
python爬蟲-爬取盜墓筆記
本來今天要繼續更新scrapy爬取美女圖片系列文章,可是發現使用免費的代理ip都非常不穩定,有時候連線上,有時候連線不上,所以我想找到穩定的代理ip,下次再更新 scrapy爬取美女圖片之應對反爬蟲 文章。
好了,廢話不多說,咱們進入今天的主題。這一篇文章是關於爬取盜墓筆記,主要技術要點是scrapy的使用,scrapy框架中使用mongodb資料庫,檔案的儲存。

這次爬取的網址是 http://seputu.com/。之前也經常在上面線上看盜墓筆記。

按照咱們之前的學習爬蟲的做法,使用firebug審查元素,檢視如何解析html。
這次咱們要把書的名稱,章節,章節名稱,章節連結抽取出來,儲存到資料庫中,同時將文章的內容提取出來存成txt檔案。
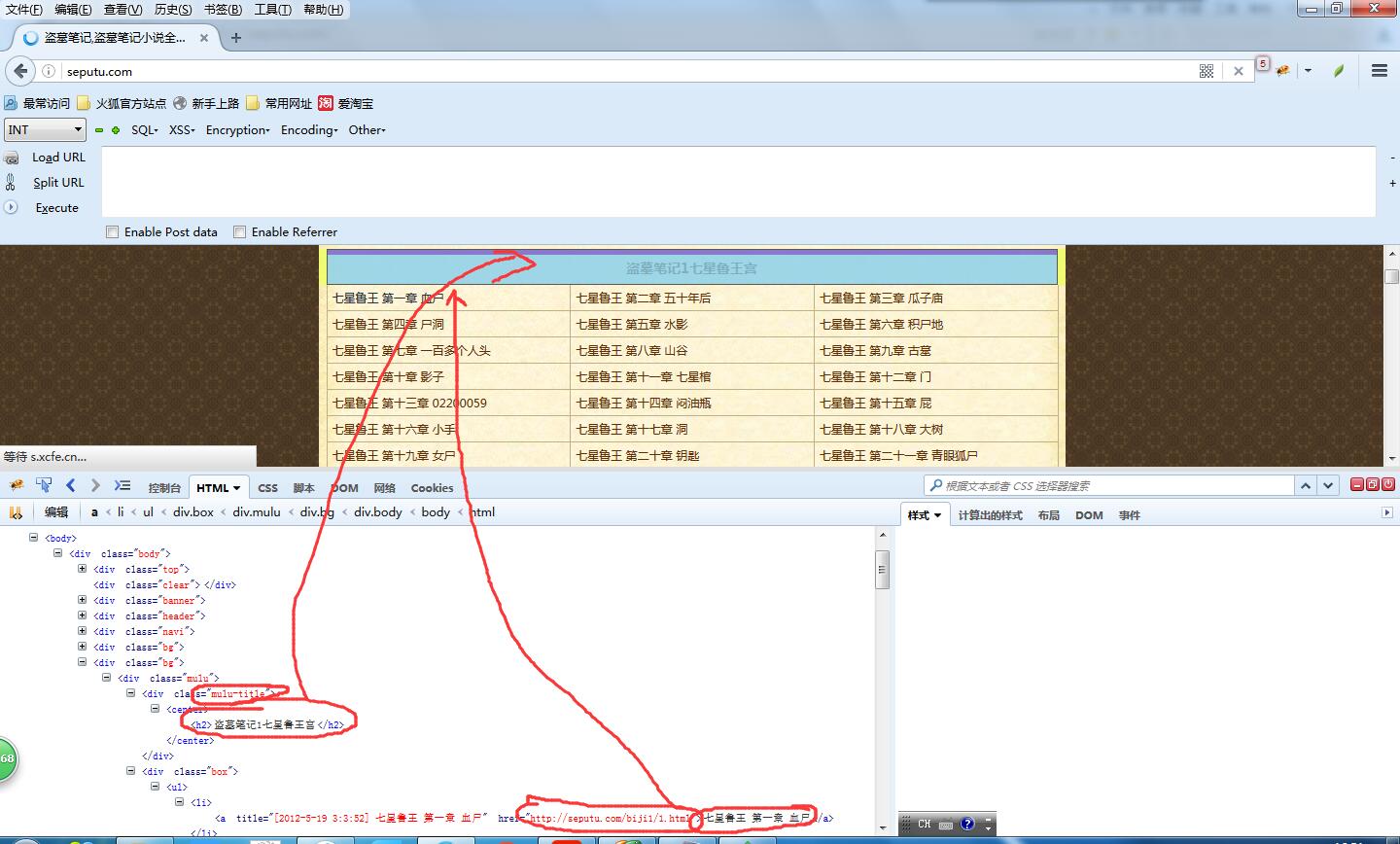
看一下html結構就會發現這個頁面結構非常分明,標題的html節點是 div class = ''mulu-title",章節的節點是div class= "box",每一章的節點是 div class= "box"中的<li>標籤。
然後咱們將第一章的連結 http://seputu.com/biji1/1.html開啟,上面就是文章的內容。
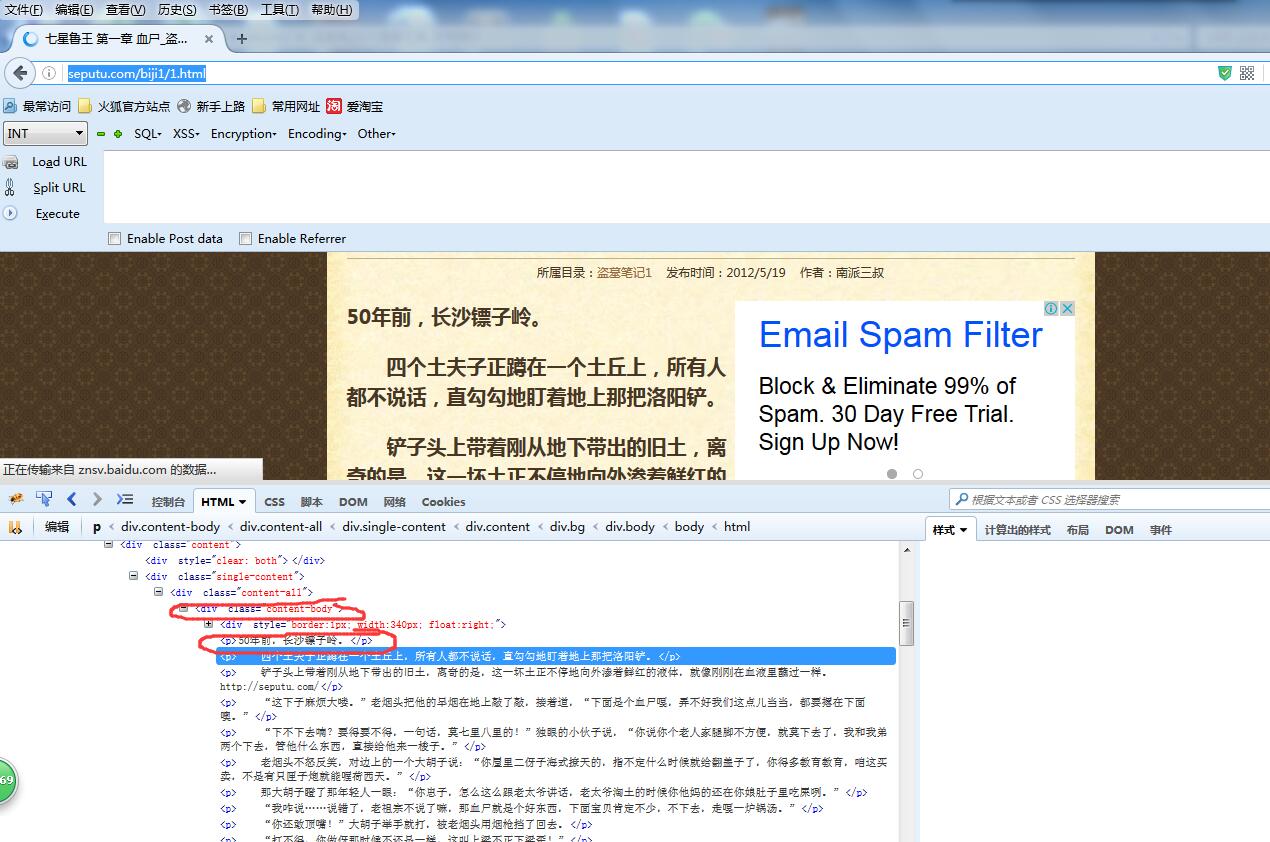
可以看到文章的內容是使用div class ="content-body"
開啟cmd,輸入scrapy startproject daomubiji,這時候會生成一個工程,然後我把整個工程複製到pycharm中
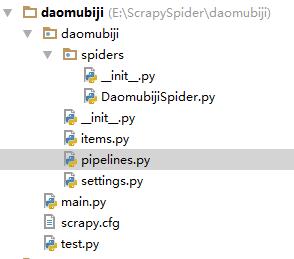
上圖就是工程的結構。
DaomubijiSpider.py ------Spider 蜘蛛
items.py -----------------對要爬取資料的模型定義
pipelines.py-------------處理要儲存的資料(存到資料庫和寫到檔案)
settings.py----------------對Scrapy的配置
main.py -------------------啟動爬蟲
test.py -------------------- 測試程式(不參與整體執行)
下面將解析和儲存的程式碼貼一下,完整程式碼已上傳到github:https://github.com/qiyeboy/daomuSpider。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
DaomubijiSpider.py
(解析html)
#coding:utf-8
importscrapy
fromscrapy.selectorimportSelector
from
|