
canal原始碼分析——parse模組原始碼分析
高層類圖
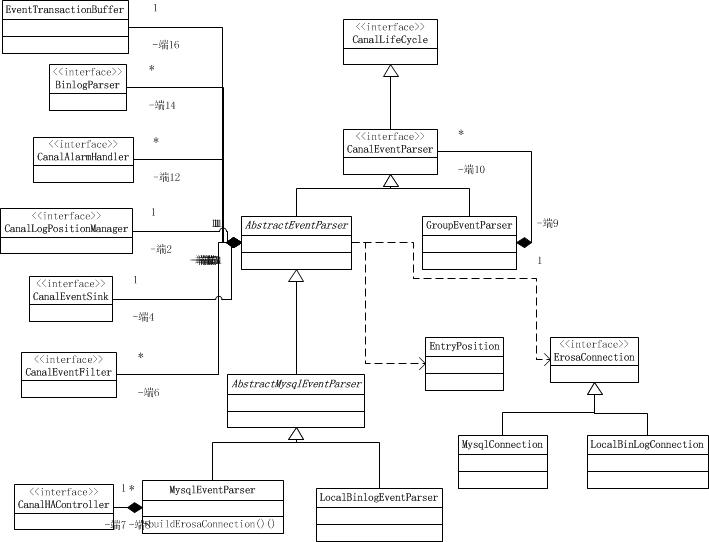
首先,我們來看看該模組下面的類圖,通過類圖就可以清晰地掌握整個模組的骨架結構。
EventTransactionBuffer是事件事務快取區。它主要是在記憶體中開闢一個緩衝區,避免過高的flush頻率導致的IO次數過度而導致的效能問題。
CanalEventParser是資料複製的控制器。該介面是核心的資料複製介面。
CanalLogPositionManager是日誌的位置管理器。提供了讀取和儲存當前日誌位置的介面。
CanalHAController是高可用的複製控制器。
圖中所有介面都實現了CanalLifeCycle(生命週期介面)。
AbstractEventParser是一個模板方法的抽閒實現類,它 最大化共用mysql/oracle版本的實現類,提供了一些抽象方法交給子類實現。
AbstractMysqlEventParser是抽象的MySQL日誌複製控制器的模板類。共享了MySQL的日誌複製控制實現。
LocalBinlogEventParser是基於本地MySQL的binlog檔案的複製控制器實現類。
MysqlEventParser是基於向mysql server複製binlog實現類。該實現類是MySQL使用最多的一種實現方式。
GroupEventParser是合多個EventParser進行合併處理,group只是做為一個delegate處理。它是一個組合模式的實現。
從上圖所示可以看出,canal專案並未實現oracle資料庫的日誌複製器的實現,也就是不支援oracle資料庫。
MysqlEventParser時序圖
從類圖中的介紹可以看出MysqlEventParser 是我們最核心的一個實現類,本文將重點描述該類的一個時序。

AbstractEventParser類原始碼解析
該類似parse模組中最核心的一個類, 它是一個事件解析的一個模板方法類,定義了事件解析的一個公共流程,幾乎所有的子類都是擴充套件自該類的,因此閱讀該類能夠掌握最核心的binlog事件解析流程。
解析器物件例項化
public AbstractEventParser(){
// 初始化一下
transactionBuffer = new EventTransactionBuffer(new TransactionFlushCallback() {
public void flush(List<CanalEntry.Entry> transaction) throws InterruptedException {
boolean successed = consumeTheEventAndProfilingIfNecessary(transaction);
if (!running) {
return;
}
if (!successed) {
throw new CanalParseException("consume failed!");
}
LogPosition position = buildLastTransactionPosition(transaction);
if (position != null) { // 可能position為空
logPositionManager.persistLogPosition(AbstractEventParser.this.destination, position);
}
}
});
} 首先看上述程式碼,它是構造方法中的程式碼,例項化本物件的同時,也例項化了一個EventTransactionBuffer物件。傳入了一個TransactionFlushCallback的回撥匿名類物件。回撥類中定義了一個flush方法,該方法實現的內容是先消費事件,如果消費成功了,則儲存當前的position。如果消費失敗則丟擲異常資訊。EventTransactionBuffer寫緩衝區的使用,是一種應對高併發的手段,它相當於在記憶體中收集一個個的事件,然後再批量的呼叫flush方法。這個與日誌中的實現是一樣的。
啟動解析器方法
public void start() {
super.start();
MDC.put("destination", destination);
// 配置transaction buffer
// 初始化緩衝佇列
transactionBuffer.setBufferSize(transactionSize);// 設定buffer大小
transactionBuffer.start();
// 構造bin log parser
binlogParser = buildParser();// 初始化一下BinLogParser
binlogParser.start();
// 啟動工作執行緒
parseThread = new Thread(new Runnable() {
public void run() {
MDC.put("destination", String.valueOf(destination));
ErosaConnection erosaConnection = null;
while (running) {
try {
// 開始執行replication
// 1. 構造Erosa連線
erosaConnection = buildErosaConnection();
// 2. 啟動一個心跳執行緒
startHeartBeat(erosaConnection);
// 3. 執行dump前的準備工作
preDump(erosaConnection);
erosaConnection.connect();// 連結
// 4. 獲取最後的位置資訊
final EntryPosition startPosition = findStartPosition(erosaConnection);
if (startPosition == null) {
throw new CanalParseException("can't find start position for " + destination);
}
logger.info("find start position : {}", startPosition.toString());
// 重新連結,因為在找position過程中可能有狀態,需要斷開後重建
erosaConnection.reconnect();
final SinkFunction sinkHandler = new SinkFunction<EVENT>() {
private LogPosition lastPosition;
public boolean sink(EVENT event) {
try {
CanalEntry.Entry entry = parseAndProfilingIfNecessary(event);
if (!running) {
return false;
}
if (entry != null) {
exception = null; // 有正常資料流過,清空exception
transactionBuffer.add(entry);
// 記錄一下對應的positions
this.lastPosition = buildLastPosition(entry);
// 記錄一下最後一次有資料的時間
lastEntryTime = System.currentTimeMillis();
}
return running;
} catch (TableIdNotFoundException e) {
throw e;
} catch (Exception e) {
// 記錄一下,出錯的位點資訊
processError(e,
this.lastPosition,
startPosition.getJournalName(),
startPosition.getPosition());
throw new CanalParseException(e); // 繼續丟擲異常,讓上層統一感知
}
}
};
// 4. 開始dump資料
if (StringUtils.isEmpty(startPosition.getJournalName()) && startPosition.getTimestamp() != null) {
erosaConnection.dump(startPosition.getTimestamp(), sinkHandler);
} else {
erosaConnection.dump(startPosition.getJournalName(),
startPosition.getPosition(),
sinkHandler);
}
} catch (TableIdNotFoundException e) {
exception = e;
// 特殊處理TableIdNotFound異常,出現這樣的異常,一種可能就是起始的position是一個事務當中,導致tablemap
// Event時間沒解析過
needTransactionPosition.compareAndSet(false, true);
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
} catch (Throwable e) {
exception = e;
if (!running) {
if (!(e instanceof java.nio.channels.ClosedByInterruptException || e.getCause() instanceof java.nio.channels.ClosedByInterruptException)) {
throw new CanalParseException(String.format("dump address %s has an error, retrying. ",
runningInfo.getAddress().toString()), e);
}
} else {
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
sendAlarm(destination, ExceptionUtils.getFullStackTrace(e));
}
} finally {
// 重新置為中斷狀態
Thread.interrupted();
// 關閉一下連結
afterDump(erosaConnection);
try {
if (erosaConnection != null) {
erosaConnection.disconnect();
}
} catch (IOException e1) {
if (!running) {
throw new CanalParseException(String.format("disconnect address %s has an error, retrying. ",
runningInfo.getAddress().toString()),
e1);
} else {
logger.error("disconnect address {} has an error, retrying., caused by ",
runningInfo.getAddress().toString(),
e1);
}
}
}
// 出異常了,退出sink消費,釋放一下狀態
eventSink.interrupt();
transactionBuffer.reset();// 重置一下緩衝佇列,重新記錄資料
binlogParser.reset();// 重新置位
if (running) {
// sleep一段時間再進行重試
try {
Thread.sleep(10000 + RandomUtils.nextInt(10000));
} catch (InterruptedException e) {
}
}
}
MDC.remove("destination");
}
});
parseThread.setUncaughtExceptionHandler(handler);
parseThread.setName(String.format("destination = %s , address = %s , EventParser",
destination,
runningInfo == null ? null : runningInfo.getAddress().toString()));
parseThread.start();
}start()方法是實現了生命週期的啟動方法,是被上層的元件呼叫的,parser元件的start方法應該是被instance元件呼叫的。該方法開始啟動元件,接收binlog,並且解析處理它。該方法的流程是這樣的。
- 初始化並啟動transactionBuffer元件。
- 構造binlogParser元件,並啟動它。
- 開啟新的執行緒並啟動它。避免阻塞上級元件的啟動。
- 開啟迴圈,直到終止元件執行。判斷標誌是protected volatile boolean running = false。定義為volatile修飾的成員變數,讓多執行緒可見。
- 構造erosa連線。
- 啟動一個心跳執行緒。用Timer實現。會定期消費一個事件型別為EntryType.HEARTBEAT的事件。應該是告知下游元件,上有元件還活著。
- dump資料庫複製日誌前的準備處理。
- erosa連線建立連線。
- 查詢日誌起始位置。
- erosa連線重建連線。因為在找position過程中可能有狀態,需要斷開後重建
- 開始dump資料庫複製日誌。傳入一個回撥的SinkFunction匿名類物件。回撥方法sink的實現就是解析dump到的日誌事件,將其轉化為Entry物件。並強Entry物件加入到緩衝區transactionBuffer中,並且記錄當前日誌位置和時間。
- 最後dump後的處理。關閉連線等事後處理。
- 若未停止執行,則再次進入第一步。
問題是:沒做一次dump之後,就會進入一次迴圈,會再次建立和連線,這樣連線就無法複用,高併發效能豈不是很差,伺服器壓力也非常大呢?這個問題從原始碼開起來是有些問題,先記錄下來,後面通過檢視其它部分原始碼和除錯就能得到答案了。
經過排查dump方法內部的實現,發現該方法內部是會阻塞的,當連線的緩衝區中沒有新的內容的情況下,會阻塞請求,等待資料。因此連線是可以被複用的。