
Apache Kylin優化之—Cube的高階設定
隨著維度數目的增加,Cuboid 的數量會爆炸式地增長。為了緩解 Cube 的構建壓力,Apache Kylin 引入了一系列的高階設定,幫助使用者篩選出真正需要的 Cuboid。這些高階設定包括聚合組(Aggregation Group)、聯合維度(Joint Dimension)、層級維度(Hierachy Dimension)和必要維度(Mandatory Dimension)等。”
眾所周知,Apache Kylin 的主要工作就是為源資料構建 N 個維度的 Cube,實現聚合的預計算。理論上而言,構建 N 個維度的 Cube 會生成 2N 個 Cuboid, 如圖 1 所示,構建一個 4 個維度(A,B,C, D)的 Cube,需要生成 16 個Cuboid。
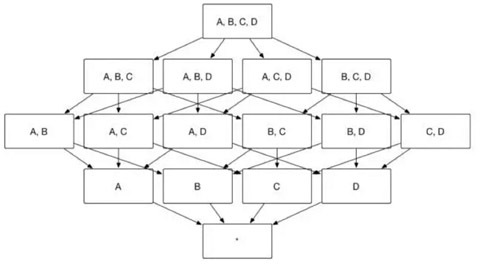
(圖1)
隨著維度數目的增加 Cuboid 的數量會爆炸式地增長,不僅佔用大量的儲存空間還會延長 Cube 的構建時間。為了緩解 Cube 的構建壓力,減少生成的 Cuboid 數目,Apache Kylin 引入了一系列的高階設定,幫助使用者篩選出真正需要的 Cuboid。這些高階設定包括聚合組(Aggregation Group)、聯合維度(Joint Dimension)、層級維度(Hierachy Dimension)和必要維度(Mandatory Dimension)等,本系列將深入講解這些高階設定的含義及其適用的場景。
聚合組(Aggregation Group)
使用者根據自己關注的維度組合,可以劃分出自己關注的組合大類,這些大類在 Apache Kylin 裡面被稱為聚合組。例如圖 1 中展示的 Cube,如果使用者僅僅關注維度 AB 組合和維度 CD 組合,那麼該 Cube 則可以被分化成兩個聚合組,分別是聚合組 AB 和聚合組 CD。如圖 2 所示,生成的 Cuboid 數目從 16 個縮減成了 8 個。
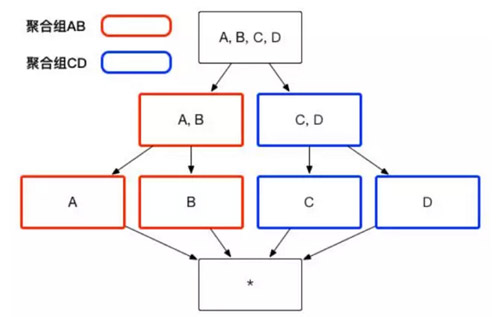
(圖2)
使用者關心的聚合組之間可能包含相同的維度,例如聚合組 ABC 和聚合組 BCD 都包含維度 B 和維度 C。這些聚合組之間會衍生出相同的 Cuboid,例如聚合組 ABC 會產生 Cuboid BC,聚合組 BCD 也會產生 Cuboid BC。這些 Cuboid不會被重複生成,一份 Cuboid 為這些聚合組所共有,如圖 3 所示。
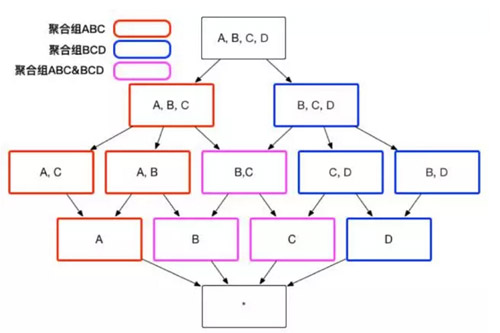
(圖3)
有了聚合組使用者就可以粗粒度地對 Cuboid 進行篩選,獲取自己想要的維度組合。
聚合組應用例項
假設建立一個交易資料的 Cube,它包含了以下一些維度:顧客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和買家所在的城市 city。有時候,分析師需要通過分組聚合 city、cal_dt 和 pay_type 來獲知不同消費方式在不同城市的應用情況;有時候,分析師需要通過聚合 city 、cal_dt 和 buyer_id,來檢視顧客在不同城市的消費行為。在上述的例項中,推薦建立兩個聚合組,包含的維度和方式如圖 4 :
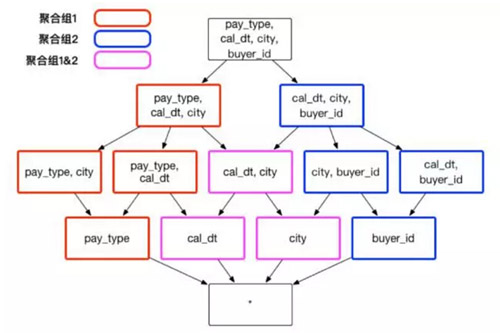
(圖4)
聚合組 1: [cal_dt, city, pay_type]
聚合組 2: [cal_dt, city, buyer_id]
在不考慮其他干擾因素的情況下,這樣的聚合組將節省不必要的 3 個 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,節省了儲存資源和構建的執行時間。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 則將從 Cuboid [cal_dt, city, pay_type] 中獲取資料。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 則將從 Cuboid [cal_dt, city, pay_type] 中獲取資料。
Case3 如果有一條不常用的查詢:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 則沒有現成的完全匹配的 Cuboid。
此時,Apache Kylin 會通過線上計算的方式,從現有的 Cuboid 中計算出最終結果。
聯合維度(Joint Dimension)
使用者有時並不關心維度之間各種細節的組合方式,例如使用者的查詢語句中僅僅會出現 group by A, B, C,而不會出現 group by A, B 或者 group by C 等等這些細化的維度組合。這一類問題就是聯合維度所解決的問題。例如將維度 A、B 和 C 定義為聯合維度,Apache Kylin 就僅僅會構建 Cuboid ABC,而 Cuboid AB、BC、A 等等Cuboid 都不會被生成。最終的 Cube 結果如圖5所示,Cuboid 數目從 16 減少到 4。
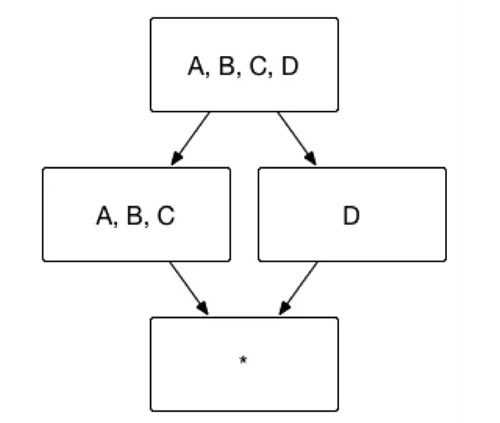
(圖5)
聯合維度應用例項
假設建立一個交易資料的Cube,它具有很多普通的維度,像是交易日期 cal_dt,交易的城市 city,顧客性別 sex_id 和支付型別 pay_type 等。分析師常用的分析方法為通過按照交易時間、交易地點和顧客性別來聚合,獲取不同城市男女顧客間不同的消費偏好,例如同時聚合交易日期 cal_dt、交易的城市 city 和顧客性別 sex_id來分組。在上述的例項中,推薦在已有的聚合組中建立一組聯合維度,包含的維度和組合方式如圖6:
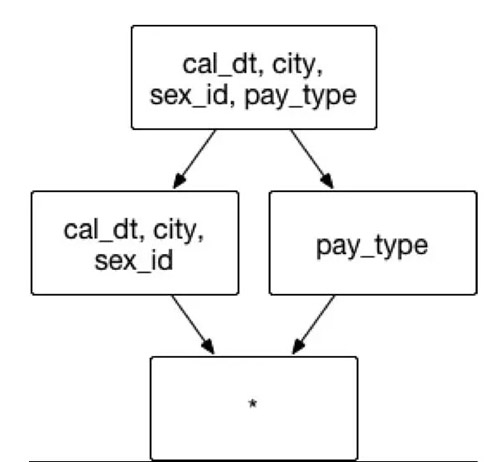
(圖6)
聚合組:[cal_dt, city, sex_id,pay_type]
聯合維度: [cal_dt, city, sex_id]
Case 1:
SELECT cal_dt, city, sex_id, count(*) FROM table GROUP BY cal_dt, city, sex_id 則它將從Cuboid [cal_dt, city, sex_id]中獲取資料
Case2如果有一條不常用的查詢:
SELECT cal_dt, city, count(*) FROM table GROUP BY cal_dt, city 則沒有現成的完全匹配的 Cuboid,Apache Kylin 會通過線上計算的方式,從現有的 Cuboid 中計算出最終結果。
層級維度(Hierarchy Dimension)
使用者選擇的維度中常常會出現具有層級關係的維度。例如對於國家(country)、省份(province)和城市(city)這三個維度,從上而下來說國家/省份/城市之間分別是一對多的關係。也就是說,使用者對於這三個維度的查詢可以歸類為以下三類:
group by country
group by country, province(等同於group by province)
group by country, province, city(等同於 group by country, city 或者group by city)
以圖7所示的 Cube 為例,假設維度 A 代表國家,維度 B 代表省份,維度 C 代表城市,那麼ABC 三個維度可以被設定為層級維度,生成的Cube 如圖7所示。
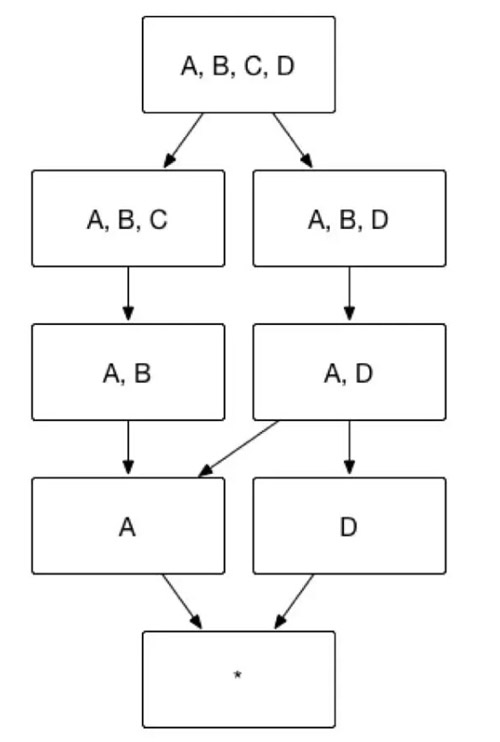
(圖7)
例如,Cuboid [A,C,D]=Cuboid[A, B, C, D],Cuboid[B, D]=Cuboid[A, B, D],因而 Cuboid[A, C, D] 和 Cuboid[B, D] 就不必重複儲存。
圖8展示了 Kylin 按照前文的方法將冗餘的Cuboid 剪枝從而形成圖 2 的 Cube 結構,Cuboid 數目從 16 減小到 8。
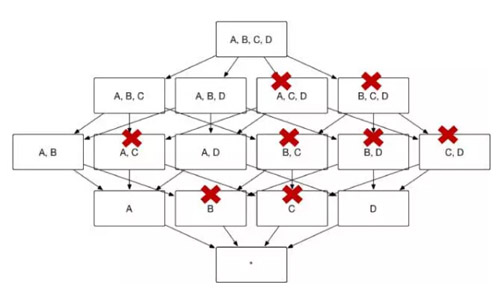
(圖8)
層級維度應用例項
假設一個交易資料的 Cube,它具有很多普通的維度,像是交易的城市 city,交易的省 province,交易的國家 country, 和支付型別 pay_type等。分析師可以通過按照交易城市、交易省份、交易國家和支付型別來聚合,獲取不同層級的地理位置消費者的支付偏好。在上述的例項中,建議在已有的聚合組中建立一組層級維度(國家country/省province/城市city),包含的維度和組合方式如圖9:

(圖9)
聚合組:[country, province, city,pay_type]
層級維度: [country, province, city]
Case 1 當分析師想從城市維度獲取消費偏好時:
SELECT city, pay_type, count(*) FROM table GROUP BY city, pay_type 則它將從 Cuboid [country, province, city, pay_type] 中獲取資料。
Case 2 當分析師想從省級維度獲取消費偏好時:
SELECT province, pay_type, count(*) FROM table GROUP BY province, pay_type 則它將從Cuboid [country, province, pay_type] 中獲取資料。
Case 3 當分析師想從國家維度獲取消費偏好時:
SELECT country, pay_type, count(*) FROM table GROUP BY country, pay_type 則它將從Cuboid [country, pay_type] 中獲取資料。
Case 4 如果分析師想獲取不同粒度地理維度的聚合結果時:
無一例外都可以由圖 3 中的 cuboid 提供資料 。
例如,SELECT country, city, count(*) FROM table GROUP BY country, city 則它將從 Cuboid [country, province, city] 中獲取資料。
必要維度 (Mandatory Dimension)
使用者有時會對某一個或幾個維度特別感興趣,所有的查詢請求中都存在group by這個維度,那麼這個維度就被稱為必要維度,只有包含此維度的Cuboid會被生成(如圖10)。
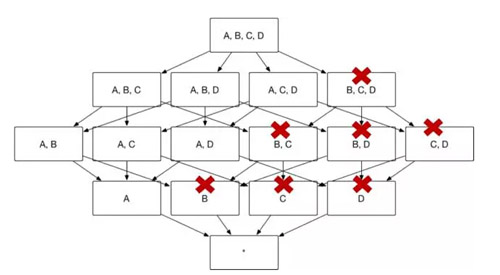
(圖10)
以圖 1中的Cube為例,假設維度A是必要維度,那麼生成的Cube則如圖11所示,維度數目從16變為9。
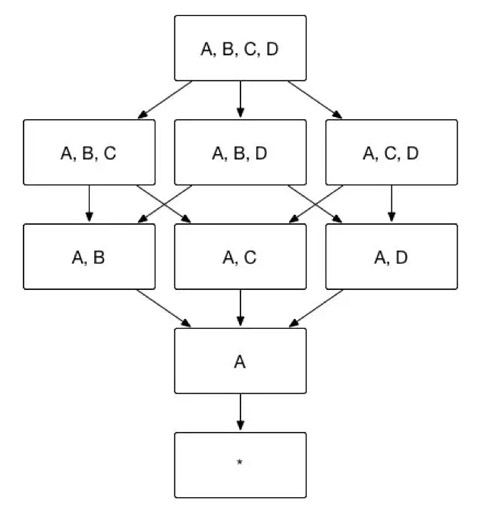
(圖11)
必要維度應用例項
假設一個交易資料的Cube,它具有很多普通的維度,像是交易時間order_dt,交易的地點location,交易的商品product和支付型別pay_type等。其中,交易時間就是一個被高頻作為分組條件(group by)的維度。 如果將交易時間order_dt設定為必要維度,包含的維度和組合方式如圖12:
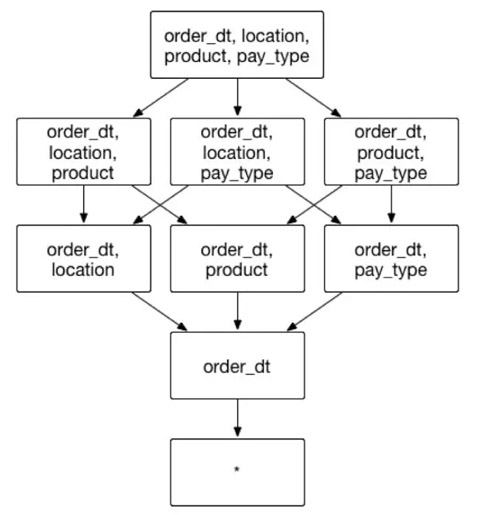
(圖12)
系列總結
根據本系列的原理介紹,在Kylin的高階設定中,使用者可以根據查詢需求對Cube構建預計算的結果進行優化(剪枝),從而減少佔用的儲存空間。 而優化得當的Cube可以在佔用儘量少的儲存空間的同時提供極強的查詢效能。
【編輯推薦】