tmp);
}else{
map.put(a[i], 1);
}
}
Set<Integer> set = map.keySet();//------------1------------
for (Integer s : set) {
if(map.get(s)>=a.length/2){
System.out.println(s);
}
}//--------------2---------------
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
此處注意兩個地方,map.containsKey(),
理解了HashMap的上面的操作,其它的大多數方法都很容易理解了。搞清楚它的內部儲存機制,一切OK!
二、HashTable的內部儲存結構
HashTable和HashMap採用相同的儲存機制,二者的實現基本一致,不同的是:
1、HashMap是非執行緒安全的,HashTable是執行緒安全的,內部的方法基本都是synchronized。
2、HashTable不允許有null值的存在。
在HashTable中呼叫put方法時,如果key為null,直接丟擲NullPointerException。其它細微的差別還有,比如初始化Entry陣列的大小等等,但基本思想和HashMap一樣。
三、HashTable和ConcurrentHashMap的比較
如我開篇所說一樣,ConcurrentHashMap是執行緒安全的HashMap的實現。同樣是執行緒安全的類,它與HashTable在同步方面有什麼不同呢?
之前我們說,synchronized關鍵字加鎖的原理,其實是對物件加鎖,不論你是在方法前加synchronized還是語句塊前加,鎖住的都是物件整體,但是ConcurrentHashMap的同步機制和這個不同,它不是加synchronized關鍵字,而是基於lock操作的,這樣的目的是保證同步的時候,鎖住的不是整個物件。事實上,ConcurrentHashMap可以滿足concurrentLevel個執行緒併發無阻塞的操作集合物件。關於concurrentLevel稍後介紹。
1、構造方法
為了容易理解,我們先從建構函式說起。ConcurrentHashMap是基於一個叫Segment陣列的,其實和Entry類似,如下:
public ConcurrentHashMap()
{
this(16, 0.75F, 16);
} - 1
- 2
- 3
- 4
預設傳入值16,呼叫下面的方法:
public ConcurrentHashMap(int paramInt1, float paramFloat, int paramInt2)
{
if ((paramFloat <= 0F) || (paramInt1 < 0) || (paramInt2 <= 0))
throw new IllegalArgumentException();
if (paramInt2 > 65536) {
paramInt2 = 65536;
}
int i = 0;
int j = 1;
while (j < paramInt2) {
++i;
j <<= 1;
}
this.segmentShift = (32 - i);
this.segmentMask = (j - 1);
this.segments = Segment.newArray(j);
if (paramInt1 > 1073741824)
paramInt1 = 1073741824;
int k = paramInt1 / j;
if (k * j < paramInt1)
++k;
int l = 1;
while (l < k)
l <<= 1;
for (int i1 = 0; i1 < this.segments.length; ++i1)
this.segments[i1] = new Segment(l, paramFloat);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
你會發現比HashMap的建構函式多一個引數,paramInt1就是我們之前談過的initialCapacity,就是陣列的初始化大小,paramfloat為loadFactor(裝載因子),而paramInt2則是我們所要說的concurrentLevel,這三個值分別被初始化為16,0.75,16,經過:
while (j < paramInt2) {
++i;
j <<= 1;
} - 1
- 2
- 3
- 4
後,j就是我們最終要開闢的陣列的size值,當paramInt1為16時,計算出來的size值就是16.通過:
this.segments = Segment.newArray(j)後,我們看出了,最終稿建立的Segment陣列的大小為16.最終建立Segment物件時:
this.segments[i1] = new Segment(cap, paramFloat); - 1
需要cap值,而cap值來源於:
int k = paramInt1 / j;
if (k * j < paramInt1)
++k;
int cap = 1;
while (cap < k)
cap <<= 1; - 1
- 2
- 3
- 4
- 5
- 6
public V put(K paramK, V paramV)
{
if (paramV == null)
throw new NullPointerException();
int i = hash(paramK.hashCode());
return segmentFor(i).put(paramK, i, paramV, false);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
與HashMap不同的是,如果key為null,直接丟擲NullPointer異常,之後,同樣先計算hashCode的值,再計算hash值,不過此處hash函式和HashMap中的不一樣:
private static int hash(int paramInt)
{
paramInt += (paramInt << 15 ^ 0xFFFFCD7D);
paramInt ^= paramInt >>> 10;
paramInt += (paramInt << 3);
paramInt ^= paramInt >>> 6;
paramInt += (paramInt << 2) + (paramInt << 14);
return (paramInt ^ paramInt >>> 16);
}
[java] view plain copy
final Segment<K, V> segmentFor(int paramInt)
{
return this.segments[(paramInt >>> this.segmentShift & this.segmentMask)];
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
根據上述程式碼找到Segment物件後,呼叫put來操作:
V put(K paramK, int paramInt, V paramV, boolean paramBoolean)
{
lock();
try {
Object localObject1;
Object localObject2;
int i = this.count;
if (i++ > this.threshold)
rehash();
ConcurrentHashMap.HashEntry[] arrayOfHashEntry = this.table;
int j = paramInt & arrayOfHashEntry.length - 1;
ConcurrentHashMap.HashEntry localHashEntry1 = arrayOfHashEntry[j];
ConcurrentHashMap.HashEntry localHashEntry2 = localHashEntry1;
while ((localHashEntry2 != null) && (((localHashEntry2.hash != paramInt) || (!(paramK.equals(localHashEntry2.key)))))) {
localHashEntry2 = localHashEntry2.next;
}
if (localHashEntry2 != null) {
localObject1 = localHashEntry2.value;
if (!(paramBoolean))
localHashEntry2.value = paramV;
}
else {
localObject1 = null;
this.modCount += 1;
arrayOfHashEntry[j] = new ConcurrentHashMap.HashEntry(paramK, paramInt, localHashEntry1, paramV);
this.count = i;
}
return localObject1;
} finally {
unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
先呼叫lock(),lock是ReentrantLock類的一個方法,用當前儲存的個數+1來和threshold比較,如果大於threshold,則進行rehash,將當前的容量擴大2倍,重新進行hash。之後對hash的值和陣列大小-1進行按位於操作後,得到當前的key需要放入的位置,從這兒開始,和HashMap一樣。
從上述的分析看出,ConcurrentHashMap基於concurrentLevel劃分出了多個Segment來對key-value進行儲存,從而避免每次鎖定整個陣列,在預設的情況下,允許16個執行緒併發無阻塞的操作集合物件,儘可能地減少併發時的阻塞現象。
在多執行緒的環境中,相對於HashTable,ConcurrentHashMap會帶來很大的效能提升!
ArrayList工作原理
ArrayList工作原理其實很簡單,底層是動態陣列,每次建立一個ArrayList例項時會分配一個初始容量(如果指定了初始容量的話),以add方法為例,如果沒有指定初始容量,當執行add方法,先判斷當前陣列是否為空,如果為空則給儲存物件的陣列分配一個最小容量,這裡為10。當新增大容量元素額時候,會先增加陣列的大小,以提高新增的效率。
把ArrayList理解為一個數組就好了 先看看增大容量的方法
privatevoidgrow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
相關推薦
深入解析HashMap、ConcurrentHashMap丶HashTable丶ArrayList
Java集合類是個非常重要的知識點,HashMap、HashTable、ConcurrentHashMap等算是集合類中的重點,可謂“重中之重”,首先來看個問題,如面試官問你:HashMap和HashTable有什麼區別,一個比較簡單的回答是:
1、HashMap是非執
HashTable、HashMap、ConcurrentHashMap的原理與區別
希望各位小夥伴能帶著如下幾個問題來進行閱讀,這樣收穫會更大。
1.HashTable、HashMap、ConcurrentHashMap的區別?
2.HashMap執行緒不安全的出現場景?
3.HashMap put方法存放資料時是怎麼判斷是否重複的?
4.JD
深入解析HashMap
原文: http://www.iteye.com/topic/539465
Hashmap是一種非常常用的、應用廣泛的資料型別,最近研究到相關的內容,就正好複習一下。網上關於hashmap的文章很多,但到底是自己學習的總結,就發出來跟大家一起分享,一起討論。
HashMap和ConcurrentHashMap和HashTable的底層原理與剖析
HashMap 可以允許key為null,value為null,但HashMap的是執行緒不安全的 HashMap 底層是陣列 + 連結串列的資料結構
在jdk 1.7 中 map集合中的每一項都是一個 entry
在jdk 1.8 中
HashMap、ConcurrentHashMap實現原理及原始碼分析
HashMap:https://www.cnblogs.com/chengxiao/p/6059914.html
ConcurrentHashMap:https://blog.csdn.net/dingjianmin/article/details/79776646
遺留問
HashMap、TreeMap和HashTable的區別
Map介面有三個比較重要的實現類,分別是HashMap、TreeMap和HashTable。
TreeMap是有序的,HashMap和HashTable是無序的。
Hashtable的方法是同步的,HashMap的方法不是同步的。這是兩者最主要的區別。
這就意味著Hashtable是執行緒安全的,HashMa
HashMap、ConcurrentHashMap物件put(K key, V value)方法實現
以下原始碼版本為java8,與java7版本的HashMap原始碼有所差異,請區分。
HashMap物件put(K key, V value)原始碼
public V put(K key, V value) {
return putVal(hash(key), key
Java中關於Map的使用(HashMap、ConcurrentHashMap)
get java 多線程 tree ict per The name user
在日常開發中Map可能是Java集合框架中最常用的一個類了,當我們常規使用HashMap時可能會經常看到以下這種代碼:
Map<Integer, String> hashMap =
HashMap、TreeMap、Hashtable、HashSet和ConcurrentHashMap區別
擴展性 navig shc .net ica fin details blank table 一、HashMap和TreeMap區別
1、HashMap是基於散列表實現的,時間復雜度平均能達到O(1)。
TreeMap基於紅黑樹(一種自平衡二叉查找樹)實現的,時
HashTable、HashMap與ConCurrentHashMap源碼OA現金盤平臺出租解讀
cti 那不 累加 map集合 版本 結點 精神 plain objects HashMap 的數據結構? hashMap 初始的數據結構如下圖所示OA現金盤平臺出租QQ2952777280【話仙源碼論壇】hxforum.com【木瓜源碼論壇】papayabbs.com,內
HashMap、Hashtable、ConcurrentHashMap的原理與區別
另一個 cnblogs 需要 構造器 新的 底層 bsp 哈希 fas HashTable
底層數組+鏈表實現,無論key還是value都不能為null,線程安全,實現線程安全的方式是在修改數據時鎖住整個HashTable,效率低,ConcurrentHashMap做了相
hashmap資料結構詳解(五)之HashMap、HashTable、ConcurrentHashMap 的區別
【hashmap 與 hashtable】
hashmap資料結構詳解(一)之基礎知識奠基
hashmap資料結構詳解(二)之走進JDK原始碼
hashmap資料結構詳解(三)之hashcode例項及大小是2的冪次方解釋
hashmap資料結構詳解(四)之has
多執行緒(九): HashTable、HashMap和ConcurrentHashMap
public class HashTest {
static Map<String, Integer> map = new HashMap<String, Integer>();
// static Map<String, Integer&g
HashMap、Hashtable、ConcurrentHashMap對比
1.執行緒不安全的HashMap 因為多執行緒環境下,使用Hashmap進行put操作會引起死迴圈,導致CPU利用率接近100%,所以在併發情況下不能使用HashMap。
2.效率低下的HashTable容器 HashTable容器使用synchronized來保證執行緒安全,但線
hashMap,hashTable,concurrentHashmap的區別 面試必備:HashMap、Hashtable、ConcurrentHashMap的原理與區別
轉自
面試必備:HashMap、Hashtable、ConcurrentHashMap的原理與區別
果你去面試,面試官不問你這個問題,你來找我^_^
下面直接來乾貨,先說這三個Map的區別:
HashTable
底層陣列+連結串列實現,無論key還是value都不能為null,執行
Java原始碼分析——java.util工具包解析(三)——HashMap、TreeMap、LinkedHashMap、Hashtable類解析
Map,中文名字對映,它儲存了鍵-值對的一對一的關係形式,並用雜湊值來作為存貯的索引依據,在查詢、插入以及刪除時的時間複雜度都為O(1),是一種在程式中用的最多的幾種資料結構。Java在java.util工具包中實現了Map介面,來作為各大
各種集合框架的總結ArrayList、LinkedList、Vector、HashMap、HashTable、HashSet、LinkedHaSet、TreeSet、ConcurrentHashMap
這幾道Java集合框架面試題在面試中幾乎必問
1.Arraylist 與 LinkedList 異同
1. 執行緒安全: ArrayList 和 LinkedList 都是執行緒不安全的;
2. 資料結構: Arraylist 底層使用的是Object陣列;Linked
Java集合——HashMap、HashTable以及ConCurrentHashMap異同比較
0. 前言
HashMap和HashTable的區別一種比較簡單的回答是:
(1)HashMap是非執行緒安全的,HashTable是執行緒安全的。
(2)HashMap的鍵和值都允許有null存在,而HashTable則都不行。
(3)因為執行緒安全、雜湊效率的
面試必備:HashMap、Hashtable、ConcurrentHashMap的原理與區別
如果你去面試,面試官不問你這個問題,你來找我^_^
下面直接來乾貨,先說這三個Map的區別:
HashTable
底層陣列+連結串列實現,無論key還是value都不能為null,執行緒安全,實現執行緒安全的方式是在修改資料時鎖住整個HashTable,效率低,Conc
HashMap、HashTable及ConcurrentHashMap區別及工作原理
前言
第一次寫部落格,水平有限可能有理解不到位或理解錯的地方。歡迎各位大神參與討論或指正。
Map在工作中的使用頻率較高,HashMap相關的問題在面試中也經常被問到。所以抽空在網上找資料對它們進行了系統的學習,作出以下幾點總結:
HashMap、Hash