
推薦系統學習總結
前段時間參加了泰迪杯資料探勘挑戰賽,選的是B題電視產品營銷推薦。由於涉及到推薦系統這一塊比較大的知識領域,之前沒有學過,於是在比賽之初找了一些網上的資料自學了幾天,有了一些初步的瞭解與認識。因實訓的專案中推薦系統仍是很重要的一部分,故重新再複習一遍,加之比賽中的一些感悟作此總結。
附上原版連結,挑選了兩個比較不錯的連結,通俗易懂,可做入門用。
1.5類系統推薦演算法,非常好使,非常全 - CSDN部落格
2.探索推薦引擎內部的祕密,第 1 部分: 推薦引擎初探
探索推薦引擎內部的祕密,第 2 部分: 深入推薦引擎相關演算法 - 協同過濾
探索推薦引擎內部的祕密,第 3 部分: 深入推薦引擎相關演算法 - 聚類
所謂推薦,我們聯絡一下現實,無論是自己給別人推薦還是別人給自己推薦,歸根結底是通過尋找相似或者說關聯來推薦。以相似和關聯這兩條主線來理解推薦機制就很容易接受了。
相似:人的相似與物的相似。
基於人口統計學的推薦機制 與 基於內容的推薦機制
基於人口統計學的推薦機制
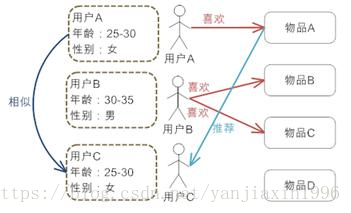
基於內容的推薦機制
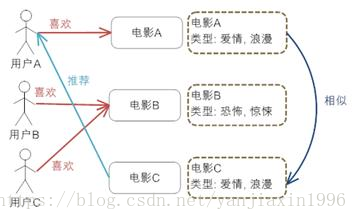
關聯:使用者為主的關聯與物品為主的關聯。
基於使用者的協同過濾推薦 與 基於專案的協同過濾推薦
基於使用者的協同過濾推薦
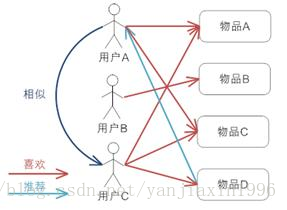
基於專案的協同過濾推薦
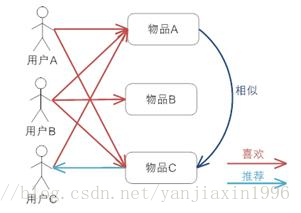
基於物品和使用者本身的,這種推薦引擎將每個使用者和每個物品都當作獨立的實體,預測每個使用者對於每個物品的喜好程度,這些資訊往往是用一個二維矩陣描述的。由於使用者感興趣的物品遠遠小於總物品的數目,這樣的模型導致大量的資料空置,即我們得到的二維矩陣往往是一個很大的稀疏矩陣。同時為了減小計算量,我們可以對物品和使用者進行聚類,然後記錄和計算一類使用者對一類物品的喜好程度,但這樣的模型又會在推薦的準確性上有損失。
——節選自 探索推薦引擎內部的祕密,第 1 部分: 推薦引擎初探
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html#icomments 推薦引擎的分類
在做泰迪杯的時候,對推薦系統瞭解不多,只用最簡單的想法去進行程式設計,最終得出1000多名使用者與20多個標籤的對應矩陣和1000多部電視產品與20多個標籤的對應矩陣,看似成功就在眼前,然而在計算使用者相似度和產品相似度的時候卻因為矩陣的過於稀疏以及演算法的簡陋,運算時間遠超預想,難以實現。
總結教訓,在此次實訓中必須要考慮如何聚類分析,對於大量的資料,如果犧牲一定的準確性可以換來運算效率的大幅提升的話,這樣的犧牲是很有必要的。
可以應用在專案實訓的推薦裡面,考慮一下分割槽混合的應用。混合的推薦機制
在現行的 Web 站點上的推薦往往都不是單純只採用了某一種推薦的機制和策略,他們往往是將多個方法混合在一起,從而達到更好的推薦效果。關於如何組合各個推薦機制,這裡講幾種比較流行的組合方法。
加權的混合(Weighted Hybridization): 用線性公式(linear formula)將幾種不同的推薦按照一定權重組合起來,具體權重的值需要在測試資料集上反覆實驗,從而達到最好的推薦效果。
切換的混合(Switching Hybridization):前面也講到,其實對於不同的情況(資料量,系統執行狀況,使用者和物品的數目等),推薦策略可能有很大的不同,那麼切換的混合方式,就是允許在不同的情況下,選擇最為合適的推薦機制計算推薦。
分割槽的混合(Mixed Hybridization):採用多種推薦機制,並將不同的推薦結果分不同的區顯示給使用者。其實,Amazon,噹噹網等很多電子商務網站都是採用這樣的方式,使用者可以得到很全面的推薦,也更容易找到他們想要的東西。
分層的混合(Meta-Level Hybridization): 採用多種推薦機制,並將一個推薦機制的結果作為另一個的輸入,從而綜合各個推薦機制的優缺點,得到更加準確的推薦。
——節選自 探索推薦引擎內部的祕密,第 1 部分: 推薦引擎初探
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html#icomments 推薦引擎的應用