
hadoop開發必讀:認識Context類的作用
阿新 • • 發佈:2019-02-04
問題導讀:
1.Context能幹什麼?
2.你對Context類瞭解多少?
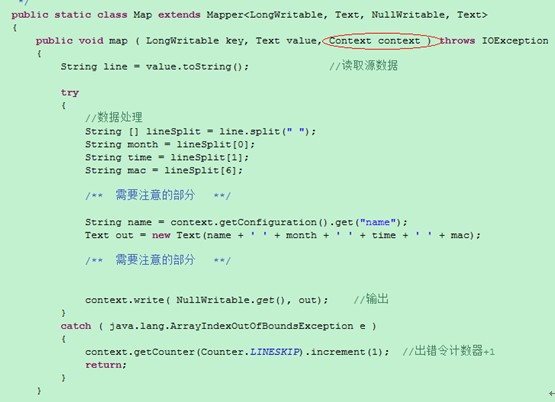

區別在於第一個程式把context這個上下文物件作為map函式的引數傳到map函式中,第二個程式則是在setup函式中處理了context物件,從這個角度講,在Map類的例項中是可以拿到Context這個上下文物件的,這一點是毋庸置疑的,不管是在類內部的哪個函式中使用都可以,既然是這樣,那麼討論的重點就是map這個類中方法的宣告及執行了,所以分析下Mapper類的原始碼:
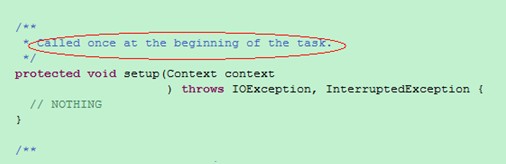
在mapper類中,只對這個方法進行了宣告,也就是說它的子類可以重新實現這個方法,這一點很容易理解的。
下面從原始碼級分析下整個mapper類的結構和hadoop在設計這個類時的巧妙之處:
Map的主要任務就是把輸入的key value轉換為指定的中間結果(其實也是key value),這個類主要包括了四個函式:

Setup一般是在執行map函式前做一些準備工作,map是主要的資料處理函式,cleanup則是在map執行完成後做一些清理工作和finally字句的作用很像,下面看一下run方法:

這個方法呼叫了上面的三個函式,組成了setup-map-cleanup這樣的執行序列,這一點和設計模式中的模版模式很類似,當然在這裡我們也可以改寫它的原始碼,比如可以在map的時候增加多執行緒,這樣可以對map任務做進一步的優化,從以上的分析可以很清楚的知道setup函式的作用了。
下面為run方法
從上面run方法可以看出,K/V對是從傳入的Context獲取的。我們也可以從下面的map方法看出,輸出結果K/V對也是通過Context來完成的。

那麼上文中提到的Context物件是怎麼回事呢?
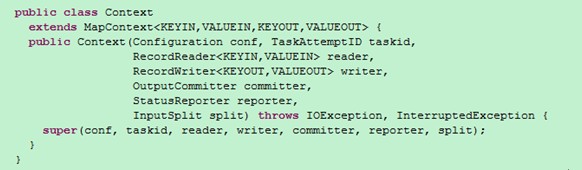
原來它是mapper的一個內部類,簡單的說頂級介面是為了在map或是reduce任務中跟蹤task的狀態,很自然的MapContext就是記錄了map執行的上下文,在mapper類中,這個context可以儲存一些job conf的資訊,比如習題一中的執行時引數等,我們可以在map函式中處理這個資訊,這也是hadoop中引數傳遞中一個很經典的例子,同時context作為了map和reduce執行中各個函式的一個橋樑,這個設計和java web中的session物件、application物件很相似。
1.Context能幹什麼?
2.你對Context類瞭解多少?
3.Context在mapreduce中的作用是什麼?
下面我們通過來原始碼,來得到Context的作用:
區別在於第一個程式把context這個上下文物件作為map函式的引數傳到map函式中,第二個程式則是在setup函式中處理了context物件,從這個角度講,在Map類的例項中是可以拿到Context這個上下文物件的,這一點是毋庸置疑的,不管是在類內部的哪個函式中使用都可以,既然是這樣,那麼討論的重點就是map這個類中方法的宣告及執行了,所以分析下Mapper類的原始碼:
在mapper類中,只對這個方法進行了宣告,也就是說它的子類可以重新實現這個方法,這一點很容易理解的。
下面從原始碼級分析下整個mapper類的結構和hadoop在設計這個類時的巧妙之處:
Map的主要任務就是把輸入的key value轉換為指定的中間結果(其實也是key value),這個類主要包括了四個函式:
Setup一般是在執行map函式前做一些準備工作,map是主要的資料處理函式,cleanup則是在map執行完成後做一些清理工作和finally字句的作用很像,下面看一下run方法:
這個方法呼叫了上面的三個函式,組成了setup-map-cleanup這樣的執行序列,這一點和設計模式中的模版模式很類似,當然在這裡我們也可以改寫它的原始碼,比如可以在map的時候增加多執行緒,這樣可以對map任務做進一步的優化,從以上的分析可以很清楚的知道setup函式的作用了。
下面為run方法
-
/**
-
* Expert users can override this method for more complete control over the
-
* execution of the Mapper.
-
* @param context
-
* @throws IOException
-
*/
-
public void run(Context context) throws IOException, InterruptedException {
-
setup(context);
-
try {
-
while (context.nextKeyValue()) {
-
map(context.getCurrentKey(), context.getCurrentValue(), context);
-
}
-
} finally {
-
cleanup(context);
-
}
- }
從上面run方法可以看出,K/V對是從傳入的Context獲取的。我們也可以從下面的map方法看出,輸出結果K/V對也是通過Context來完成的。
那麼上文中提到的Context物件是怎麼回事呢?
原來它是mapper的一個內部類,簡單的說頂級介面是為了在map或是reduce任務中跟蹤task的狀態,很自然的MapContext就是記錄了map執行的上下文,在mapper類中,這個context可以儲存一些job conf的資訊,比如習題一中的執行時引數等,我們可以在map函式中處理這個資訊,這也是hadoop中引數傳遞中一個很經典的例子,同時context作為了map和reduce執行中各個函式的一個橋樑,這個設計和java web中的session物件、application物件很相似。