【Memcached】原理、體系架構、基本操作及路由演算法
1. 什麼是Memcached
要了解Memcached首先要到官網上去看官方對它的描述。Memcached的官網網站是:http://memcached.org/,官方對Memcached的描述如下圖:
從官方的描述中可以總結出,Memcached是一個高效能分散式的記憶體物件快取系統。它將資料以key-value形式儲存的儲存在記憶體中,極大的提高了效率。但是Memcached的缺點在於不支援持久化(不支援寫入磁碟),所以一旦斷電,記憶體中的全部資料都會丟失。而Redis彌補了這個缺點,既在記憶體中存取資料,又支援持久化,所以Memcached可以理解為是Redis的前身,關於Redis的技術,後續會發新的文章論述,這裡不展開討論。
2. Memcached基本原理和體系架構
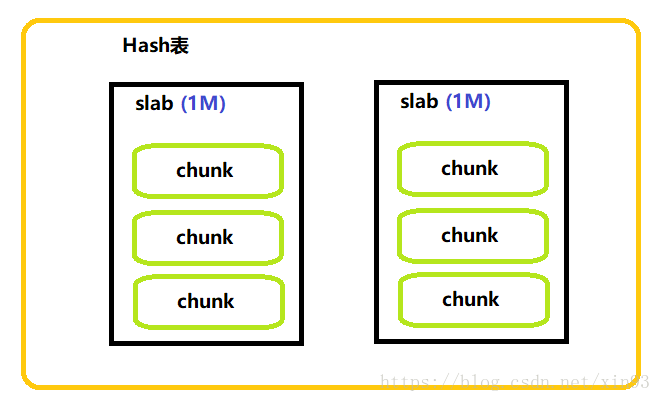
實際上,Memcached是在記憶體中維護一張巨大的Hash表。這張Hash表的結構是由多個slab組成,每個slab的大小是1M;每個slab中存在多個chunk,chunk是資料最終儲存的單位。chunk採用預分配的方式提高效能,在儲存資料之前,需要制定chunk的大小來分配記憶體。如add key *** 3
3. Memcached 叢集
3.1 背景
Memcached官方版本不支援叢集搭建,Memcached彼此之間不進行通訊,也就是把一個數據存到一個Memcached上,一旦這個Memcached宕掉了,不能從其它Memcached上讀取這些資料,會造成資料丟失。
但是,一個日本工程師改寫了官方Memcached,使它能夠支援叢集。此時,Memcached之間可以進行通訊,資料儲存到一個Memcached例項上,可以同步到其它Memcached例項,防止資料丟失。
3.2 基本操作
3.2.1 命令列
(1) 啟動並連線memcached

(2) 新增資料:set、add(當存在相同key值時,set會覆蓋value,add會報錯);獲取資料:get
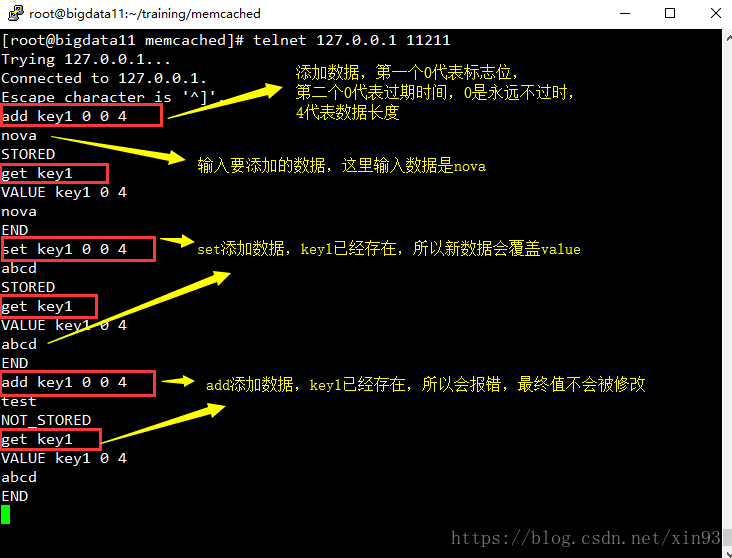
(2) 檢視slab資訊

3.2.2 JavaAPI
2. 建立一個簡單的Person資訊類,用於儲存到Memcached。
package com.nova; import java.io.Serializable; /** * * @author Supernova * @date 2018/06/16 * */ public class Person implements Serializable{ private String name; //姓名 private String sex; //性別 public Person() { } public Person(String name, String sex) { super(); this.name = name; this.sex = sex; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } }
3. 新增、獲取
package com.nova;
import java.net.InetSocketAddress;
import java.util.concurrent.Future;
import org.junit.Test;
import net.spy.memcached.MemcachedClient;
/**
*
* @author Supernova
* @date 2018/06/16
*
*/
public class MemcachedOperation {
/*
* 向memcached新增資料
*/
@Test
public void addData() throws Exception {
// 建立Memcached客戶端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11", 11211));
// 插入資料
Future<Boolean> future= client.set("name", 0, "Supernova");
//判斷執行操作後返回的Boolean值
if(future.get().booleanValue()) {
//插入成功
client.shutdown();
}
}
/*
* 獲取memcached資料
*/
@Test
public void getData() throws Exception{
// 建立Memcached客戶端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11",11211));
// 獲取對應key值的value
String name = client.get("name").toString();
System.out.println(name);
}
/*
* 向memcached儲存一個物件
*/
@Test
public void insertObject() throws Exception{
// 建立Memcached客戶端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11",11211));
Person person = new Person("Supernova","man");
// 插入物件
Future<Boolean> future = client.set("person", 0, person);
if(future.get().booleanValue()) {
//插入成功
client.shutdown();
}
}
}
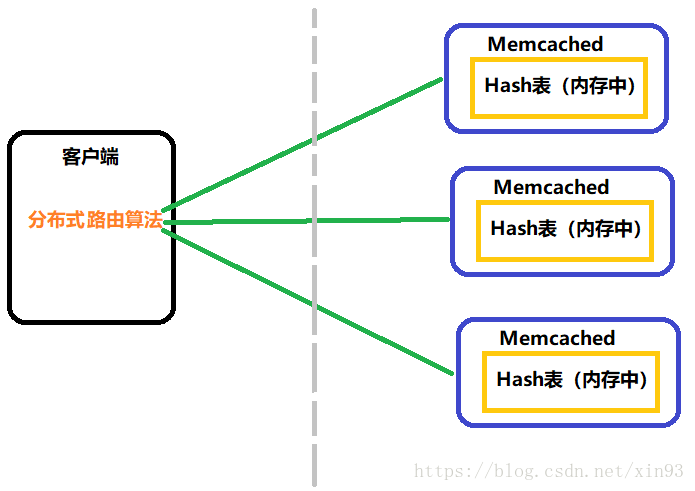
3.2 路由演算法
既然Memcached例項可以有多個,那麼當客戶端傳送一條資料的時候,這條資料要儲存到哪個Memcached例項中?所以這就涉及到了Memcached路由演算法,由它來決定資料最終儲存在哪個Memcached上。注意:Memcached路由演算法是由客戶端實現的。在Memcached中有兩種路由演算法
3.2.1 求餘數
【基本原理】將key做hash運算,對memcached數量進行求餘數,根據餘數來決定儲存到哪個Memcached例項。
如:有 4 臺Memached,將對4進行求餘數
8%4 = 0
7%4 = 3
6%4 = 2
5%4 = 1
……
這樣根據餘數路由的優點在於,能夠使資料均勻分佈在每個Memcached上,但是也有很大的缺點,一旦某個Memcached宕機,或有新的memcached加入就會找不到資料,出現嚴重的資料丟失。
【資料丟失的原因】:
比如原先有3個Memcached:1%3=1, 2%3=2, 3%3=0, 4%3=1,……
新增之後為4個Memcached:1%4=1, 2%4=2, 3%4=2, 4%4=0,……
原先3存在0號,4存在1號,但是新增後,3變成2號,4變成0號。導致了存取的目標位置不一樣,在0號存,去2號取就會找不到資料。
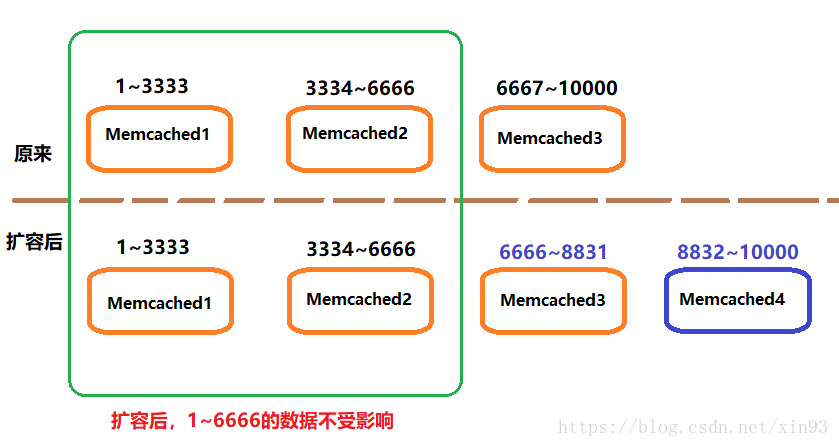
3.2.2 一致性Hash
一致性hash能夠將丟失的資料減小到最小,但不能完全解決宕機造成的資料丟失。
【基本原理】:
如下圖所示,資料分段在Memcached上儲存,當擴容的時候,1~6666的資料將不受影響。同理,當有機器宕機的時候也一樣。