
人工智慧測試方法--探索
阿新 • • 發佈:2019-02-04
什麼是人工智慧
再講如何測試人工智慧產品之前,我覺得我要先跟不熟悉人工智慧的同學們解釋一下什麼是人工智慧。畢竟想要測試一個東西,就要先了解它麼。用一句話來概括現階段的人工智慧就是:人工智慧=大資料+機器學習。
我理解的現階段的人工智慧是使用機器學習演算法在大量的歷史資料下進行訓練,從歷史資料中找到一定的規律並對未來做出的預測行為。這麼說有點拗口。我舉個例子,我們曾經給銀行做過反欺詐專案。 以前在銀行裡有一群專家,他們的工作就是根據經驗向系統中輸入一些規則。例如某一張卡在一個城市有了一筆交易,之後1小時內在另一個城市又有了一筆交易。這些專家根據以前的經驗判斷這種情況是有盜刷的風險的。他們在系統中輸入了幾千條這樣的規則,組成了一個專家系統。
這個專家系統是建立在人類對過往的資料所總結出的經驗下建立的。 後來我們引入了機器學習演算法,對過往所有的歷史資料進行訓練,最後在25億個特徵中抽取出8000萬條有效特徵。大家可以把這些特徵就暫且當成是專家系統中的規則。8000萬對不到1萬,效果是可以預想的。當時對第一版模型上線後的資料做統計,反欺詐效果提升了7倍, 這就是二分類演算法典型的業務場景。
為什麼叫機器學習呢,因為它給人一種感覺,機器能像人類一樣從過去的資料中學習到經驗,只不過機器的能力更強。 如果想再稍微深究一下機器學習訓練出來的模型到底是什麼,那大家可以暫且理解為一個二分類的模型主要是就是一個key,value的資料庫 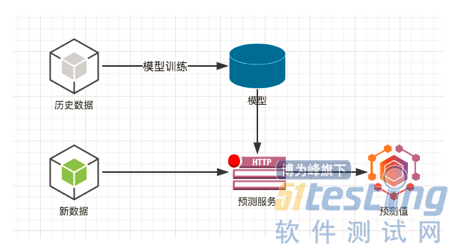 這個圖就是一個人工智慧服務的略縮圖。 在歷史資料上訓練出模型,併發佈一個預測服務,這個預測服務可能就是一個http的介面。 然後新的資料過來以後,根據模型算出一個預測值。經過剛才的說明,我們看到資料是人工智慧的根本。擁有的資料越多,越豐富,越真實,那麼訓練出的模型效果越好。
測試思路
●資料測試
●分層測試
●訓練集與測試集對比
資料測試
根據我們之前對人工智慧的定義,我們發現數據是人工智慧的根據。 保證資料的正確定是非常必要的。 而且幾乎所有的機器學習演算法對資料的容錯能力都很強,即便資料稍有偏差,它們也能通過一次一次的迭代和對比來減少誤差。 所以即便我們的資料有一點問題最後得出的模型效果可能還不差, 但是這個時候我們不能認為模型就沒問題了。 因為很可能在某些特定場景下就會出現雪崩效應。
再舉個例子。當初阿爾法狗與李世石一戰成名。如果說前三盤的結果令各路專家大跌眼鏡的話。那第四盤可能是讓所有人都大跌眼鏡了。阿爾法狗連出昏招,幾乎是將這一局拱手相讓。那阿爾法狗出bug了?DeepMind團隊說,這是一個系統問題。那我們來看看這個系統到底有什麼問題。根據當時公佈出來的資料我們發現阿爾法狗的養成方法是這樣的。
阿爾法狗如何養成
這個圖就是一個人工智慧服務的略縮圖。 在歷史資料上訓練出模型,併發佈一個預測服務,這個預測服務可能就是一個http的介面。 然後新的資料過來以後,根據模型算出一個預測值。經過剛才的說明,我們看到資料是人工智慧的根本。擁有的資料越多,越豐富,越真實,那麼訓練出的模型效果越好。
測試思路
●資料測試
●分層測試
●訓練集與測試集對比
資料測試
根據我們之前對人工智慧的定義,我們發現數據是人工智慧的根據。 保證資料的正確定是非常必要的。 而且幾乎所有的機器學習演算法對資料的容錯能力都很強,即便資料稍有偏差,它們也能通過一次一次的迭代和對比來減少誤差。 所以即便我們的資料有一點問題最後得出的模型效果可能還不差, 但是這個時候我們不能認為模型就沒問題了。 因為很可能在某些特定場景下就會出現雪崩效應。
再舉個例子。當初阿爾法狗與李世石一戰成名。如果說前三盤的結果令各路專家大跌眼鏡的話。那第四盤可能是讓所有人都大跌眼鏡了。阿爾法狗連出昏招,幾乎是將這一局拱手相讓。那阿爾法狗出bug了?DeepMind團隊說,這是一個系統問題。那我們來看看這個系統到底有什麼問題。根據當時公佈出來的資料我們發現阿爾法狗的養成方法是這樣的。
阿爾法狗如何養成 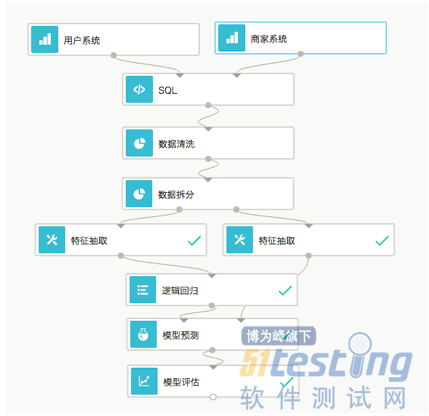 可以看到我們把資料引入到系統後,先是用SQL運算元對資料做了拼接,然後清洗一些無效資料。
再把資料拆分為訓練集和測試集。分別對兩個資料集做特徵抽取。之後訓練集傳遞給邏輯迴歸這個機器學習演算法進行訓練。訓練之後使用測試集來測試一下模型的效果。大家看到這個圖了,這是建立一個模型比較常見的流程。圖中的邏輯歸回就是一種機器學習演算法,也是一種最簡單的二分類演算法,其他的演算法諸如GBDT,SVM,DNN等演算法的模型都是這個流程。我們可以看到演算法上面的流程。全部與機器學習無關。他們都屬於大資料處理範疇。而且一個成型的系統在每一個模組都會提供一些固定的介面。
例如我們公司在特徵抽取演算法上就提供了近百個特徵抽取的介面,可以根據不同的情況使用不同的方式提取資料中的特徵。 資料拆分也有很多種不同的拆分方法,按隨機拆分,分層拆分,規則拆分。 每個子模組都會提供一些介面供上層呼叫。 所以既然提到介面層面的東西了,大家應該都知道怎麼測了吧。 只不過有些介面並不是http或者RPC協議的。 有時候需要我們在產品的repo裡寫測試用例。
訓練集與測試集對比
可以看到我們把資料引入到系統後,先是用SQL運算元對資料做了拼接,然後清洗一些無效資料。
再把資料拆分為訓練集和測試集。分別對兩個資料集做特徵抽取。之後訓練集傳遞給邏輯迴歸這個機器學習演算法進行訓練。訓練之後使用測試集來測試一下模型的效果。大家看到這個圖了,這是建立一個模型比較常見的流程。圖中的邏輯歸回就是一種機器學習演算法,也是一種最簡單的二分類演算法,其他的演算法諸如GBDT,SVM,DNN等演算法的模型都是這個流程。我們可以看到演算法上面的流程。全部與機器學習無關。他們都屬於大資料處理範疇。而且一個成型的系統在每一個模組都會提供一些固定的介面。
例如我們公司在特徵抽取演算法上就提供了近百個特徵抽取的介面,可以根據不同的情況使用不同的方式提取資料中的特徵。 資料拆分也有很多種不同的拆分方法,按隨機拆分,分層拆分,規則拆分。 每個子模組都會提供一些介面供上層呼叫。 所以既然提到介面層面的東西了,大家應該都知道怎麼測了吧。 只不過有些介面並不是http或者RPC協議的。 有時候需要我們在產品的repo裡寫測試用例。
訓練集與測試集對比
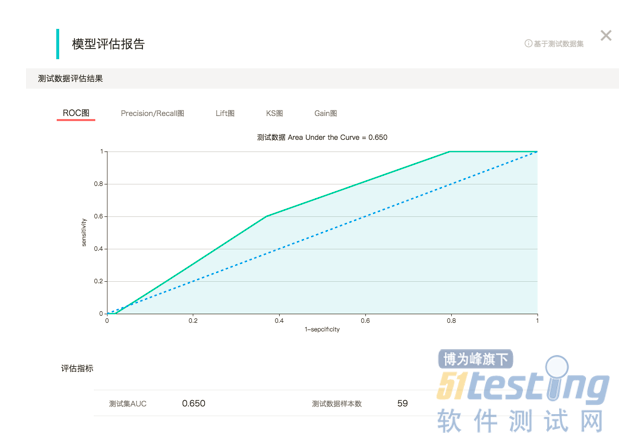 這是我們的第三種測試思路。 我們剛才一直用來舉例的分類演算法是一種監督學習。 什麼是監督學習呢,就是我們的歷史資料中是有答案的。還拿剛才的反欺詐的例子說,就是我們的資料中都有一個欄位標明瞭這條資料是否是欺詐場景。 所以我們完全可以把歷史資料拆分為訓練集和測試集。將測試集輸入到模型中以評價模型預測出的結果的正確率如何。所以每次版本迭代都使用同樣的資料,同樣的引數配置。 統計模型效果並進行對比。當然這種測試方式是一種模糊的方式。就如我再剛開始說的一樣,這種方式無法判斷問題出在哪裡。是bug,還是引數設定錯了?我們無法判斷。
常見的測試場景
自學習
這是我們的第三種測試思路。 我們剛才一直用來舉例的分類演算法是一種監督學習。 什麼是監督學習呢,就是我們的歷史資料中是有答案的。還拿剛才的反欺詐的例子說,就是我們的資料中都有一個欄位標明瞭這條資料是否是欺詐場景。 所以我們完全可以把歷史資料拆分為訓練集和測試集。將測試集輸入到模型中以評價模型預測出的結果的正確率如何。所以每次版本迭代都使用同樣的資料,同樣的引數配置。 統計模型效果並進行對比。當然這種測試方式是一種模糊的方式。就如我再剛開始說的一樣,這種方式無法判斷問題出在哪裡。是bug,還是引數設定錯了?我們無法判斷。
常見的測試場景
自學習
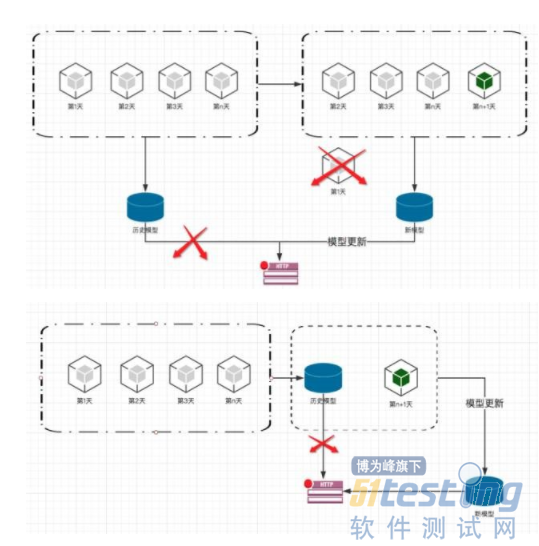 幾乎所有的人工智慧服務都必須要支援自學習場景。就像阿爾法狗一樣,它輸了一局,就會從輸的這一局中學習到經驗,以後他就不會那麼下了,這也是機器學習恐怖的地方,它會變的越來越無懈可擊,以前人類還能贏上一局,但是未來可能人類再也贏不了阿爾法狗了。 做法就是我們的資料每天都是在更新的,使用者行為也是一直在變化的。所以我們的模型要有從最新的資料中進行學習的能力。
幾乎所有的人工智慧服務都必須要支援自學習場景。就像阿爾法狗一樣,它輸了一局,就會從輸的這一局中學習到經驗,以後他就不會那麼下了,這也是機器學習恐怖的地方,它會變的越來越無懈可擊,以前人類還能贏上一局,但是未來可能人類再也贏不了阿爾法狗了。 做法就是我們的資料每天都是在更新的,使用者行為也是一直在變化的。所以我們的模型要有從最新的資料中進行學習的能力。
 上面的一個圖是一個比較流行的預測服務的架構。當然我做了相應的簡化,隱去了一些細節。所有的部署任務由master寫入ETCD。 所有agent以自注冊的方式將自己的資訊寫入ETCD以接受master的管理並執行部署任務。 而router也同樣讀取etcd獲取所有agent提供的預測服務的資訊並負責負載均衡。 有些公司為了做高可用和彈性伸縮甚至將agent納入了kubernetes的HPA中進行管理。由此我們需要測試這套機制能實現他該有的功能。例如:
router會按規則把壓力分發到各個agent上。
把某個agent的預測服務被kill掉後,router會自動切換。
預估服務掛掉,agent會自動感知並重新拉起服務。
agent被kill掉後,也會被自動拉起。
如果做了彈性伸縮,需要將預測服務壓到臨界點後觀察系統是否做了擴容等等。
效能測試
我們要接觸的效能測試跟網際網路的不太一樣。我們知道預測服務仍然還是訪問密集型業務。但是模型調研的過程是屬於計算密集型業務。我們要模擬的情況不再是高併發。而是不同的資料規模,資料分佈和資料型別。我們日常的效能測試都是需要在各種不同的資料下跑各種不同的運算元和引數。所以我們首先需要一種造數機制,能幫助我們按需求生成大規模的資料。我們選擇的是spark,利用分散式計算在hadoop叢集上生成大量的資料。
原理也很簡單,接觸過spark的同學肯定都知道在spark中生成一個RDD有兩種方式, 一種是從檔案中讀取,另一種是從記憶體中的一個list種解析。第一種方式肯定不是我們想要的, 所以從記憶體中的list解析就是我們選擇的方式。假如我們想生成一個10億行的資料。就可以先使用python 的xrange造一個生成器以防止記憶體被撐爆。然後用這個生成器初始化一個有著10億行的空的RDD,定義並操作RDD的每一行去生成我們想要的資料,然後設定RDD的分片以及消耗的container,記憶體,cpu等引數。提交到叢集上利用叢集龐大的計算資源幫助我們在段時間內生成我們需要的資料。
前兩天我再一個3個節點的叢集上造過一個1.5T的資料,大概用了5個小時。這樣一開始的時候我們是寫spark指令碼來完成這些事。後來需求越來越多,我們發現可以造數做成一個工具。把表和欄位都提取到配置檔案中進行定義。就這樣我們成立了shannon這個專案。慢慢的從造數指令碼到造數工具再到造數平臺。
它的架構特別簡單,就是對原生spark的應用,這裡我就不展示spark的架構是什麼樣了。就貼一下造數工具的設計圖吧。
上面的一個圖是一個比較流行的預測服務的架構。當然我做了相應的簡化,隱去了一些細節。所有的部署任務由master寫入ETCD。 所有agent以自注冊的方式將自己的資訊寫入ETCD以接受master的管理並執行部署任務。 而router也同樣讀取etcd獲取所有agent提供的預測服務的資訊並負責負載均衡。 有些公司為了做高可用和彈性伸縮甚至將agent納入了kubernetes的HPA中進行管理。由此我們需要測試這套機制能實現他該有的功能。例如:
router會按規則把壓力分發到各個agent上。
把某個agent的預測服務被kill掉後,router會自動切換。
預估服務掛掉,agent會自動感知並重新拉起服務。
agent被kill掉後,也會被自動拉起。
如果做了彈性伸縮,需要將預測服務壓到臨界點後觀察系統是否做了擴容等等。
效能測試
我們要接觸的效能測試跟網際網路的不太一樣。我們知道預測服務仍然還是訪問密集型業務。但是模型調研的過程是屬於計算密集型業務。我們要模擬的情況不再是高併發。而是不同的資料規模,資料分佈和資料型別。我們日常的效能測試都是需要在各種不同的資料下跑各種不同的運算元和引數。所以我們首先需要一種造數機制,能幫助我們按需求生成大規模的資料。我們選擇的是spark,利用分散式計算在hadoop叢集上生成大量的資料。
原理也很簡單,接觸過spark的同學肯定都知道在spark中生成一個RDD有兩種方式, 一種是從檔案中讀取,另一種是從記憶體中的一個list種解析。第一種方式肯定不是我們想要的, 所以從記憶體中的list解析就是我們選擇的方式。假如我們想生成一個10億行的資料。就可以先使用python 的xrange造一個生成器以防止記憶體被撐爆。然後用這個生成器初始化一個有著10億行的空的RDD,定義並操作RDD的每一行去生成我們想要的資料,然後設定RDD的分片以及消耗的container,記憶體,cpu等引數。提交到叢集上利用叢集龐大的計算資源幫助我們在段時間內生成我們需要的資料。
前兩天我再一個3個節點的叢集上造過一個1.5T的資料,大概用了5個小時。這樣一開始的時候我們是寫spark指令碼來完成這些事。後來需求越來越多,我們發現可以造數做成一個工具。把表和欄位都提取到配置檔案中進行定義。就這樣我們成立了shannon這個專案。慢慢的從造數指令碼到造數工具再到造數平臺。
它的架構特別簡單,就是對原生spark的應用,這裡我就不展示spark的架構是什麼樣了。就貼一下造數工具的設計圖吧。
 簡單來說shannon分了3層。最底層是基本資料型別層。負責欄位例項化,定義並實現了shannon支援的所有資料型別。例如,隨機,列舉,主鍵,unique key,控制分佈,大小,範圍等等。
測試環境管理
常見的測試場景我們基本上都說完了。 我們再說一說測試環境管理的問題。 為了能夠保證研發和測試效率,一個能夠支撐大規模測試環境的基礎設施是十分必要的。為什麼這麼說呢?
●首先但凡是涉及到機器學習的業務,執行時間都非常慢。 有時候做測試的時候跑一個模型要幾個小時甚至一天都是有的。也就是說,我們執行測試的成本比較高。如果在執行測試的途中環境出了什麼問題那麼損失還是很大的。多人共用一套環境難免會有互相踩踏的情況,例如一個RD在測試自己的模組,另一個人上來把服務重啟了。這時候我們心裡一般就是一萬頭某種動物飄過。所以我們一般希望每個人都能擁有一套獨立的環境甚至一個人多套環境。這就增加了測試環境的數量。尤其是團隊越來越大的時候,測試環境的數量已經到達了一個恐怖的量級。
●其次如果各位所在的公司也像我們一樣做TO B的業務,那麼我們的測試環境就需要多版本管理,要有能力隨時快速的搭建起特定版本的產品環境供開發,產品,測試,以及技術支援人員使用。所以這無疑又增加了環境管理設定的複雜度。
●再有就是隨著環境數量的擴張,我們的環境從單節點走向叢集,這時候我們對環境排程能力的要求會比較高,例如我們要對環境的資源進行計算和限制,保證最大化利用資源的同時不會撐爆系統。例如我們要保證系統有足夠的冗餘,在某些環境出現故障的時候能夠自動檢測出來並在冗餘節點進行恢復。例如我們需要能夠實現多租戶管理,執行資源管控,限制超售行為. 例如我們希望系統有一定能力的無人值守運維能力等等。
所以我們經過一段時間的討論和實驗,引入了k8s+docker來完成這個目標。docker的優勢大家應該都知道,快速,標準化,隔離性,可遷移性都不錯。 通過映象我們可以迅速的將測試環境的數量提升一個量級,映象的版本管理正適合TO B業務的多版本管理。 之所以選擇k8s,是因為k8s相較於swarm和mesos 都擁有著更強大的功能和更簡單的部署方式。剛才說的預測服務需要部署很多個agent,使用k8s的話只需要設定一下replica set的數量,k8s就會自動幫我們維護好這個數量的例項了,很方便 。k8s的排程機制能很輕鬆的滿足我們剛才說的對於災難恢復,冗餘,多租戶,高可用,負載均衡,資源管理等要求。所以我們當初懷揣著對google莫名的憧憬走上了k8s的踩坑之旅。
簡單來說shannon分了3層。最底層是基本資料型別層。負責欄位例項化,定義並實現了shannon支援的所有資料型別。例如,隨機,列舉,主鍵,unique key,控制分佈,大小,範圍等等。
測試環境管理
常見的測試場景我們基本上都說完了。 我們再說一說測試環境管理的問題。 為了能夠保證研發和測試效率,一個能夠支撐大規模測試環境的基礎設施是十分必要的。為什麼這麼說呢?
●首先但凡是涉及到機器學習的業務,執行時間都非常慢。 有時候做測試的時候跑一個模型要幾個小時甚至一天都是有的。也就是說,我們執行測試的成本比較高。如果在執行測試的途中環境出了什麼問題那麼損失還是很大的。多人共用一套環境難免會有互相踩踏的情況,例如一個RD在測試自己的模組,另一個人上來把服務重啟了。這時候我們心裡一般就是一萬頭某種動物飄過。所以我們一般希望每個人都能擁有一套獨立的環境甚至一個人多套環境。這就增加了測試環境的數量。尤其是團隊越來越大的時候,測試環境的數量已經到達了一個恐怖的量級。
●其次如果各位所在的公司也像我們一樣做TO B的業務,那麼我們的測試環境就需要多版本管理,要有能力隨時快速的搭建起特定版本的產品環境供開發,產品,測試,以及技術支援人員使用。所以這無疑又增加了環境管理設定的複雜度。
●再有就是隨著環境數量的擴張,我們的環境從單節點走向叢集,這時候我們對環境排程能力的要求會比較高,例如我們要對環境的資源進行計算和限制,保證最大化利用資源的同時不會撐爆系統。例如我們要保證系統有足夠的冗餘,在某些環境出現故障的時候能夠自動檢測出來並在冗餘節點進行恢復。例如我們需要能夠實現多租戶管理,執行資源管控,限制超售行為. 例如我們希望系統有一定能力的無人值守運維能力等等。
所以我們經過一段時間的討論和實驗,引入了k8s+docker來完成這個目標。docker的優勢大家應該都知道,快速,標準化,隔離性,可遷移性都不錯。 通過映象我們可以迅速的將測試環境的數量提升一個量級,映象的版本管理正適合TO B業務的多版本管理。 之所以選擇k8s,是因為k8s相較於swarm和mesos 都擁有著更強大的功能和更簡單的部署方式。剛才說的預測服務需要部署很多個agent,使用k8s的話只需要設定一下replica set的數量,k8s就會自動幫我們維護好這個數量的例項了,很方便 。k8s的排程機制能很輕鬆的滿足我們剛才說的對於災難恢復,冗餘,多租戶,高可用,負載均衡,資源管理等要求。所以我們當初懷揣著對google莫名的憧憬走上了k8s的踩坑之旅。
 首先說一下我們都用容器做什麼。主要三大類,第一種是諸如testlink,jenkins這種基礎服務。第二種是產品的測試環境,這是佔比最多的。然後就是我們的測試執行機器了。例如UI自動化,我們採取的是分別將selenium hub和node docker化的做法。如下圖:
首先說一下我們都用容器做什麼。主要三大類,第一種是諸如testlink,jenkins這種基礎服務。第二種是產品的測試環境,這是佔比最多的。然後就是我們的測試執行機器了。例如UI自動化,我們採取的是分別將selenium hub和node docker化的做法。如下圖:
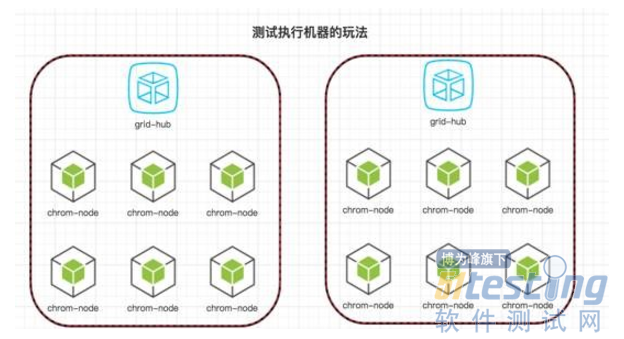 當UI自動化的case增多的時候,分散式執行往往是最好的解決方案。 目前我們通過這種方式容器化了20個瀏覽器進行併發測試。這些映象都有官方的版本,使用起來還是蠻方面的。
然後說一下比較關鍵的網路解決方案,我們從單機到叢集,中途歷經了集中網路模型的變化。從一開始的埠對映,到利用路由規則給容器分配真實的ip,再到給每個容器在DHCP和DNS伺服器上註冊和續租。到最後我們演進出了下面這個k8s的網路模型。
當UI自動化的case增多的時候,分散式執行往往是最好的解決方案。 目前我們通過這種方式容器化了20個瀏覽器進行併發測試。這些映象都有官方的版本,使用起來還是蠻方面的。
然後說一下比較關鍵的網路解決方案,我們從單機到叢集,中途歷經了集中網路模型的變化。從一開始的埠對映,到利用路由規則給容器分配真實的ip,再到給每個容器在DHCP和DNS伺服器上註冊和續租。到最後我們演進出了下面這個k8s的網路模型。
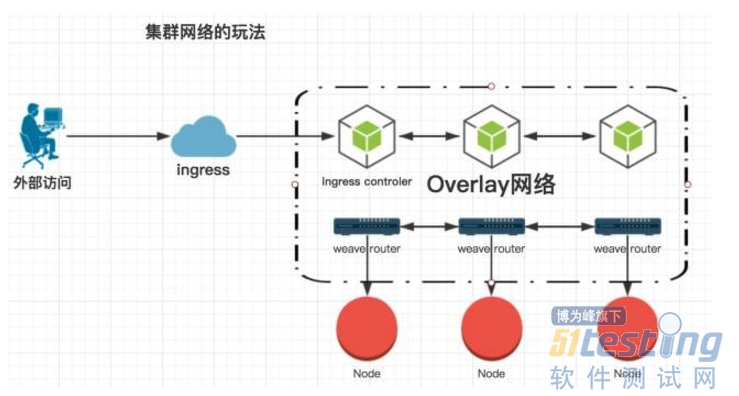 我們知道每個docker宿主機都會自己維護一個私有網路。如果想讓容器跨主機通訊或者外部訪問容器。一般就是通過三種方式: 埠對映,路由規則以及overlay網路。我們選擇在k8s中引入的overlay網路是weave,以解決誇主機通訊問題。安裝kube-dns實現服務發現。之後為了能讓外部訪問容器服務, 使用了k8s提供的ingress機制來實現。這個ingress網路其實就是在叢集中啟動一個容器,這個容器既能訪問容器網路的同是還監聽了宿主機的80埠。容器裡是一個nginx,它會負責幫忙轉發請求。nginx負責轉發的有servicename和path,這裡我們是無法使用路徑進行轉發的。所以我們在公司內部的DNS上做了泛域名解析。所有testenv為字尾的域名都會解析成叢集的master節點的ip。這樣我們的請求就能命中nginx中固定的servicename並做轉發了。通過這種機制我們就可以很方面的訪問容器提供的服務。當然ingress的缺點是暫時還無法做4層轉發。如果要訪問4層協議的服務暫時還是隻能暴露node
port。
我們這個測試環境的管理平臺主要的架構是這樣的:
我們知道每個docker宿主機都會自己維護一個私有網路。如果想讓容器跨主機通訊或者外部訪問容器。一般就是通過三種方式: 埠對映,路由規則以及overlay網路。我們選擇在k8s中引入的overlay網路是weave,以解決誇主機通訊問題。安裝kube-dns實現服務發現。之後為了能讓外部訪問容器服務, 使用了k8s提供的ingress機制來實現。這個ingress網路其實就是在叢集中啟動一個容器,這個容器既能訪問容器網路的同是還監聽了宿主機的80埠。容器裡是一個nginx,它會負責幫忙轉發請求。nginx負責轉發的有servicename和path,這裡我們是無法使用路徑進行轉發的。所以我們在公司內部的DNS上做了泛域名解析。所有testenv為字尾的域名都會解析成叢集的master節點的ip。這樣我們的請求就能命中nginx中固定的servicename並做轉發了。通過這種機制我們就可以很方面的訪問容器提供的服務。當然ingress的缺點是暫時還無法做4層轉發。如果要訪問4層協議的服務暫時還是隻能暴露node
port。
我們這個測試環境的管理平臺主要的架構是這樣的:
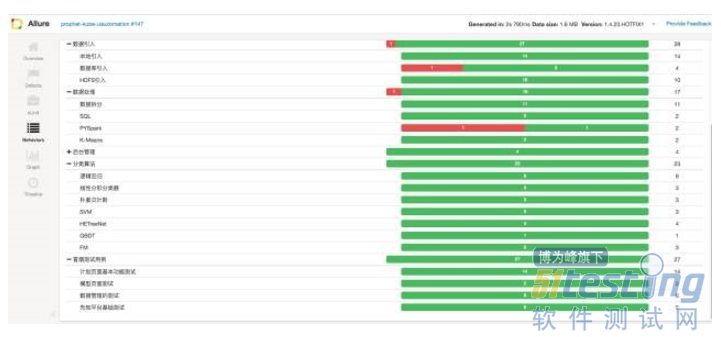
 叢集中所有的映象都過公司內部搭建的映象倉庫進行共享,我們在叢集之上安裝了各種服務來滿足測試環境的需要。例如使用NFS做資料持久化,Heapster+Grafana+InfluxDB做效能監控,kube-DNS做服務發現,dashboard提供web管理介面,weave做叢集網路,ingress做服務的轉發。並且我們在這個整體上針對k8s的APIserver做了一層cli的封裝。我們嘗試過指令碼管理,web服務管理,但是發現大家對這些方式的接受度都不高。我們面對的大多數都是一幫做夢都在寫程式碼的人,所以我們換做提供一個cli的方式可以讓使用者更靈活來定製自己需要的服務。通過這種形式,我們在公司內部搭建了一個可以提供測試資源的私有云,配合jenkins我們可以很方便的一鍵部署我們需要的環境並執行UT,介面,UI自動化測試等等,並提供一個詳細的測試報告。下面是我們的部署一個環境後所提供的測試報告。
叢集中所有的映象都過公司內部搭建的映象倉庫進行共享,我們在叢集之上安裝了各種服務來滿足測試環境的需要。例如使用NFS做資料持久化,Heapster+Grafana+InfluxDB做效能監控,kube-DNS做服務發現,dashboard提供web管理介面,weave做叢集網路,ingress做服務的轉發。並且我們在這個整體上針對k8s的APIserver做了一層cli的封裝。我們嘗試過指令碼管理,web服務管理,但是發現大家對這些方式的接受度都不高。我們面對的大多數都是一幫做夢都在寫程式碼的人,所以我們換做提供一個cli的方式可以讓使用者更靈活來定製自己需要的服務。通過這種形式,我們在公司內部搭建了一個可以提供測試資源的私有云,配合jenkins我們可以很方便的一鍵部署我們需要的環境並執行UT,介面,UI自動化測試等等,並提供一個詳細的測試報告。下面是我們的部署一個環境後所提供的測試報告。
 好了,關於k8s+docker的內容我暫時就講到這,其實這塊內容比較多,完全可以單獨拉出來當做一個topic來講了。但是今天由於時間限制我們先講這麼多吧。我今天的分享也就到此結束了。關於人工智慧類產品的測試我們也屬於摸著石頭過河,還有很多不足的地方。
好了,關於k8s+docker的內容我暫時就講到這,其實這塊內容比較多,完全可以單獨拉出來當做一個topic來講了。但是今天由於時間限制我們先講這麼多吧。我今天的分享也就到此結束了。關於人工智慧類產品的測試我們也屬於摸著石頭過河,還有很多不足的地方。
這個圖就是一個人工智慧服務的略縮圖。 在歷史資料上訓練出模型,併發佈一個預測服務,這個預測服務可能就是一個http的介面。 然後新的資料過來以後,根據模型算出一個預測值。經過剛才的說明,我們看到資料是人工智慧的根本。擁有的資料越多,越豐富,越真實,那麼訓練出的模型效果越好。
測試思路
●資料測試
●分層測試
●訓練集與測試集對比
資料測試
根據我們之前對人工智慧的定義,我們發現數據是人工智慧的根據。 保證資料的正確定是非常必要的。 而且幾乎所有的機器學習演算法對資料的容錯能力都很強,即便資料稍有偏差,它們也能通過一次一次的迭代和對比來減少誤差。 所以即便我們的資料有一點問題最後得出的模型效果可能還不差, 但是這個時候我們不能認為模型就沒問題了。 因為很可能在某些特定場景下就會出現雪崩效應。
再舉個例子。當初阿爾法狗與李世石一戰成名。如果說前三盤的結果令各路專家大跌眼鏡的話。那第四盤可能是讓所有人都大跌眼鏡了。阿爾法狗連出昏招,幾乎是將這一局拱手相讓。那阿爾法狗出bug了?DeepMind團隊說,這是一個系統問題。那我們來看看這個系統到底有什麼問題。根據當時公佈出來的資料我們發現阿爾法狗的養成方法是這樣的。
阿爾法狗如何養成
可以看到我們把資料引入到系統後,先是用SQL運算元對資料做了拼接,然後清洗一些無效資料。
再把資料拆分為訓練集和測試集。分別對兩個資料集做特徵抽取。之後訓練集傳遞給邏輯迴歸這個機器學習演算法進行訓練。訓練之後使用測試集來測試一下模型的效果。大家看到這個圖了,這是建立一個模型比較常見的流程。圖中的邏輯歸回就是一種機器學習演算法,也是一種最簡單的二分類演算法,其他的演算法諸如GBDT,SVM,DNN等演算法的模型都是這個流程。我們可以看到演算法上面的流程。全部與機器學習無關。他們都屬於大資料處理範疇。而且一個成型的系統在每一個模組都會提供一些固定的介面。
例如我們公司在特徵抽取演算法上就提供了近百個特徵抽取的介面,可以根據不同的情況使用不同的方式提取資料中的特徵。 資料拆分也有很多種不同的拆分方法,按隨機拆分,分層拆分,規則拆分。 每個子模組都會提供一些介面供上層呼叫。 所以既然提到介面層面的東西了,大家應該都知道怎麼測了吧。 只不過有些介面並不是http或者RPC協議的。 有時候需要我們在產品的repo裡寫測試用例。
訓練集與測試集對比
這是我們的第三種測試思路。 我們剛才一直用來舉例的分類演算法是一種監督學習。 什麼是監督學習呢,就是我們的歷史資料中是有答案的。還拿剛才的反欺詐的例子說,就是我們的資料中都有一個欄位標明瞭這條資料是否是欺詐場景。 所以我們完全可以把歷史資料拆分為訓練集和測試集。將測試集輸入到模型中以評價模型預測出的結果的正確率如何。所以每次版本迭代都使用同樣的資料,同樣的引數配置。 統計模型效果並進行對比。當然這種測試方式是一種模糊的方式。就如我再剛開始說的一樣,這種方式無法判斷問題出在哪裡。是bug,還是引數設定錯了?我們無法判斷。
常見的測試場景
自學習
幾乎所有的人工智慧服務都必須要支援自學習場景。就像阿爾法狗一樣,它輸了一局,就會從輸的這一局中學習到經驗,以後他就不會那麼下了,這也是機器學習恐怖的地方,它會變的越來越無懈可擊,以前人類還能贏上一局,但是未來可能人類再也贏不了阿爾法狗了。 做法就是我們的資料每天都是在更新的,使用者行為也是一直在變化的。所以我們的模型要有從最新的資料中進行學習的能力。
上面是常見的自學習場景流程圖。假如我們用歷史上n天的資料訓練出一個模型併發布成了一個預測的服務。 那麼到了隔天的時候。我們拋棄之前第一天的資料,使用第二天到第n+1天的資料重新訓練一個模型並代替之前的模型釋出一個預測服務。這樣不停的迴圈,每一天都收集到最新的資料參與模型訓練。 這時候大家應該明白該測試什麼了。每天收集到的新資料,就是測試重點。就是我們剛才說的第一種測試思路,使用spark,Hbase這些技術,根據業務指定規則,掃描這些資料。一旦有異常就要報警。
預測服務 下面一個場景是預測服務的。預測服務的架構一般都滿複雜的,為了實現高可用,負載均衡等目的,所以一般都是標準的服務發現架構。以etcd這種分散式儲存機制為載體。 所有的預測服務分別以自注冊的方式來提供服務。
上面的一個圖是一個比較流行的預測服務的架構。當然我做了相應的簡化,隱去了一些細節。所有的部署任務由master寫入ETCD。 所有agent以自注冊的方式將自己的資訊寫入ETCD以接受master的管理並執行部署任務。 而router也同樣讀取etcd獲取所有agent提供的預測服務的資訊並負責負載均衡。 有些公司為了做高可用和彈性伸縮甚至將agent納入了kubernetes的HPA中進行管理。由此我們需要測試這套機制能實現他該有的功能。例如:
router會按規則把壓力分發到各個agent上。
把某個agent的預測服務被kill掉後,router會自動切換。
預估服務掛掉,agent會自動感知並重新拉起服務。
agent被kill掉後,也會被自動拉起。
如果做了彈性伸縮,需要將預測服務壓到臨界點後觀察系統是否做了擴容等等。
效能測試
我們要接觸的效能測試跟網際網路的不太一樣。我們知道預測服務仍然還是訪問密集型業務。但是模型調研的過程是屬於計算密集型業務。我們要模擬的情況不再是高併發。而是不同的資料規模,資料分佈和資料型別。我們日常的效能測試都是需要在各種不同的資料下跑各種不同的運算元和引數。所以我們首先需要一種造數機制,能幫助我們按需求生成大規模的資料。我們選擇的是spark,利用分散式計算在hadoop叢集上生成大量的資料。
原理也很簡單,接觸過spark的同學肯定都知道在spark中生成一個RDD有兩種方式, 一種是從檔案中讀取,另一種是從記憶體中的一個list種解析。第一種方式肯定不是我們想要的, 所以從記憶體中的list解析就是我們選擇的方式。假如我們想生成一個10億行的資料。就可以先使用python 的xrange造一個生成器以防止記憶體被撐爆。然後用這個生成器初始化一個有著10億行的空的RDD,定義並操作RDD的每一行去生成我們想要的資料,然後設定RDD的分片以及消耗的container,記憶體,cpu等引數。提交到叢集上利用叢集龐大的計算資源幫助我們在段時間內生成我們需要的資料。
前兩天我再一個3個節點的叢集上造過一個1.5T的資料,大概用了5個小時。這樣一開始的時候我們是寫spark指令碼來完成這些事。後來需求越來越多,我們發現可以造數做成一個工具。把表和欄位都提取到配置檔案中進行定義。就這樣我們成立了shannon這個專案。慢慢的從造數指令碼到造數工具再到造數平臺。
它的架構特別簡單,就是對原生spark的應用,這裡我就不展示spark的架構是什麼樣了。就貼一下造數工具的設計圖吧。
簡單來說shannon分了3層。最底層是基本資料型別層。負責欄位例項化,定義並實現了shannon支援的所有資料型別。例如,隨機,列舉,主鍵,unique key,控制分佈,大小,範圍等等。
測試環境管理
常見的測試場景我們基本上都說完了。 我們再說一說測試環境管理的問題。 為了能夠保證研發和測試效率,一個能夠支撐大規模測試環境的基礎設施是十分必要的。為什麼這麼說呢?
●首先但凡是涉及到機器學習的業務,執行時間都非常慢。 有時候做測試的時候跑一個模型要幾個小時甚至一天都是有的。也就是說,我們執行測試的成本比較高。如果在執行測試的途中環境出了什麼問題那麼損失還是很大的。多人共用一套環境難免會有互相踩踏的情況,例如一個RD在測試自己的模組,另一個人上來把服務重啟了。這時候我們心裡一般就是一萬頭某種動物飄過。所以我們一般希望每個人都能擁有一套獨立的環境甚至一個人多套環境。這就增加了測試環境的數量。尤其是團隊越來越大的時候,測試環境的數量已經到達了一個恐怖的量級。
●其次如果各位所在的公司也像我們一樣做TO B的業務,那麼我們的測試環境就需要多版本管理,要有能力隨時快速的搭建起特定版本的產品環境供開發,產品,測試,以及技術支援人員使用。所以這無疑又增加了環境管理設定的複雜度。
●再有就是隨著環境數量的擴張,我們的環境從單節點走向叢集,這時候我們對環境排程能力的要求會比較高,例如我們要對環境的資源進行計算和限制,保證最大化利用資源的同時不會撐爆系統。例如我們要保證系統有足夠的冗餘,在某些環境出現故障的時候能夠自動檢測出來並在冗餘節點進行恢復。例如我們需要能夠實現多租戶管理,執行資源管控,限制超售行為. 例如我們希望系統有一定能力的無人值守運維能力等等。
所以我們經過一段時間的討論和實驗,引入了k8s+docker來完成這個目標。docker的優勢大家應該都知道,快速,標準化,隔離性,可遷移性都不錯。 通過映象我們可以迅速的將測試環境的數量提升一個量級,映象的版本管理正適合TO B業務的多版本管理。 之所以選擇k8s,是因為k8s相較於swarm和mesos 都擁有著更強大的功能和更簡單的部署方式。剛才說的預測服務需要部署很多個agent,使用k8s的話只需要設定一下replica set的數量,k8s就會自動幫我們維護好這個數量的例項了,很方便 。k8s的排程機制能很輕鬆的滿足我們剛才說的對於災難恢復,冗餘,多租戶,高可用,負載均衡,資源管理等要求。所以我們當初懷揣著對google莫名的憧憬走上了k8s的踩坑之旅。
首先說一下我們都用容器做什麼。主要三大類,第一種是諸如testlink,jenkins這種基礎服務。第二種是產品的測試環境,這是佔比最多的。然後就是我們的測試執行機器了。例如UI自動化,我們採取的是分別將selenium hub和node docker化的做法。如下圖:
當UI自動化的case增多的時候,分散式執行往往是最好的解決方案。 目前我們通過這種方式容器化了20個瀏覽器進行併發測試。這些映象都有官方的版本,使用起來還是蠻方面的。
然後說一下比較關鍵的網路解決方案,我們從單機到叢集,中途歷經了集中網路模型的變化。從一開始的埠對映,到利用路由規則給容器分配真實的ip,再到給每個容器在DHCP和DNS伺服器上註冊和續租。到最後我們演進出了下面這個k8s的網路模型。
我們知道每個docker宿主機都會自己維護一個私有網路。如果想讓容器跨主機通訊或者外部訪問容器。一般就是通過三種方式: 埠對映,路由規則以及overlay網路。我們選擇在k8s中引入的overlay網路是weave,以解決誇主機通訊問題。安裝kube-dns實現服務發現。之後為了能讓外部訪問容器服務, 使用了k8s提供的ingress機制來實現。這個ingress網路其實就是在叢集中啟動一個容器,這個容器既能訪問容器網路的同是還監聽了宿主機的80埠。容器裡是一個nginx,它會負責幫忙轉發請求。nginx負責轉發的有servicename和path,這裡我們是無法使用路徑進行轉發的。所以我們在公司內部的DNS上做了泛域名解析。所有testenv為字尾的域名都會解析成叢集的master節點的ip。這樣我們的請求就能命中nginx中固定的servicename並做轉發了。通過這種機制我們就可以很方面的訪問容器提供的服務。當然ingress的缺點是暫時還無法做4層轉發。如果要訪問4層協議的服務暫時還是隻能暴露node
port。
我們這個測試環境的管理平臺主要的架構是這樣的:
叢集中所有的映象都過公司內部搭建的映象倉庫進行共享,我們在叢集之上安裝了各種服務來滿足測試環境的需要。例如使用NFS做資料持久化,Heapster+Grafana+InfluxDB做效能監控,kube-DNS做服務發現,dashboard提供web管理介面,weave做叢集網路,ingress做服務的轉發。並且我們在這個整體上針對k8s的APIserver做了一層cli的封裝。我們嘗試過指令碼管理,web服務管理,但是發現大家對這些方式的接受度都不高。我們面對的大多數都是一幫做夢都在寫程式碼的人,所以我們換做提供一個cli的方式可以讓使用者更靈活來定製自己需要的服務。通過這種形式,我們在公司內部搭建了一個可以提供測試資源的私有云,配合jenkins我們可以很方便的一鍵部署我們需要的環境並執行UT,介面,UI自動化測試等等,並提供一個詳細的測試報告。下面是我們的部署一個環境後所提供的測試報告。
好了,關於k8s+docker的內容我暫時就講到這,其實這塊內容比較多,完全可以單獨拉出來當做一個topic來講了。但是今天由於時間限制我們先講這麼多吧。我今天的分享也就到此結束了。關於人工智慧類產品的測試我們也屬於摸著石頭過河,還有很多不足的地方。