
HashMap底層資料結構原理解析
老師:JDK中我們最常用的一個數據類是HashMap。那麼,誰可以回答一下HashMap的底層資料結構原理是什麼呢?
小明:老師,我知道。眾所周知,HashMap是一個用於儲存Key-Value鍵值對的集合,每一個鍵值對也叫做Entry。這些個鍵值對(Entry)分散儲存在一個數組當中,這個陣列就是HashMap的主幹。
HashMap陣列每一個元素的初始值都是Null。

對於HashMap,我們最常使用的是兩個方法:Get 和 Put。
1.Put方法的原理
呼叫Put方法的時候發生了什麼呢?
比如呼叫hashMap.put("apple", 0) ,插入一個Key為“apple"的元素。這時候我們需要利用一個雜湊函式來確定
index= Hash(“apple”)
假定最後計算出的index是2,那麼結果如下:

但是,因為HashMap的長度是有限的,當插入的Entry越來越多時,再完美的Hash函式也難免會出現index衝突的情況。比如下面這樣:

這時候該怎麼辦呢?我們可以利用連結串列來解決。
HashMap陣列的每一個元素不止是一個Entry物件,也是一個連結串列的頭節點。每一個Entry物件通過Next指標指向它的下一個Entry節點。當新來的Entry對映到衝突的陣列位置時,只需要插入到對應的連結串列即可:

需要注意的是,新來的Entry節點插入連結串列時,使用的是“頭插法”。至於為什麼不插入連結串列尾部,後面會有解釋。
2.Get方法的原理
使用Get方法根據Key來查詢Value的時候,發生了什麼呢?
首先會把輸入的Key做一次Hash對映,得到對應的index:
index= Hash(“apple”)
由於剛才所說的Hash衝突,同一個位置有可能匹配到多個Entry,這時候就需要順著對應連結串列的頭節點,一個一個向下來查詢。假設我們要查詢的Key
是“apple”:
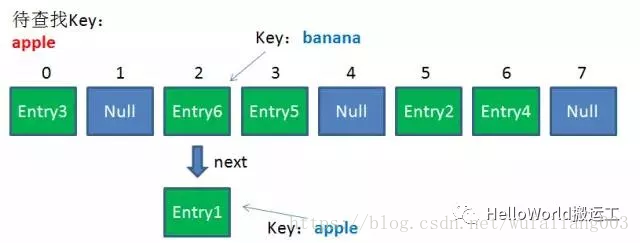
第一步,我們檢視的是頭節點Entry6,Entry6的Key是banana,顯然不是我們要找的結果。
第二步,我們檢視的是Next節點Entry1,Entry1的Key是apple,正是我們要找的結果。
之所以把Entry6放在頭節點,是因為HashMap的發明者認為,後插入的
老師:不錯!整體上說的差不多。不過我還有幾個問題想深入問一下。HashMap預設的初始長度是多少?為什麼這麼規定?
小明:呃,不知道。。。。。
老師:高併發情況下,為什麼HashMap可能會出現死鎖?
小明:呃,也不知道。。。。。
老師:在Java8當中,HashMap的結構有什麼樣的優化?
小明:呃。。。。。
老師:針對這幾個問題,咱們來深入瞭解一下HashMap的底層結構原理。首先明確一點,HashMap的預設初始長度是16,並且每次自動擴充套件或是手動初始化時,長度必須是2的冪。
小明:為什麼是16?有什麼特殊意義呢?
老師:之所以選擇16,是為了服務於從Key對映到index的Hash演算法。
之前說過,從Key對映到HashMap陣列的對應位置,會用到一個Hash函式:
index= Hash(“apple”)
如何實現一個儘量均勻分佈的Hash函式呢?我們通過利用Key的HashCode值來做某種運算。
小明:我知道了,是不是把Key的HashCode值和HashMap長度做取模運算呀?
index= HashCode(Key) % Length ?
老師:錯!取模運算的方式固然簡單,但是效率很低。為了實現高效的Hash演算法,HashMap的發明者採用了位運算的方式。
如何進行位運算呢?有如下的公式(Length是HashMap的長度):
index= HashCode(Key) & (Length - 1)
下面我們以值為“book”的Key來演示整個過程:
1.計算book的hashcode,結果為十進位制的3029737,二進位制的1011100011101011101001。
2.假定HashMap長度是預設的16,計算Length-1的結果為十進位制的15,二進位制的1111。
3.把以上兩個結果做與運算,101110001110101110 1001 & 1111 = 1001,十進位制是9,所以index=9。可以說,Hash演算法最終得到的index結果,完全取決於Key的Hashcode值的最後幾位。
小明:這樣的方式有什麼好處呢?為什麼長度必須是16或者2的冪?比如HashMap長度是10會怎麼樣?
老師:這樣做不但效果上等同於取模,而且還大大提高了效能。至於為什麼採用16,我們可以試試長度是10會出現什麼問題。
假設HashMap的長度是10,重複剛才的運算步驟:

單獨看這個結果,表面上並沒有問題。我們再來嘗試一個新的HashCode 101110001110101110 1011 :

讓我們再換一個HashCode 101110001110101110 1111 試試 :

是的,雖然HashCode的倒數第二第三位從0變成了1,但是運算的結果都是1001。也就是說,當HashMap長度為10的時候,有些index結果的出現機率會更大,而有些index結果永遠不會出現(比如0111)!
這樣,顯然不符合Hash演算法均勻分佈的原則。
反觀長度16或者其他2的冪,Length-1的值是所有二進位制位全為1,這種情況下,index的結果等同於HashCode後幾位的值。只要輸入的HashCode本身分佈均勻,Hash演算法的結果就是均勻的。
小明:這下明白了。
老師:HashMap的設計還存在著許多玄妙之處。關於高併發情況下的HashMap,我們以後會繼續介紹。
關注微信公眾號和今日頭條,精彩文章持續更新中。。。。。


