
mysql優化實戰(explain && 索引)
| 1、sql工具:Navicat 2、sql資料庫,使用openstack資料庫作為示例 |
一、mysql索引查詢
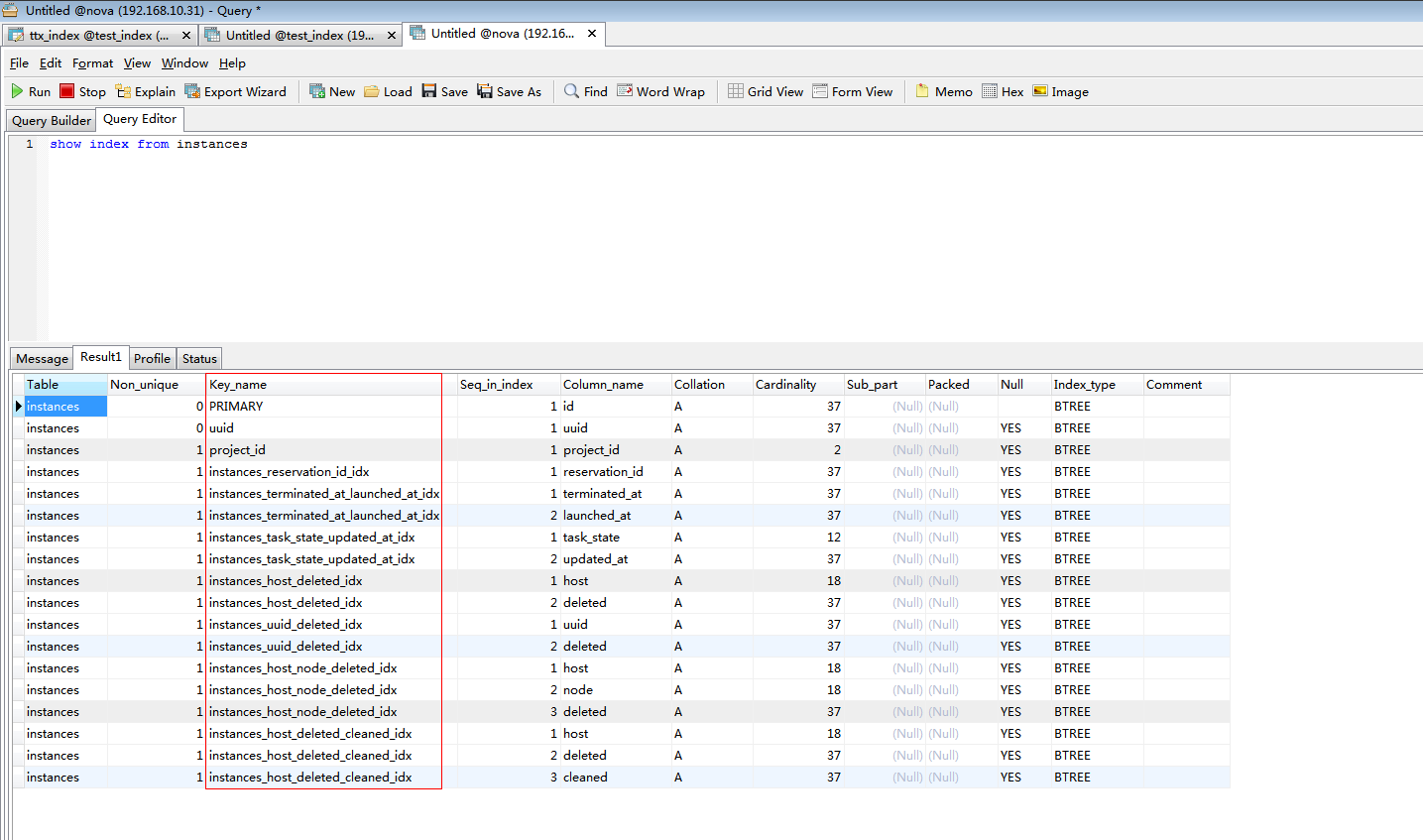
| show index from instances |
 結果欄位解釋:
結果欄位解釋:
|
Table:資料庫表名
Non_unique:索引不能包括重複詞,則為0。可以,則為1。
Key_name:索引的名稱。 索引中的列序列號,從1開始。 列名稱 列以什麼方式儲存在索引中。在MySQL中,有值‘A’(升序)或NULL(無分類)。 索引中唯一值的數目的估計值。通過執行ANALYZE TABLE或myisamchk -a可以更新。基數根據被儲存為整數的統計資料來計數,所以即使對於小型表,該值也沒有必要是精確的。基數越大,當進行聯合時,MySQL使用該索引的機 會就越大。 |
二、驗證Mysql的主鍵會自動建立索引? 建立一個沒有主鍵的ttx_index資料庫表:
 查詢索引:
查詢索引:
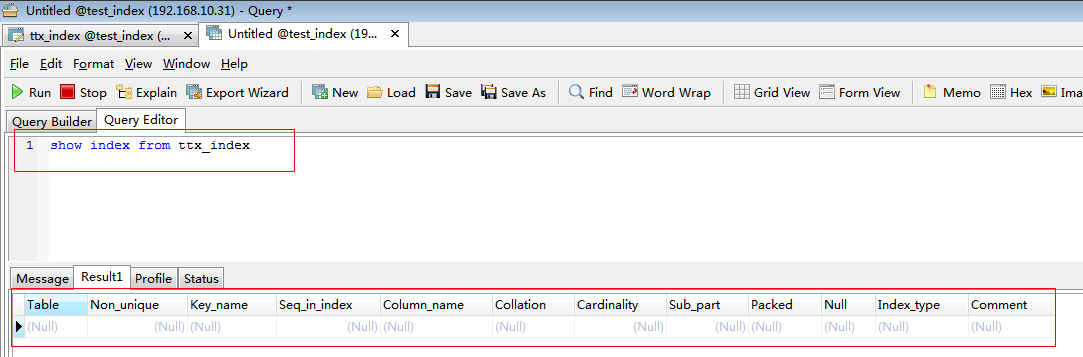 結果顯示沒有索引。
改變ttx_index資料庫表字段id,將之設為主鍵,再次查詢索引:
結果顯示沒有索引。
改變ttx_index資料庫表字段id,將之設為主鍵,再次查詢索引:
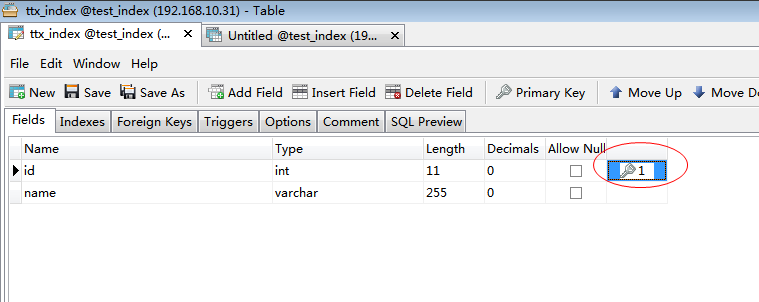
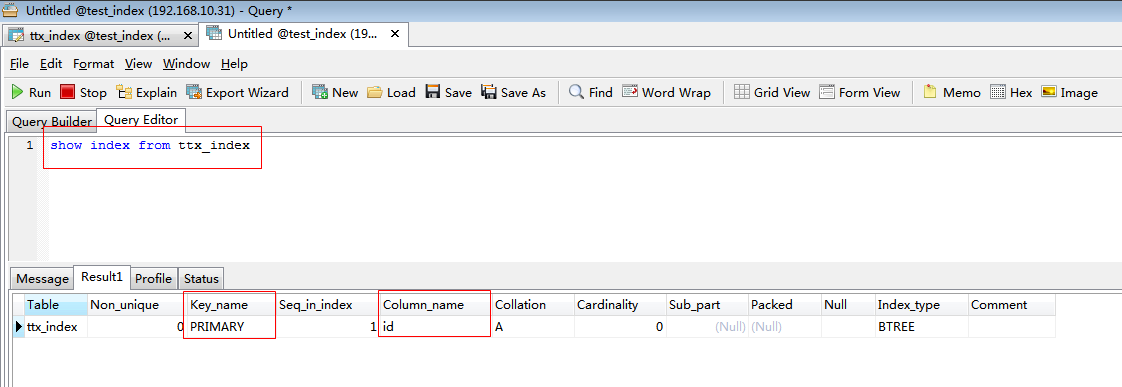 得出結論,在Mysql中,資料庫主鍵會自動建立索引。
三、Mysql效能優化利器:explain
得出結論,在Mysql中,資料庫主鍵會自動建立索引。
三、Mysql效能優化利器:explain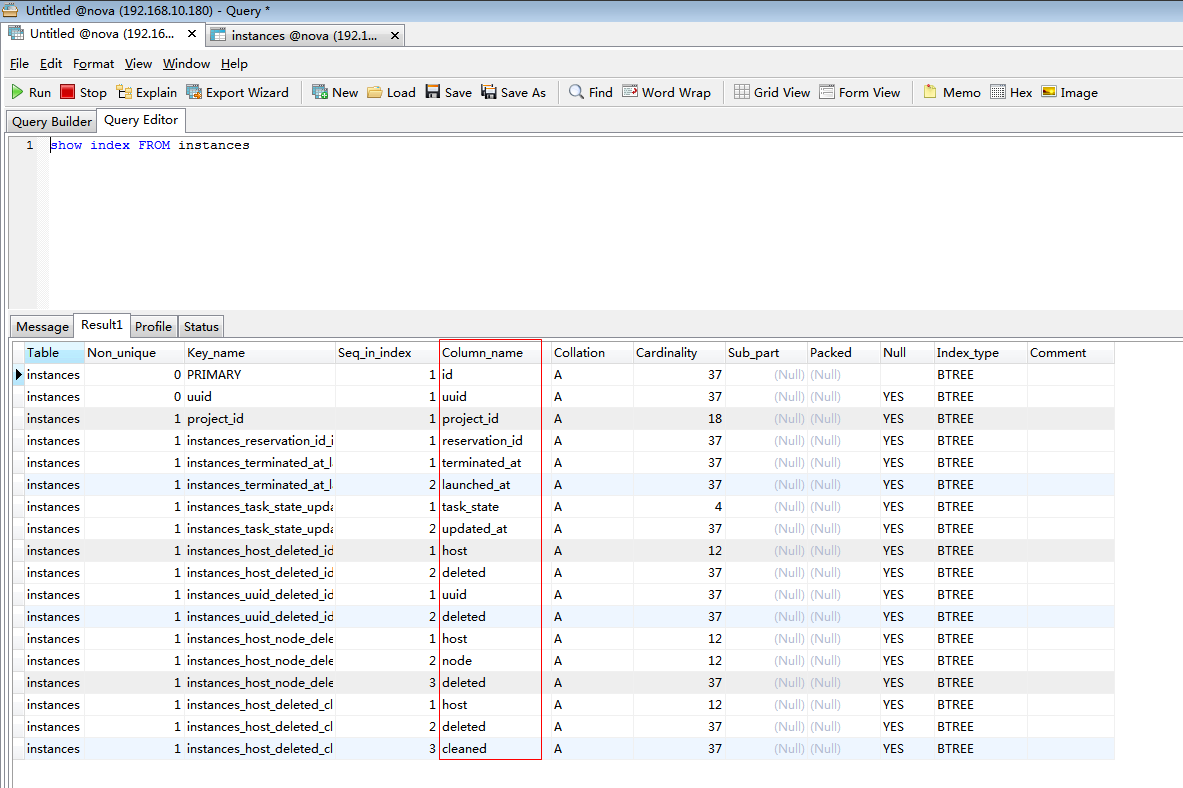 2、EXPLAIN 用法詳解:
2、EXPLAIN 用法詳解:
| EXPLAIN SELECT * FROM instances |
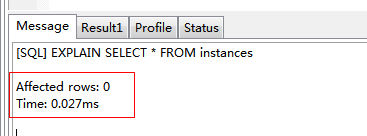
 根據上述結果,可以此查詢花了0.027ms,沒有可用的索引。
explain欄位詳解:
根據上述結果,可以此查詢花了0.027ms,沒有可用的索引。
explain欄位詳解:
|
table:顯示這一行的資料是關於哪張表的 type:這是重要的列,顯示連線使用了何種型別。從最好到最差的連線型別為const、eq_reg、ref、range、indexhe和ALL possible_keys:顯示可能應用在這張表中的索引。如果為空,沒有可能的索引。可以為相關的域從WHERE語句中選擇一個合適的語句 key: 實際使用的索引。如果為NULL,則沒有使用索引。很少的情況下,MYSQL會選擇優化不足的索引。這種情況下,可以在SELECT語句中使用USE INDEX(indexname)來強制使用一個索引或者用IGNORE INDEX(indexname)來強制MYSQL忽略索引 key_len:使用的索引的長度。在不損失精確性的情況下,長度越短越好 ref:顯示索引的哪一列被使用了,如果可能的話,是一個常數 rows:MYSQL認為必須檢查的用來返回請求資料的行數 Extra:關於MYSQL如何解析查詢的額外資訊。將在下表中討論,但這裡可以看到的壞的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,結果是檢索會很慢 extra列返回的描述的意義:
|
| EXPLAIN SELECT * FROM instances WHERE id=1 |
 從上圖可以,該sql語句走了索引。因為該表中id為主鍵,mysql會自動建立索引,因此當將id作為where條件查詢時,資料庫會自動走索引。
接下來實驗,當不走索引還是查詢id=1這條資料時候,會是如何?
從上圖可以,該sql語句走了索引。因為該表中id為主鍵,mysql會自動建立索引,因此當將id作為where條件查詢時,資料庫會自動走索引。
接下來實驗,當不走索引還是查詢id=1這條資料時候,會是如何?
| SELECT id, display_name FROM instances WHERE id=1 |
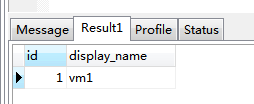
| EXPLAIN SELECT * FROM instances WHERE display_name = "vm1" |
 結論:在查詢時候,如果where條件中的欄位有索引(走不走索引,取決於where條件中的欄位),在執行sql語句時,mysql會自動走索引。
但是有個問題是,在走不走索引,查詢花費時間都是0.001ms,似乎沒有得到效能提高?
結論:在查詢時候,如果where條件中的欄位有索引(走不走索引,取決於where條件中的欄位),在執行sql語句時,mysql會自動走索引。
但是有個問題是,在走不走索引,查詢花費時間都是0.001ms,似乎沒有得到效能提高?
| SELECT COUNT(*) FROM instances |
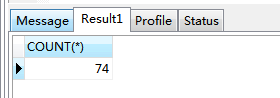 在資料庫表中instance資料總條數才74條,因此索引沒法發揮它的效能優勢,接下來人為製造上w條資料:
在資料庫表中instance資料總條數才74條,因此索引沒法發揮它的效能優勢,接下來人為製造上w條資料:
| insert instances(display_name) select display_name from instances |
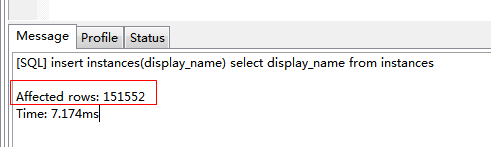 再次查詢總條數:
再次查詢總條數:
| SELECT COUNT(*) FROM instances |
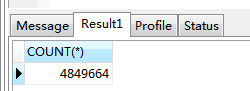 這次資料已經有接近500w了。
再次驗證上述索引效能問題:
1、為了對比的真實性,將id=1的資料記錄的display_name修改為唯一名字test_index_dispaly_name
這次資料已經有接近500w了。
再次驗證上述索引效能問題:
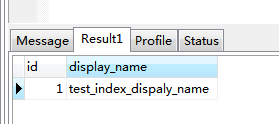
1、為了對比的真實性,將id=1的資料記錄的display_name修改為唯一名字test_index_dispaly_name
| SELECT id, display_name FROM instances WHERE id=1 |
 2、不走索引查詢:
2、不走索引查詢:
| SELECT * FROM instances WHERE display_name = 'test_index_dispaly_name' |
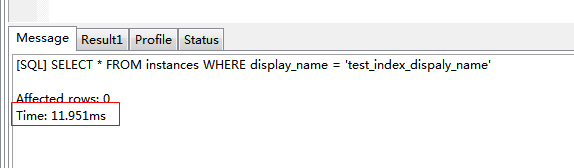 3、通過id走索引查詢:
3、通過id走索引查詢:
| SELECT * FROM instances WHERE id=1 |
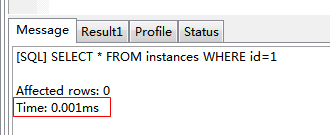 結論:對於百萬上億級資料,走不走索引效率影響相當明顯(效率差別都到萬了)。
4、哪些情況sql不會走索引?
結論:對於百萬上億級資料,走不走索引效率影響相當明顯(效率差別都到萬了)。
4、哪些情況sql不會走索引?
| 時間關係,此處暫且未總結,後續有時間補上。若有需要請自行網上查詢。 |