
轉載:簡明實用的CUDA入門教程
Sample code in adding 2 numbers with a GPU
Terminology: Host (a CPU and host memory), device (a GPU and device memory).
This sample code adds 2 numbers together with a GPU:
- Define a kernel (a function to run on a GPU).
- Allocate & initialize the host data.
- Allocate & initialize the device data.
- Invoke a kernel in the GPU.
- Copy kernel output to the host.
- Cleanup.
Define a kernel
Use the keyword __global__ to define a kernel. A kernel is a function to be run on a GPU instead of a CPU. This kernel adds 2 numbers aa & bb and store the result in cc.
// Kernel definition // Run on GPU // Adding 2 numbers and store the result in c __global__ void add(int *a, int *b, int *c) { *c = *a + *b; }
Allocate & initialize host data
In the host, allocate the input and output parameters for the kernel call, and initiate all input parameters.
int main(void) { // Allocate & initialize host data - run on the host int a, b, c; // host copies of a, b, c a = 2; b = 7; ... }
Allocate and copy host data to the device
A CUDA application manages the device space memory through calls to the CUDA runtime. This includes device memory allocation and deallocation as well as data transfer between the host and device memory.
We allocate space in the device so we can copy the input of the kernel (aa & bb) from the host to the device. We also allocate space to copy result from the device to the host later.
int main(void) {
...
int *d_a, *d_b, *d_c; // device copies of a, b, c
// Allocate space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy a & b from the host to the device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
...
}
Invoke the kernel
Invoke the kernel add with parameters for a,b,c.a,b,c.
int main(void) {
...
// Launch add() kernel on GPU with parameters (d_a, d_b, d_c)
add<<<1,1>>>(d_a, d_b, d_c);
...
}
To provide data parallelism, a multithreaded CUDA application is partitioned into blocks of threads that execute independently (and often concurrently) from each other. Each parallel invocation of add is referred to as a block. Each block have multiple threads. These block of threads can be scheduled on any of the available streaming multiprocessors (SM) within a GPU. In our simple example, since we just add one pair of numbers, we only need 1 block containing 1 thread (<<<1,1>>>).
In contrast to a regular C function call, a kernel can be executed N times in parallel by M CUDA threads (<<<N, M>>>). On current GPUs, a thread block may contain up to 1024 threads.
Copy kernel output to the host
Copy the addition result from the device to the host:
// Copy result back to the host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
Clean up
Clean up memory:
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
Putting together: Heterogeneous Computing
In CUDA, we define a single file to run both the host and the device code.
nvcc add.cu # Compile the source code
a.out # Run the code.
The following is the complete source code for our example.
// Kernel definition
// Run on GPU
__global__ void add(int *a, int *b, int *c) {
*c = *a + *b;
}
int main(void) {
// Allocate & initialize host data - run on the host
int a, b, c; // host copies of a, b, c
a = 2;
b = 7;
int *d_a, *d_b, *d_c; // device copies of a, b, c
// Allocate space for device copies of a, b, c
int size = sizeof(int);
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy a & b from the host to the device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<1,1>>>(d_a, d_b, d_c);
// Copy result back to the host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
CUDA logical model
add<<<4,4>>>(d_a, d_b, d_c);
A CUDA applications composes of multiple blocks of threads (a grid) with each thread calls a kernel once.
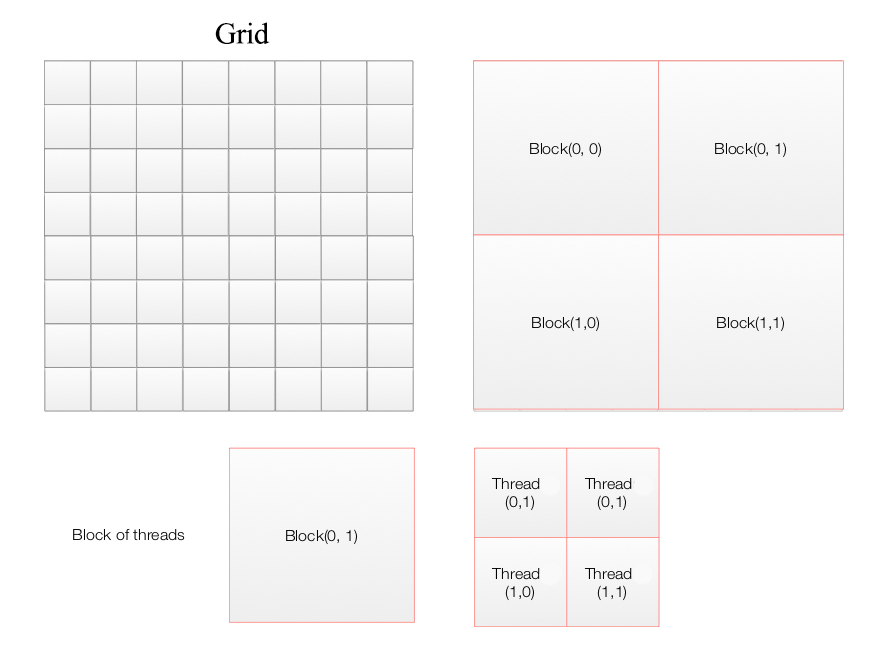
In the second example, we have 6 blocks and 12 threads per block.
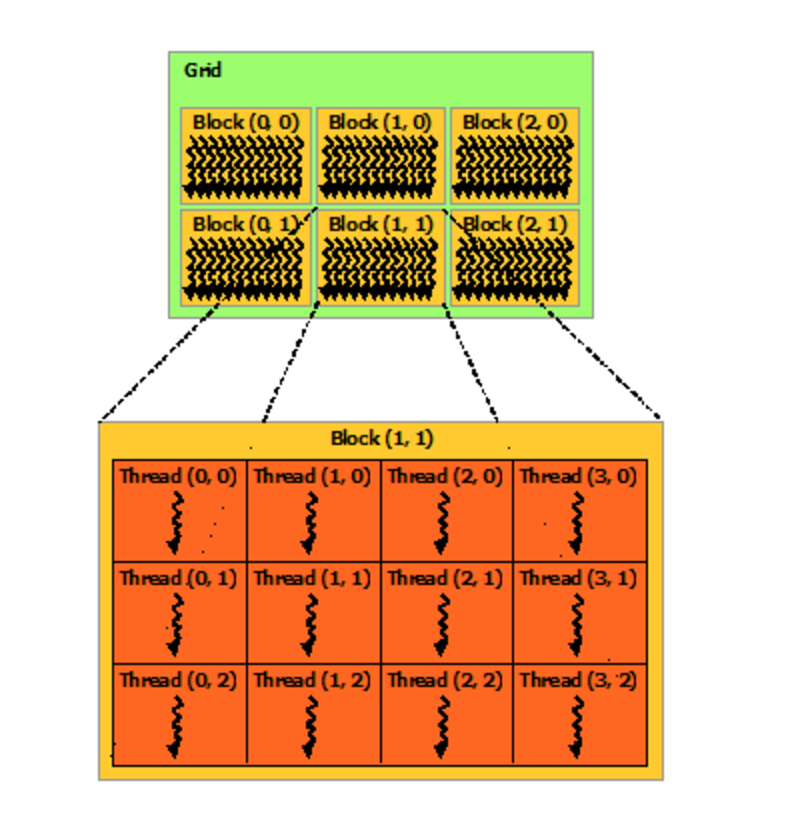
(source: Nvidia)
GPU physical model
A GPU composes of many Streaming Multiprocessors (SMs) with a global memory accessible by all SMs and a local memory.
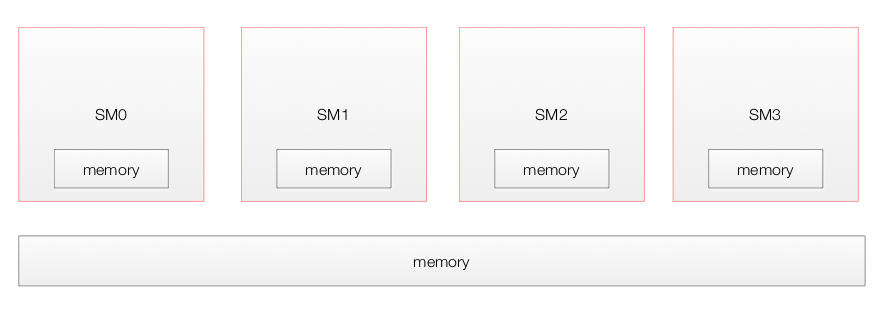
Each SM contains multiple cores which share a shared memory as well as one local to itself.
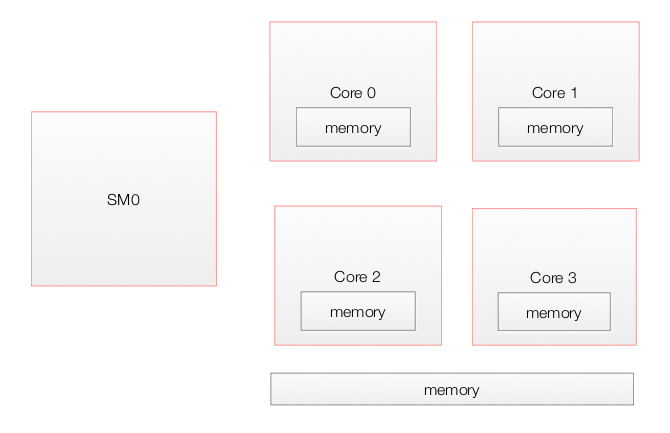
Here is the architect for GeoForce 8800 with 16 SMs each with 8 cores (Streaming processing SP).
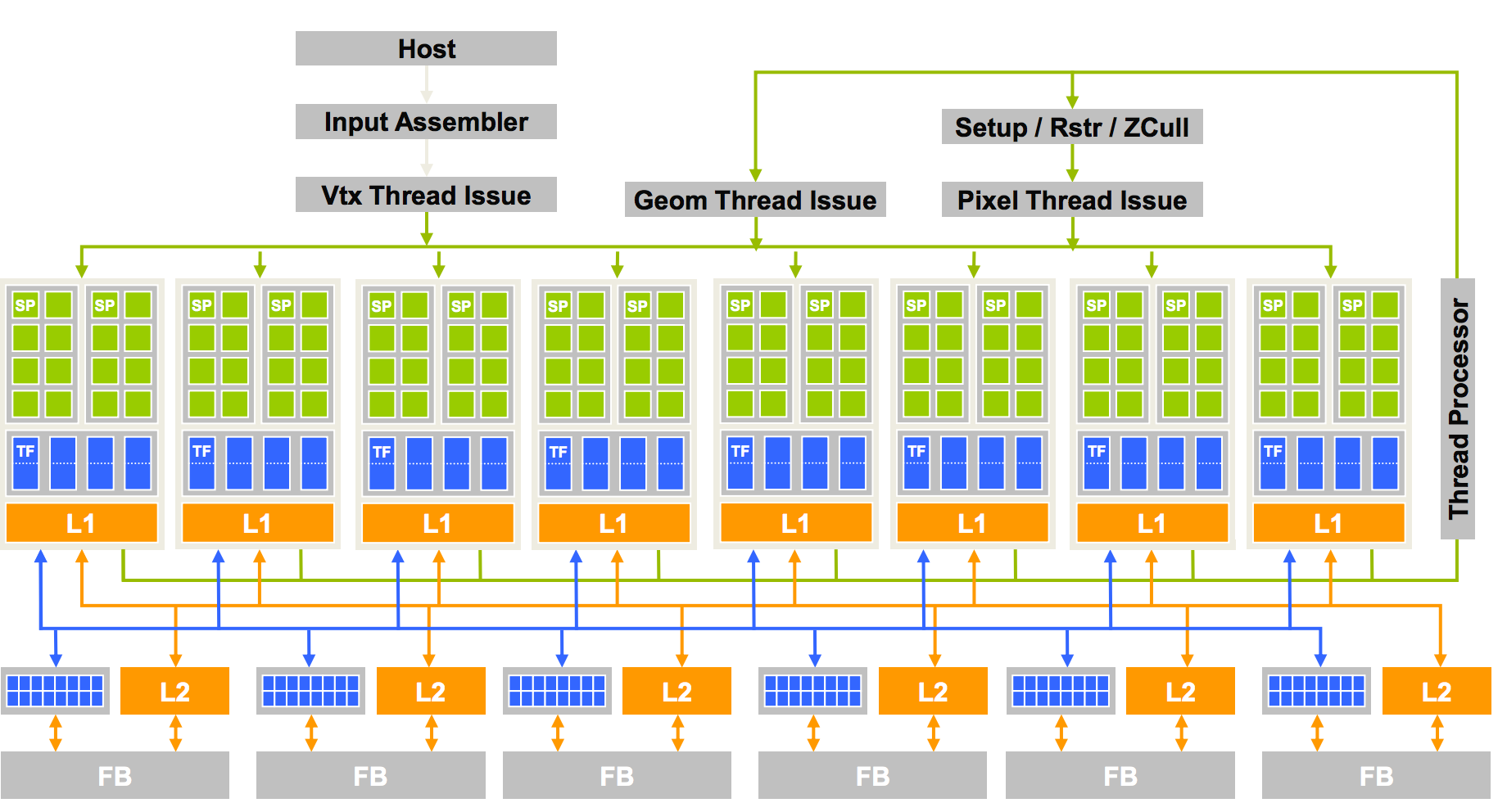
A SM in the Fermi architecture:
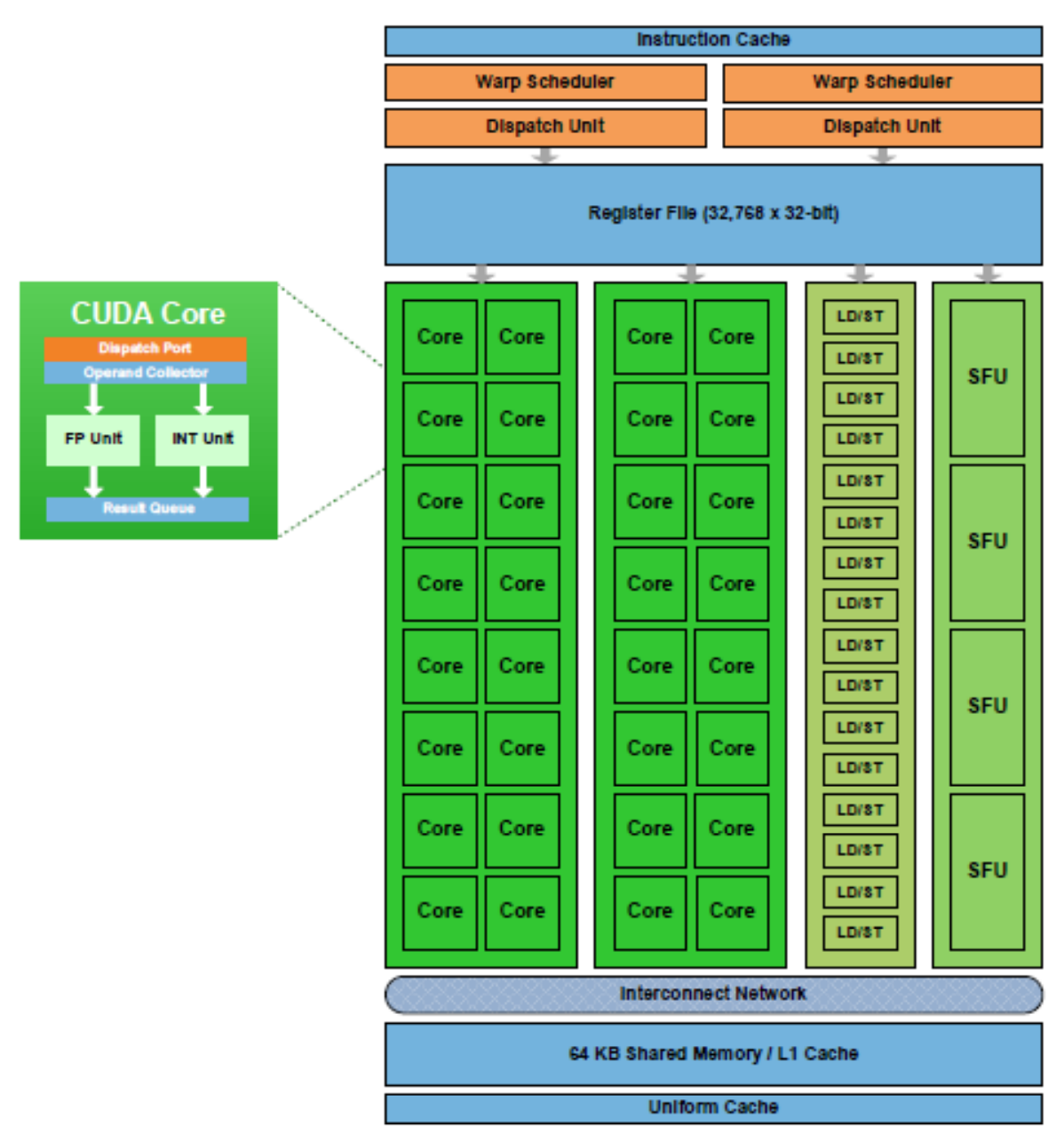
Execution model
Device level
When a CUDA application on the host invokes a kernel grid, the blocks of the grid are enumerated and a global work distribution engine assign them to SM with available execution capacity. Threads of the same block always run on the same SM. Multiple thread blocks and multiple threads in a thread block can execute concurrently on one SM. As thread blocks terminate, new blocks are launched on the vacated multiprocessors.
All threads in a grid execute the same kernel. GPU can handle multiple kernels from the same application simultaneously. Pascal GP100 can handle maximum of 32 thread blocks and 2048 threads per SM.
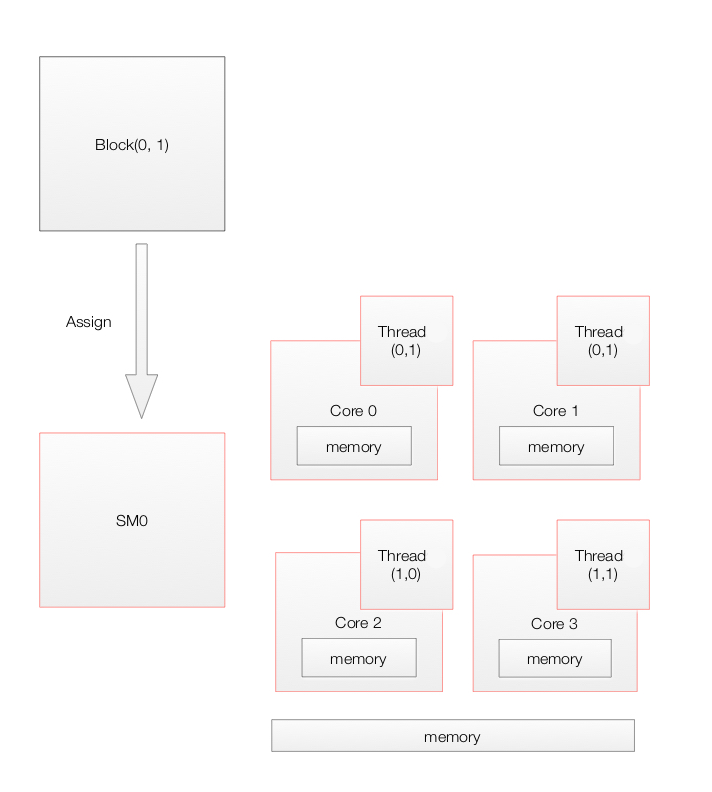
Here, we have a CUDA application composes of 8 blocks. It can be executed on a GPU with 2 SMs or 4SMs. With 4 SMs, block 0 & 4 is assigned to SM0, block 1, 5 to SM1, block 2, 6 to SM2 and block 3, 7 to SM3.
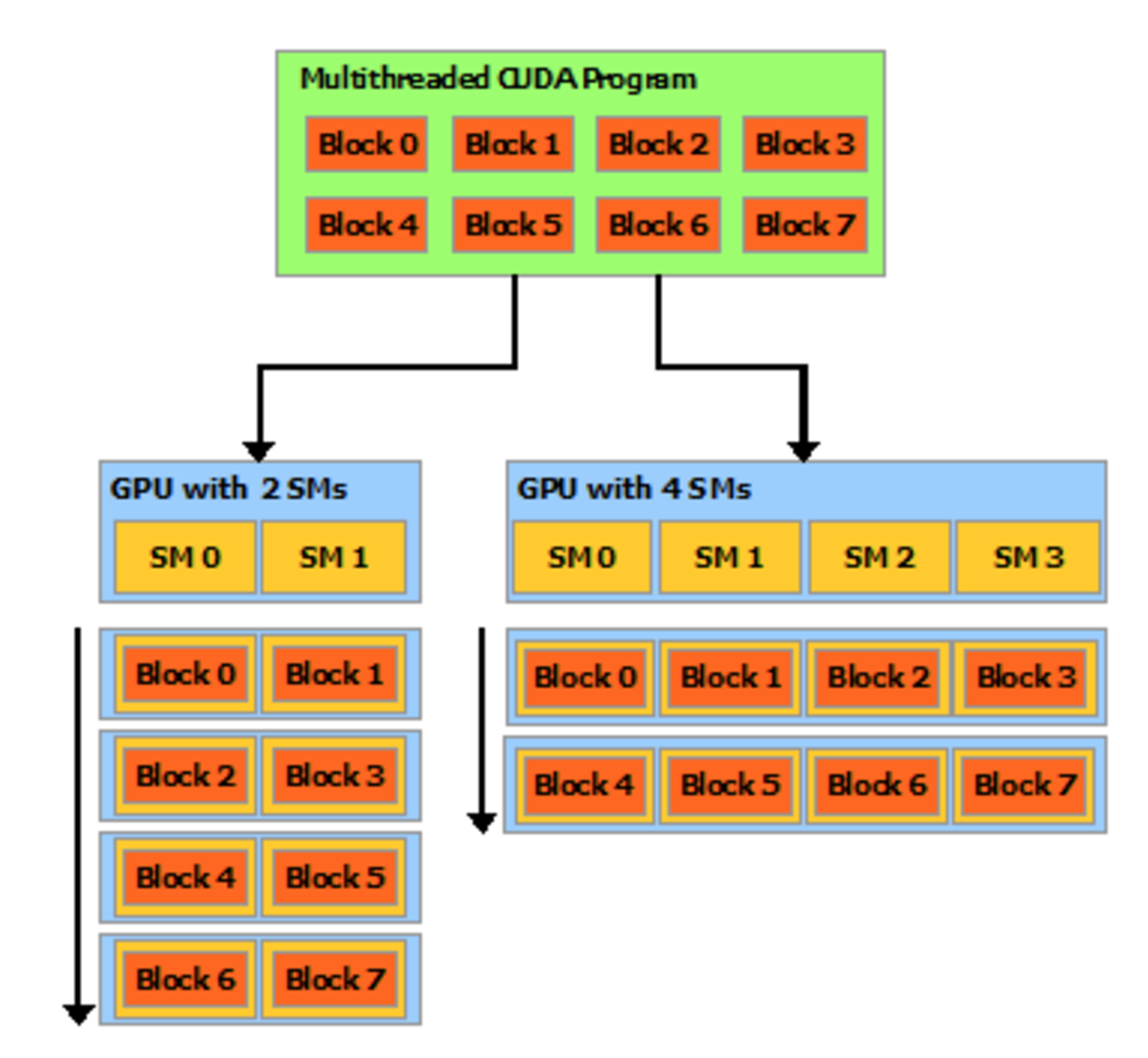
(source: Nvidia)
The entire device can only process one single application at a time and switch between applications is slow.
SM level
Once a block of threads is assigned to a SM, the threads are divided into units called warps. A block is partitioned into warps with each warp contains threads of consecutive, increasing thread IDs with the first warp containing thread 0.The size of a warp is determined by the hardware implementation. A warp scheduler selects a warp that is ready to execute its next instruction. In Fremi architect, the warp scheduler schedule a warp of 32 threads. Each warp of threads runs the same instruction. In the diagram below, we have 2 dispatch unit. Each one runs a different warp. In each warp, it runs the same instruction. When the threads in a warp is wait for the previous instruction to complete, the warp scheduler will select another warp to execute. Two warps from different blocks or different kernels can be executed concurrently.
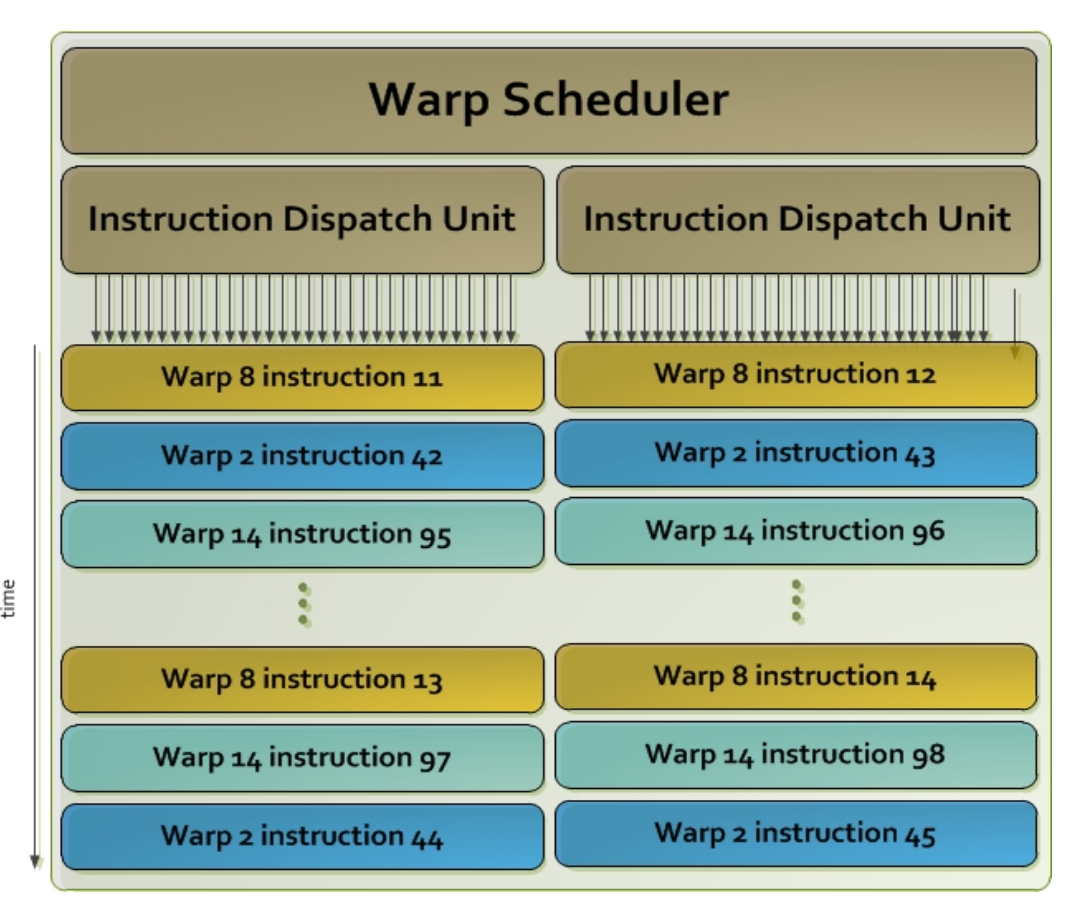
Branch divergence
A warp executes one common instruction at a time. Each core (SP) run the same instruction for each threads in a warp. To execute a branch like:
if (a[index]==0)
a[index]++;
else
a[index]--;
SM skips execution of a core subjected to the branch conditions:
| c0 (a=3) | c1(a=3) | c2 (a=-3) | c3(a=7) | c4(a=2) | c5(a=6) | c6 (a=-2) | c7 (a=-1) | |
| if a[index]==0 | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ |
| a[index]++ | ↓ | ↓ | ↓ | ↓ | ↓ | |||
| a[index]– | ↓ | ↓ | ↓ |
So full efficiency is realized when all 32 threads of a warp branch to the same execution path. If threads of a warp diverge via a data-dependent conditional branch, the warp serially executes each branch path taken, disabling threads that are not on that path, and when all paths complete, the threads converge back to the same execution path.
To maximize throughput, all threads in a warp should follow the same control-flow. Program can be rewritten such that threads within a warp branch to the same code:
if (a[index]<range)
... // More likely, threads with a warp will branch the same way.
else
...
is preferred over
if (a[index]%2==0)
...
else
...
For loop unrolling is another technique to avoid branching:
for (int i=0; i<4; i++)
c[i] += a[i];
c[0] = a[0] + a[1] + a[2] + a[3];
Memory model
Every SM has a shared memory accessible by all threads in the same block. Each thread has its own set of registers and local memory. All blocks can access a global memory, a constant memory(read only) and a texture memory. (read only memory for spatial data.)
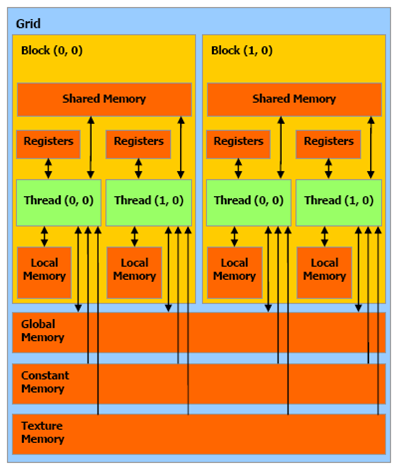
Local, Global, Constant, and Texture memory all reside off chip. Local, Constant, and Texture are all cached. Each SM has a L1 cache for global memory references. All SMs share a second L2 cache. Access to the shared memory is in the TB/s. Global memory is an order of magnitude slower. Each GPS has a constant memory for read only with shorter latency and higher throughput. Texture memory is read only.
| Type | Read/write | Speed |
|---|---|---|
| Global memory | read and write | slow, but cached |
| Texture memory | read only | cache optimized for 2D/3D access pattern |
| Constant memory | read only | where constants and kernel arguments are stored |
| Shared memory | read/write | fast |
| Local memory | read/write | used when it does not fit in to registers part of global memory slow but cached |
| Registers | read/write | fast |
Local memory is just thread local global memory. It is much slower than either registers or shared memory.
Speed (Fast to slow):
- Register file
- Shared Memory
- Constant Memory
- Texture Memory
- (Tie) Local Memory and Global Memory
| Declaration | Memory | Scope | Lifetime |
| int v | register | thread | thread |
| int vArray[10] | local | thread | thread |
| __shared__ int sharedV | shared | block | block |
| __device__ int globalV | global | grid | application |
| __constant__ int constantV | constant | grid | application |
When threads in a warp load data from global memory, the system detects whether they are consecutive. It combines consecutive accesses into one single access to DRAM.
Shared memory
Shared memory is on-chip and is much faster than local and global memory. Shared memory latency is roughly 100x lower than uncached global memory latency. Threads can access data in shared memory loaded from global memory by other threads within the same thread block. Memory access can be controlled by thread synchronization to avoid race condition (__syncthreads). Shared memory can be uses as user-managed data caches and high parallel data reductions.
Static shared memory:
#include
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[64];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
// Will not conttinue until all threads completed.
__syncthreads();
d[t] = s[tr];
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run version with static shared memory
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
staticReverse<<<1,n>>>(d_d, n);
cudaMemcpy(d, d_d, n*sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)n", i, i, d[i], r[i]);
}
The __syncthreads() is light weighted and a block level synchronization barrier. __syncthreads() ensures all threads have completed before continue.
Dynamic Shared Memory:
#include
__global__ void dynamicReverse(int *d, int n)
{
// Dynamic shared memory
extern __shared__ int s[];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run dynamic shared memory version
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
dynamicReverse<<<1,n,n*sizeof(int)>>>(d_d, n);
cudaMemcpy(d, d_d, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)n", i, i, d[i], r[i]);
}
Shared memory are accessable by multiple threads. To reduce potential bottleneck, shared memory is divided into logical banks. Successive sections of memory are assigned to successive banks. Each bank services only one thread request at a time, multiple simultaneous accesses from different threads to the same bank result in a bank conflict (the accesses are serialized).
Shared memory banks are organized such that successive 32-bit words are assigned to successive banks and the bandwidth is 32 bits per bank per clock cycle. For devices of compute capability 1.x, the warp size is 32 threads and the number of banks is 16. There will be 2 reque