
BeautifulSoup 提取某個tag標籤裡面的內容
阿新 • • 發佈:2019-02-04
用的版本是BeautifulSoup4,用起來的確要比 re 好用一些,不用一個個的去寫正則表示式,這樣還是挺方便的。
比如我要獲取高匿代理IP頁面上的IP和埠,網址這裡:點選開啟連結,它的組織方式是這樣的,如下圖:
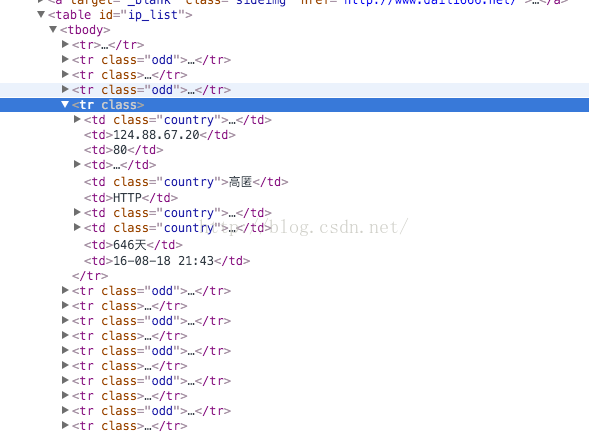
IP和埠 tr.td 標籤裡面,tr有class屬性,屬性有兩種情況的值,對於這點我們可以用正則表示式來匹配下。當提取某一個標籤裡的具體內容時,可以用bs的 .string屬性,注意:用 .string 屬性來提取標籤裡的內容時,該標籤應該是隻有單個節點的。比如上面的 td 標籤那樣。下面直接上程式碼了。
import requests from bs4 import BeautifulSoup import re import os.path user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)' headers = {'User-Agent': user_agent} session = requests.session() page = session.get("http://www.xicidaili.com/nn/1", headers=headers) soup = BeautifulSoup(page.text,'lxml') #這裡沒有裝lxml的話,把它去掉用預設的就好 #匹配帶有class屬性的tr標籤 taglist = soup.find_all('tr', attrs={'class': re.compile("(odd)|()")}) for trtag in taglist: tdlist = trtag.find_all('td') #在每個tr標籤下,查詢所有的td標籤 print tdlist[1].string #這裡提取IP值 print tdlist[2].string #這裡提取埠值
結果如下:
124.88.67.24
80
61.224.239.71
8080
113.3.78.124
8118
61.227.228.141
8080
222.130.171.58
8118
123.57.190.51
7777
183.61.71.112
8888
120.25.171.183
8080
1.164.146.91
8080
101.201.235.141
8000
121.193.143.249
80
118.180.15.152
8102
124.88.67.19
80
。
。
。
。
。
。
。