
Flask 資料庫多對多關係
社交Web程式允許使用者之間相互聯絡,在程式中,這種關係成為關注者、好友、聯絡人、聯絡人或夥伴,但不管使用哪個名字,其功能都是一樣的,而且都要記錄兩個使用者之間的定向聯絡,在資料庫查詢中也要使用這種聯絡
再論資料庫關係
之前我們說過,資料庫使用關係建立記錄之間的聯絡,其中,一對多關係是最常用的關係型別,它把一個記錄和一組相關的記錄聯絡在一起,實現這種關係時,要在“多”這個側加入一個外來鍵,指向“一”這一側聯結的記錄,目前我們的程式現在包含兩個一對多關係:一個把使用者角色和一組使用者聯絡起來,另一個把使用者和釋出的部落格文章聯絡起來
大部分的其他關係型別都可以從一對多型別中衍生,多對一關係從“多”這一側看就是一對多關係,一對一關係型別是簡化版的一對多關係,限制多這一側最多隻能有一個記錄,唯一不能從一對多關係中簡單演化出來的型別是多對多
多對多關係
一對多關係、多對一關係和一對一關係至少都有一側是單個實體,所以記錄之間的聯絡通過外來鍵實現,讓外來鍵指向這個實體,但是我們要怎麼實現兩側都是“多”的關係呢
下面以一個典型的多對多關係為例,即一個記錄學生和他們所選課程的資料庫,很顯然,你不能在學生表中加入一個指向課程的外來鍵,因為一個學生可以選擇多個課程,一個外來鍵不夠用,同樣,你也不能在課程表中加入一個指向學生的外來鍵,因為一個課程有多個學生的選擇,兩側都需要一組外來鍵
這種問題的解決方法是新增第三張表,這個表稱為關聯表,現在,多對多的關係可以分解成原表和關聯表之間的兩個一對多關係,下圖描繪了學生和課程之間的多對多關係
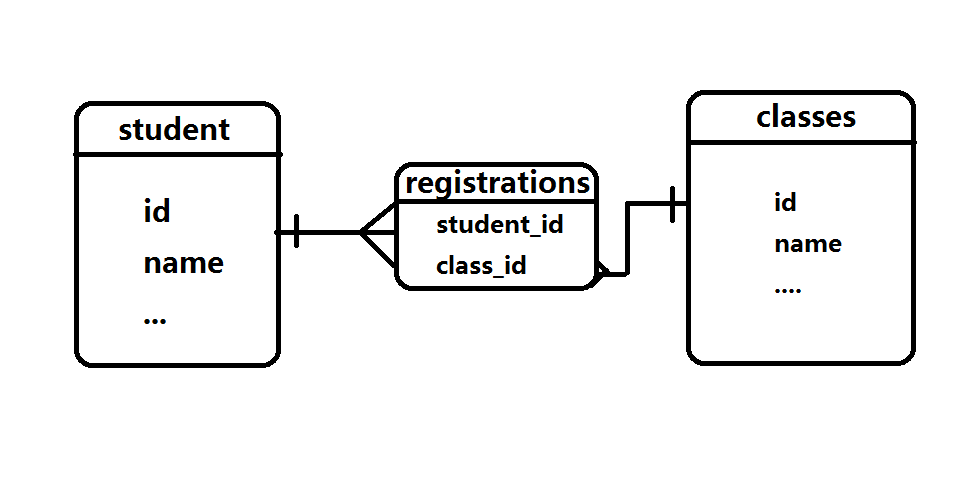
這個例子中的關聯表是registrations,表中每一行都表示一個學生註冊的一個課程
查詢多對多關係要分成兩步,若想知道某位學生選擇了哪些課程,要先從學生和註冊之間的一對多關係開始,獲取這位學生在registrations表中的所有記錄,然後再按照多到一的方向遍歷課程和註冊之間的一對多關係,找到這位學生在registrations表中個記錄所對應的課程,同樣,若想找到選擇了某門課程的所有學生,要先從課程表中開始,獲取其在registrations表中的記錄,再獲取這些記錄聯接的學生
通過遍歷兩個關係來獲取查詢結果的做法聽起來有難度,不過像前例這種簡單關係,SQLAlchemy就可以完成大部分操作,多對多關係使用的程式碼如下:
registrations = db.Table('registrations',
db.Column('student_id', db.Integer, db.ForeignKey('students.id')),
db.Column('class_id', db.Integer, db.ForeignKey('classes.id'))
)
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
name =db.Column(db.String)
classes = db.relationship('Class',
secondary=registrations,
backref=db.backref('students', lazy='dynamic'),
lazy='dynamic')
class Class(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
多對多關係仍使用定義一對多關係的db.relationship()方法進行定義,但在多對多關係中,必須把secondary引數設為關聯表,多對多關係可以在任何一個類中定義,backref引數會處理好關係的另一側,關聯表就是一個簡單的表,不是模型,SQLAlchemy會自動接管這個表,classes關係使用列表語義,這樣處理多對多關係特別簡單,假設學生是s,課程是c,學生註冊課程的程式碼是:
>>> s.classes.append(c)
>>> db.session.add(s)- 1
- 2
- 1
- 2
列出學生s註冊的課程以及註冊了課程c的學生也很簡單:
>>>s.classes.all()
>>>c.students.all()- 1
- 2
- 1
- 2
Class模型中的students關係由引數db.backref()定義,注意這個關係中還指定了lazy='dynamic'引數,所以關係兩側返回的查詢都可接受額外的過濾器
如果後來學生s決定不選課程c了,那麼可使用下面的程式碼更新資料庫:
>>> s.classes.remove(c)- 1
- 1
自引用關係
多對多關係可用於實現使用者之間的關注,但存在一個問題,在學生和課程的例子中,關聯表聯接的是兩個明確的實體,但是表示使用者關注其他使用者時,只有使用者一個實體,沒有第二個實體
如果關係中的兩側都在同一個表中,這種關係成為自引用關係,在關注中,關係的左側是使用者實體,可以稱為“關注者”,關係的右側也是使用者實體,但這些是”被關注者“,從概念上來看,自引用關係和普通關係沒什麼區別,只是不易理解,下圖是自引用關係的資料庫圖解,表示使用者之間的關注:
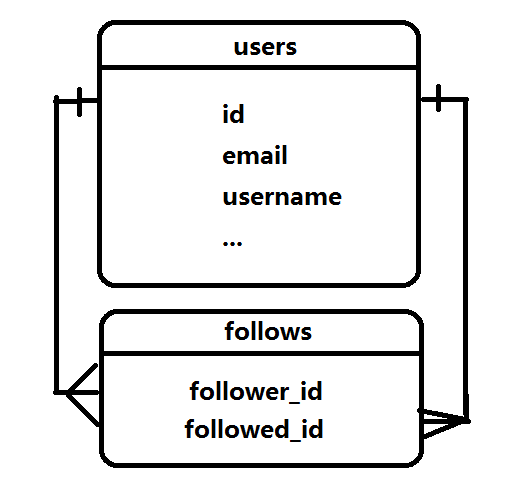
本例的關聯表是follows,其中每一行都表示一個使用者關注了另一個使用者,圖中左邊表示的一對多關係把使用者和follows表中的一組記錄聯絡起來,使用者是關注者,圖中右邊表示的一對多關係把使用者和follows表中的一組記錄聯絡起來,使用者是被關注者
高階多對多關係
自引用多對多關係可在資料庫中表示使用者之間的關注,但卻有個限制,使用多對多關係時,往往需要儲存所聯兩個實體之間的額外資訊,對使用者之間的關注來說,可以儲存使用者關注另一個使用者的日期,這樣就能按照時間順序列出所有的關注者,這種資訊只能儲存在關聯表中,但是在之前實現的學生和課程之間的關係中,關聯表完全是由SQLAlchemy掌控的內部表
為了能在關係中處理自定義的資料,我們必須提升關聯表的地位,使其變成程式可訪問的模型,新的關聯表如下,使用Follow模型表示:
# app/main/models.py
# ...
class Follow(db.Model):
__tablename__ = 'follows'
follower_id = db.Column(db.Integer, db.ForeignKey('users.id'),
primary_key=True)
followed_id = db.Column(db.Integer, db.ForeignKey('users.id'),
primary_key=True)
timestamp = db.Column(db.DateTime, default=datetime.utcnow)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
SQLAlchemy不能直接使用這個關聯表,因為如果這麼做程式就無法訪問其中的自定義欄位,相反地,要把這個多對多關係的左右兩側拆分成兩個基本的一對多關係,而且要定義成標準的關係,程式碼如下:
# app/models.py
class User(UserMixin, db.Model):
#...
followed = db.relationship('Follow',
foreign_keys=[Follow.follower_id],
backref=db.backref('follower', lazy='joined'),
lazy='dynamic',
cascade='all, delete-orphan')
followers = db.relationship('Follow',
foreign_keys=[Follow.followed_id],
backref=db.backref('followed', lazy='joined'),
lazy='dynamic',
cascade='all, delete-orphan')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在這段程式碼中,followed和followers關係都定義為單獨的一對多關係,為了消除外來鍵間的歧異,定義關係時必須使用可選引數foreign_keys指定的外來鍵,而且,db.backref()引數並不是指定這兩個關係之間的引用關係,而是回引Follow模型
回引中的lazy引數指定為joined,這個lazy模式可以實現立即從聯結查詢中載入相關物件,例如如果某個使用者關注了100個使用者,呼叫user.followed.all()後會返回一個列表,其中包含100個Follow例項,每一個例項的follower和followed回引屬性都指向相應的使用者,設定為lazy='joined'模式,就可在一次資料庫查詢中完成這些操作,如果把lazy設為預設值select,那麼首次訪問follower和followed屬性時才會載入對應的使用者,而且每個屬性都需要一個單獨的查詢,這就意味著獲取全部被關注使用者時需要增加100次額外的資料庫查詢
cascade引數配置在父物件上執行的操作對相關物件的影響,比如層疊選項可設定為:將使用者新增到資料庫會話後,要自動把所有關係的物件都新增到會話中,層疊選項的預設值能滿足大多數情況的需求,但對這個多對多關係來說卻不合用,刪除物件時,預設的層疊行為是把物件聯接的所有相關物件的外來鍵設為空值,但在關聯表中,刪除記錄後正確的行為應該是把指向該記錄的實體也刪除,因為這樣能有效銷燬聯接,這就是層疊選項值delete-orphan的作用
cascade引數的值是一組由逗號分隔的層疊選項,這看起來可能讓人有點困惑,但all表示除了delete-orphan之外的所有層疊選項,設為all,delete-orphan的意思是啟用所有預設層疊選項,還要刪除孤兒記錄
程式現在要處理兩個一對多關係,以便實現多對多關係,由於這些操作經常需要重複執行,所以最好在User模型中為所有可能的操作定義輔助方法,用於控制關係的4個新方法如下:
# app/models.py
class User(db.Model):
#....
def follow(self, user):
if not self.is_following(user):
f = Follow(follower=self, followed=user)
db.session.add(f)
def unfollow(self, user):
f = self.followed.filter_by(followed_id=user.id).first()
if f:
db.session.delete(f)
def is_following(self, user):
return self.followed.filter_by(followed_id=user.id).first() is not None
def is_followed_by(self, user):
return self.followers.filter_by(follower_id=user.id).first() is not None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
follow()方法手動把Follow例項插入關聯表,從而把關注者和被關注者聯接起來,並讓程式有機會設定自定義欄位的值,聯接在一起的兩個使用者被手動傳入Follow類的構造器,建立一個Follow新例項,然後像往常一樣,把這個例項物件新增到資料庫會話中,注意,這裡無需手動設定timestamp欄位,因為定義欄位時已經指定了預設值,即當前日期和時間,unfollow()方法使用followed關係找到聯接使用者和被關注使用者的Follow例項,若要銷燬這兩個使用者之間的聯接,只需刪除這個Follow物件即可,is_following()方法和is_followed_by()方法分別在左右兩邊的一對多關係中搜索指定使用者,如果找到了就返回True