
怎樣刪除C/C++程式碼中的所有註釋?淺談狀態機的程式設計思想
K&R習題1-23中,要求“編寫一個程式,刪除C語言程式中所有的註釋語句。要正確處理帶引號的字串與字元常量。在C語言中,註釋不允許巢狀”。
如果不考慮字元常量和字串常量,問題確實很簡單。只需要去掉//和/* */的註釋。
考慮到字元常量'\''和字串常量"he\"/*hehe*/",還有類似<secure/_stdio.h>的標頭檔案路徑符號以及表示式5/3中的除號/,以及情況就比較複雜了。
另外,還有單行註釋//中用\進行折行註釋的蛋疼情況(這個情況連很多編輯器高亮都沒考慮到)。
我想,這種問題最適合用正則表示式來解析,perl之類的語言應當很好處理,問題是這裡讓你用C語言實現,但是C語言對正則表示式並沒有顯式的支援。
學過編譯原理的應該知道,正則表示式對應三型文法,也就對應著一個有限狀態自動機(可以用switch偏重演算法來實現,或者用狀態轉換矩陣/表偏重資料結構來實現),
所以這裡的問題其實是設計一個狀態機,把輸入的字元流扔進去跑就可以了。
那什麼是狀態機呢?K&R第一章怎麼沒有介紹呢?
【一個簡單的狀態機】
先看《K&R》第一章的一個簡單習題1-12:"編寫一個程式,以每行一個單詞的形式列印其輸入"
在這個題目之前,1.5.4節的單詞計數示例中,其實K&R已經展示了一個非常簡單的狀態機。但沒有提到這種程式設計思想。
當然這個題目也可以狀態機的思想來程式設計。
回到題目,我們設初始的狀態state為OUT,表示當前字元不在單詞中(不是單詞的組成字元),如果當前字元在單詞中(屬於單詞的一部分),則state設為IN。
顯然字元只能處於上述兩種狀態之一,有了這2個狀態,我們就可以藉助狀態來思考問題 ——
(1)當前狀態為OUT:若當前字元是空白字元(空格、製表符、換行符),則維護當前狀態仍為OUT;否則改變狀態為IN。
(2)當前狀態為IN:若遇到的當前字元是非空白字元,則維護當前狀態為IN;否則改變狀態為OUT。
處於不同的狀態,根據題意可以給予相對應的動作——
每當狀態為IN的時候,意味字元屬於單詞的一部分,輸出當前字元;
而當狀態從IN切換為OUT的時候,說明一個單詞結束了,此時我們輸出一個回車符;
狀態為OUT則什麼也不輸出;
可以看出,藉助自定義的狀態,可以使程式設計思路更加清晰。
在遍歷輸入字元流的時候,程式(機器)就只能處於兩種狀態,對應不同狀態或狀態切換可以有相應的處理動作。
這樣的程式不妨稱為“狀態機”。
按照上面的思路,程式碼實現就非常簡單了——
#include <stdio.h>
#define OUT 0 /* outside a word */
#define IN 1 /* inside a word */
int main(void)
{
int c, state;
state = OUT;
while ( ( c = getchar() ) != EOF ) {
if (state == OUT) {
if (c == ' ' || c == '\t' || c == '\n')
state = OUT;
else {
state = IN;
putchar(c); //action
}
} else {
if (c != ' ' && c != '\t' && c != '\n') {
state = IN;
putchar(c); //action
} else {
putchar('\n');//action
state = OUT;
}
}
}
return 0;
}讓我們回到主題吧——
【“編寫一個程式,刪除C語言程式中所有的註釋語句。要正確處理帶引號的字串與字元常量。在C語言中,註釋不允許巢狀”】
按照註釋的各方面規則,我們來設計一個狀態機——
00)設正常狀態為0,並初始為正常狀態
每遍歷一個字元,就依次檢查下列條件,若成立或全部檢查完畢,則回到這裡檢查下一個字元
01)狀態0中遇到/,說明可能會遇到註釋,則進入狀態1 ex. int a = b; /
02)狀態1中遇到*,說明進入多行註釋部分,則進入狀態2 ex. int a= b; /*
03)狀態1中遇到/,說明進入單行註釋部分,則進入狀態4 ex. int a = b; //
04)狀態1中沒有遇到*或/,說明/是路徑符號或除號,則恢復狀態0 ex. <secure/_stdio.h> or 5/3
05)狀態2中遇到*,說明多行註釋可能要結束,則進入狀態3 ex. int a = b; /*heh*
06)狀態2中不是遇到*,說明多行註釋還在繼續,則維持狀態2 ex. int a = b; /*hehe
07)狀態3中遇到/,說明多行註釋要結束,則恢復狀態0 ex. int a = b; /*hehe*/
08)狀態3中遇到*,則恢復狀態3 ex. int a = b; /***
09)狀態3中不是遇到/或*,說明多行註釋只是遇到*,恢復狀態2 ex. int a = b; /*hehe*h
10)狀態4中遇到\,說明可能進入折行註釋部分,則進入狀態5 ex. int a = b; //hehe\
11)狀態5中遇到\,說明可能進入折行註釋部分,則維護狀態5 ex. int a = b; //hehe\\\
12)狀態5中遇到其它字元,則說明進入了折行註釋部分,則恢復狀態4 ex. int a = b; // hehe\a or hehe\<enter>
13)狀態4中遇到回車符\n,說明單行註釋結束,則恢復狀態0 ex. int a = b; //hehe<enter>
14)狀態0中遇到',說明進入字元常量中,則進入狀態6 ex. char a = '
15)狀態6中遇到\,說明遇到轉義字元,則進入狀態7 ex. char a = '\
16)狀態7中遇到任何字元,都恢復狀態6 ex. char a = '\n 還有如'\t', '\'', '\\' 等 主要是防止'\'',誤以為結束
17)狀態6中遇到',說明字元常量結束,則進入狀態0 ex. char a = '\n'
18)狀態0中遇到",說明進入字串常量中,則進入狀態8 ex. char s[] = "
19)狀態8中遇到\,說明遇到轉義字元,則進入狀態9 ex. char s[] = "\
20)狀態9中遇到任何字元,都恢復狀態8 ex. char s[] = "\n 主要是防止"\",誤以為結束
21)狀態8中遇到"字元,說明字串常量結束,則恢復狀態0 ex. char s[] = "\"hehe"
前面說過,不同狀態可以有相應的動作。比如狀態0、6、7、8、9都需要輸出當前字元,再考慮一些特殊情況就可以了。
讀者實現時可以藉助debug巨集定義,將測試語句輸出到標準錯誤輸出,需要時可以重定位到標準輸出,即2>&1,然後通過重定向|到more進行檢視。
上面的狀態機涉及到了[0, 9]一共10種狀態,對應的狀態轉換圖(或者說狀態機/自動機)如下:
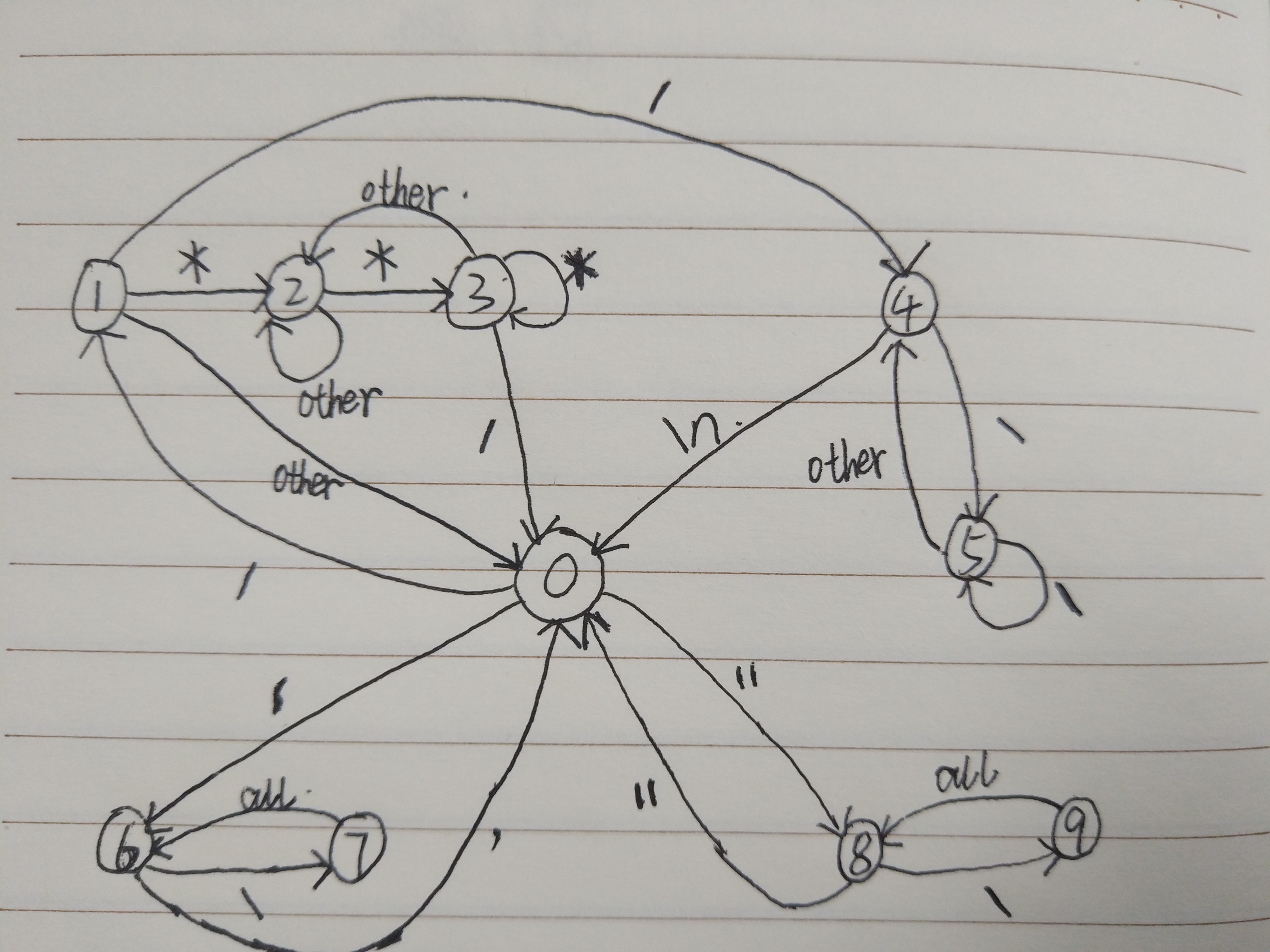
有了這些狀態表示,編寫程式碼就很容易了——
#include<stdio.h>
int main()
{
char c;
int state=0;
freopen("1.in","r",stdin);
freopen("1.out","w",stdout);
while((c=getchar())!=EOF)
{
switch(state)
{
case 0:
if(c=='/')// ex. [/]
state=1;
else if(c=='\'')// ex. [']
state=6;
else if(c=='\"')// ex. ["]
state=8;
else
putchar(c);
break;
case 1:
if(c=='*')// ex. [/*]
state=2;
else if(c=='/')// ex. [//]
state=4;
else
{ // ex. [<secure/_stdio.h> or 5/3]
putchar('/');
putchar(c);
state=0;
}
break;
case 2:
if(c=='*') // ex. [/*he*]
state=3;
else // ex. [/*heh]
state=2;
break;
case 3:
if(c=='/')// ex. [/*heh*/]
state=0;
else if(c=='*')
state=3;//ex. [/***]注意這裡,不加這個條件,*的個數是奇數的時候出錯
else// ex. [/*heh*e]
state=2;
break;
case 4:
if(c=='\\')// ex. [//hehe\]
state=5;
else if(c=='\n')// ex. [//hehe<enter>]
{
state=0;
putchar(c);
}
break;
case 5:
if(c=='\\')// ex. [//hehe\\\\\]
state=5;
else// ex. [//hehe\<enter> or //hehe\a]
state=4;
break;
case 6:
if(c=='\\')// ex. ['\]
state=7;
else if(c=='\'')// ex. ['\n' or '\'' or '\t' ect.]
{
state=0;
putchar(c);
}
break;
case 7:// ex. ['\n or '\' or '\t etc.]
state=6;
break;
case 8:
if(c=='\\')// ex. ["\]
state=9;
else if(c=='\"')// ex. ["\n" or "\"" or "\t" ect.]
{
state=0;
putchar(c);
}
break;
case 9:// ex. ["\n or "\" or "\t ect.]
state=8;
break;
}
if(state==6||state==7||state==8||state==9)
putchar(c);
}
return 0;
}
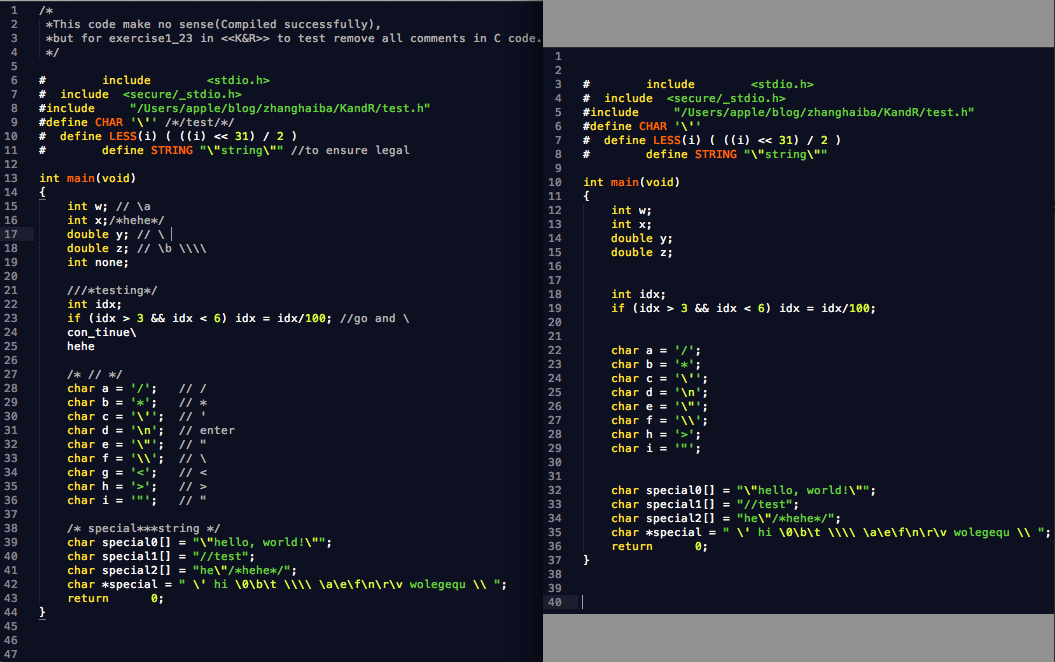
【測試用例(1)a.out < test.c > test2.c】
test.c如下:
/*
*This code make no sense(Compiled successfully),
*but for exercise1_23 in <<K&R>> to test remove all comments in C code.
*/
# include <stdio.h>
# include <secure/_stdio.h>
#include "/Users/apple/blog/zhanghaiba/KandR/test.h"
#define CHAR '\'' /*/test/*/
# define LESS(i) ( ((i) << 31) / 2 )
# define STRING "\"string\"" //to ensure legal
int main(void)
{
int w; // \a
int x;/*hehe*/
double y; // \
double z; // \b \\\\
int none;
///*testing*/
int idx;
if (idx > 3 && idx < 6) idx = idx/100; //go and \
con_tinue\
hehe
/* // */
char a = '/'; // /
char b = '*'; // *
char c = '\''; // '
char d = '\n'; // enter
char e = '\"'; // "
char f = '\\'; // \
char g = '<'; // <
char h = '>'; // >
char i = '"'; // "
/* special***string */
char special0[] = "\"hello, world!\"";
char special1[] = "//test";
char special2[] = "he\"/*hehe*/";
char *special = " \' hi \0\b\t \\\\ \a\e\f\n\r\v wolegequ \\ ";
return 0;
}測試截圖對比如下:
(說明:由於編輯器高亮的原因,注意//後面加字元\的折行註釋部分顏色其實不對的,另外17行\後面是有一個空格的)
【測試用例(2)./a.out < ~/open_src_code/glibc-2.17/malloc/malloc.c > test2.c】
glibc-2.17原始碼中的的malloc.c包括空行和註釋有5163行,經過上面去註釋後代碼變成3625行。
測試發現去註釋成功。這裡不可能貼對比程式碼了。
有興趣的讀者可自行測試。
歡迎提供測試不正確的用例程式碼。
轉自:http://www.cnblogs.com/zhanghaiba/p/3569928.html