
阿里雲大資料計算平臺的自動化、精細化運維之路
阿新 • • 發佈:2019-02-04
作者簡介:
 範倫挺
阿里巴巴 基礎架構事業群-技術專家
花名蕭一,2010年加入阿里巴巴,現任阿里巴巴集團大資料計算平臺運維負責人。團隊主要負責阿里巴巴各類離線上大資料計算平臺(如MaxCompute、AnalyticDB、StreamCompute等)的運維、架構優化及容量管理等
1、前言
本文主要會從以下四個方面來寫,分別是:
阿里大規模計算平臺運維面臨的一些挑戰;
阿里自動化平臺建設;
資料精細化運維;
我對運維轉型的思考和理解;
2、在阿里我們面對的挑戰
範倫挺
阿里巴巴 基礎架構事業群-技術專家
花名蕭一,2010年加入阿里巴巴,現任阿里巴巴集團大資料計算平臺運維負責人。團隊主要負責阿里巴巴各類離線上大資料計算平臺(如MaxCompute、AnalyticDB、StreamCompute等)的運維、架構優化及容量管理等
1、前言
本文主要會從以下四個方面來寫,分別是:
阿里大規模計算平臺運維面臨的一些挑戰;
阿里自動化平臺建設;
資料精細化運維;
我對運維轉型的思考和理解;
2、在阿里我們面對的挑戰
 在講挑戰之前,我們可以簡單看一下阿里大資料平臺演進歷史,我們的 MaxCompute(原ODPS)平臺是2011年4月上線的,2013年8月份單叢集超過5K,2015年6月單叢集超10K,目前在進行異地多活和離線上混布方面的事情。
在講挑戰之前,我們可以簡單看一下阿里大資料平臺演進歷史,我們的 MaxCompute(原ODPS)平臺是2011年4月上線的,2013年8月份單叢集超過5K,2015年6月單叢集超10K,目前在進行異地多活和離線上混布方面的事情。

 關於自動化平臺建設,自動化的意義我想讀者們應該是有共識的。
第一自動化能夠提升穩定性,機器的操作比人要靠譜,固化的操作交給機器去做,可以減少人犯錯機會,提高線上穩定性。
第二自動化能夠提高效率,機器代替人做很多事情之後,把我們從日常繁瑣運維操作中解放出來,解放出來以後我們可以做更有價值和意義的事情。
今天因為時間關係,我會從以下四個最常見自動化方向做簡單舉例介紹,變更、問題排查、硬體維修,交付檢查。右邊是我們內部用的運維平臺架構簡圖,下面介紹的東西都是基於這個平臺的功能模組。
3、 四步走讓平臺自動跑起來
關於自動化平臺建設,自動化的意義我想讀者們應該是有共識的。
第一自動化能夠提升穩定性,機器的操作比人要靠譜,固化的操作交給機器去做,可以減少人犯錯機會,提高線上穩定性。
第二自動化能夠提高效率,機器代替人做很多事情之後,把我們從日常繁瑣運維操作中解放出來,解放出來以後我們可以做更有價值和意義的事情。
今天因為時間關係,我會從以下四個最常見自動化方向做簡單舉例介紹,變更、問題排查、硬體維修,交付檢查。右邊是我們內部用的運維平臺架構簡圖,下面介紹的東西都是基於這個平臺的功能模組。
3、 四步走讓平臺自動跑起來  說到變更,做運維的總是有很多共同語言要聊。變更在我們日常工作中佔的時間還是比較多的,包括變更方案整理,變更跟進執行,都是比較耗時的,另外變更也是非常危險的。
原來有過統計,號稱70%穩定性事件是跟變更相關的,有可能是運維工程師直接變更操作引起的,也有可能是上線程式碼有 bug 引入的,這兩類都歸結在一起,反正是“線上不作不死,一作就死”。
但是不能因為這個不釋出,還有很多功能開發也是跟我們一樣,天天加班熬夜,搞出來的程式碼不給他推上去也說不過去,還要滿足業務需求,那這個問題得解。怎麼解呢?
我們內部思路是首先會把最底層的一些操作進行原子抽象,比如像把一臺機器從 VIP 裡摘取出來,裝一些包進行固化,固化之後抽象出來,稱為工作流,然後把工作流進行組裝把它稱之為組合工作流。
一個組合工作流對應一種日常的固化變更型別,比如控制叢集服務升級等等,這樣固化的變更就可以由對應的組合工作流去做。
在組合工作流之上,還會有一層封裝需求單。主要解決開發的自助申請,審批等環節。在工作流執行頁面可以檢視詳情,包括對應的每個步驟具體命令,返回資訊,執行超時時間,超時或者失敗的通知方式和人等等。
通過這樣一套平臺,基本上能夠解決日常固化的那一類變更請求,能夠做到變更由開發自己申請發起,運維只需稽核一些引數、測試報告等等。
3.2 第二步:高效穩定的解決問題
說到變更,做運維的總是有很多共同語言要聊。變更在我們日常工作中佔的時間還是比較多的,包括變更方案整理,變更跟進執行,都是比較耗時的,另外變更也是非常危險的。
原來有過統計,號稱70%穩定性事件是跟變更相關的,有可能是運維工程師直接變更操作引起的,也有可能是上線程式碼有 bug 引入的,這兩類都歸結在一起,反正是“線上不作不死,一作就死”。
但是不能因為這個不釋出,還有很多功能開發也是跟我們一樣,天天加班熬夜,搞出來的程式碼不給他推上去也說不過去,還要滿足業務需求,那這個問題得解。怎麼解呢?
我們內部思路是首先會把最底層的一些操作進行原子抽象,比如像把一臺機器從 VIP 裡摘取出來,裝一些包進行固化,固化之後抽象出來,稱為工作流,然後把工作流進行組裝把它稱之為組合工作流。
一個組合工作流對應一種日常的固化變更型別,比如控制叢集服務升級等等,這樣固化的變更就可以由對應的組合工作流去做。
在組合工作流之上,還會有一層封裝需求單。主要解決開發的自助申請,審批等環節。在工作流執行頁面可以檢視詳情,包括對應的每個步驟具體命令,返回資訊,執行超時時間,超時或者失敗的通知方式和人等等。
通過這樣一套平臺,基本上能夠解決日常固化的那一類變更請求,能夠做到變更由開發自己申請發起,運維只需稽核一些引數、測試報告等等。
3.2 第二步:高效穩定的解決問題
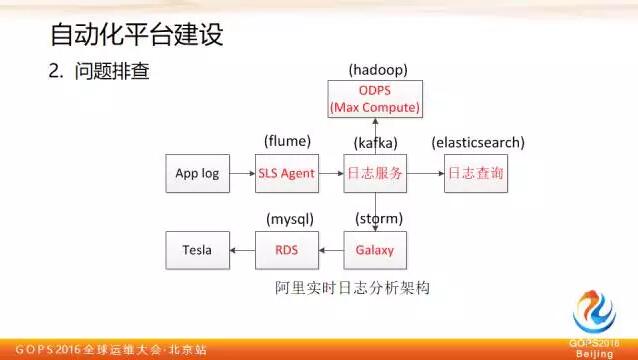 第二個例子是關於問題排查的,上圖畫的是我們當前用的實時日誌分析系統的架構,阿里因為這塊的產品自研的都有,所以用的都是自研的產品。
為了便於理解,我在邊上備註了對應的開源產品,基本上的流程或者邏輯也是比較好理解的,首先在伺服器上部署 Agent,Agent 會依據日誌服務裡配置的規則進行過濾以後,將對應的資訊推送到日誌服務。日誌服務裡資料可以實時進入到流計算平臺進行實時分析計算,並且把結果存到 RDS 裡面,然後 tesla 通過 RDS 進行調取和展現。
另外日誌服務存的資料,也會通過實時建立索引,提供 WEB 級別日誌查詢,幫助使用者做日誌查詢。同時也會匯入 max compute 做永久儲存和進一步分析。
基於這套系統,我們舉一個例子:異常流量排查。流量打滿是很常見的問題,通過這樣的機制怎麼幫忙我們排查和定位這些問題呢?
第二個例子是關於問題排查的,上圖畫的是我們當前用的實時日誌分析系統的架構,阿里因為這塊的產品自研的都有,所以用的都是自研的產品。
為了便於理解,我在邊上備註了對應的開源產品,基本上的流程或者邏輯也是比較好理解的,首先在伺服器上部署 Agent,Agent 會依據日誌服務裡配置的規則進行過濾以後,將對應的資訊推送到日誌服務。日誌服務裡資料可以實時進入到流計算平臺進行實時分析計算,並且把結果存到 RDS 裡面,然後 tesla 通過 RDS 進行調取和展現。
另外日誌服務存的資料,也會通過實時建立索引,提供 WEB 級別日誌查詢,幫助使用者做日誌查詢。同時也會匯入 max compute 做永久儲存和進一步分析。
基於這套系統,我們舉一個例子:異常流量排查。流量打滿是很常見的問題,通過這樣的機制怎麼幫忙我們排查和定位這些問題呢?
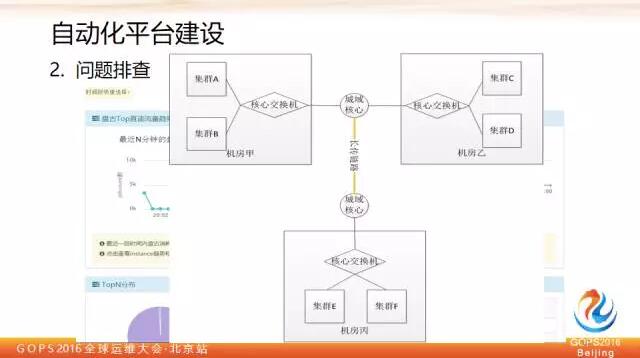 比如有N個機房,機房與機房之間有很多鏈路,每一條鏈路頻寬都是有限的,有時一個突發流量尖峰過來會導致流量擁塞,假設平臺上有一條鏈路,流量打滿以後,呈現黃色預警狀態,通過點選這條鏈路,就會進入流量分析實時介面。
比如有N個機房,機房與機房之間有很多鏈路,每一條鏈路頻寬都是有限的,有時一個突發流量尖峰過來會導致流量擁塞,假設平臺上有一條鏈路,流量打滿以後,呈現黃色預警狀態,通過點選這條鏈路,就會進入流量分析實時介面。
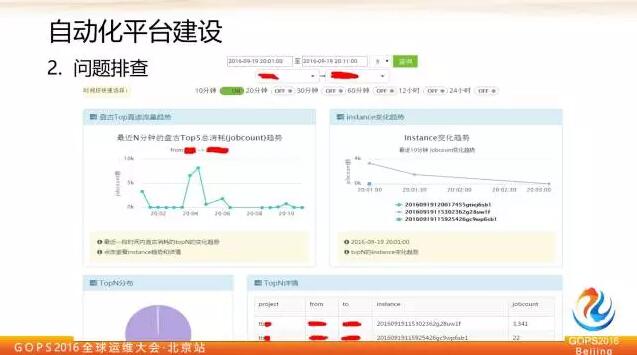 這裡可以看到從某個時間段到某個時間段,從某個機房到另外一個機房最近十分鐘的情況,這裡顯示的是最近十分鐘對應作業流量總的情況,點選流量最高的點可以在右側看到每個作業對於流量貢獻情況及其最近10分鐘的變化趨勢。
下面還可以列出來這些作業具體的專案歸屬,作業名稱等等。通過這個機制就可以很快定位到問題的原因。這裡收集的日誌是阿里雲飛天盤古 master audit log,盤古 master 有點類似 Hadoop 裡的 name node 節點,它會記錄所有叢集發起的資料訪問請求,包括來源 IP 是什麼,獲取資料大小是多少,發起的作業名稱等。
把這些資訊通過前面介紹的實時架構收集完之後,放到流計算平臺算,然後再結合網路地域和 IP 歸屬,就可以畫出整個網路拓撲和實時流量圖。
基於這套平臺還可以做很多其他的事情,比如說網路靜默丟包,這個理論上來講在網路層很難做到監控。但可以通過收集作業執行日誌,分析長尾和失敗的作業相應的源IP及目的IP分佈情況,可以發現某些交換機的異常情況。做到先進行隔離,再讓網工去排查解決。
3.3 第三步:更高效的硬體維護
這裡可以看到從某個時間段到某個時間段,從某個機房到另外一個機房最近十分鐘的情況,這裡顯示的是最近十分鐘對應作業流量總的情況,點選流量最高的點可以在右側看到每個作業對於流量貢獻情況及其最近10分鐘的變化趨勢。
下面還可以列出來這些作業具體的專案歸屬,作業名稱等等。通過這個機制就可以很快定位到問題的原因。這裡收集的日誌是阿里雲飛天盤古 master audit log,盤古 master 有點類似 Hadoop 裡的 name node 節點,它會記錄所有叢集發起的資料訪問請求,包括來源 IP 是什麼,獲取資料大小是多少,發起的作業名稱等。
把這些資訊通過前面介紹的實時架構收集完之後,放到流計算平臺算,然後再結合網路地域和 IP 歸屬,就可以畫出整個網路拓撲和實時流量圖。
基於這套平臺還可以做很多其他的事情,比如說網路靜默丟包,這個理論上來講在網路層很難做到監控。但可以通過收集作業執行日誌,分析長尾和失敗的作業相應的源IP及目的IP分佈情況,可以發現某些交換機的異常情況。做到先進行隔離,再讓網工去排查解決。
3.3 第三步:更高效的硬體維護
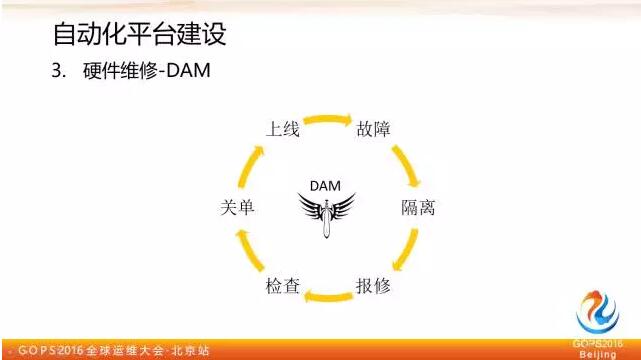 第三步是硬體維修,我們內部有個硬體全生命週期管理工具稱之為是 DAM,在日常工作中它能夠涵蓋整個硬體迴圈的生命週期,上線以後如果發現線上有硬體問題,它會調應用自定義的下線介面,把這臺機器從具體應用裡摘出來,從應用層面隔離完之後,再去調機房維修自動介面進行報修。
報修以後會監測這個維修單子狀態,等維修結單後,自動做上線前硬體檢查,檢查通過以後會把這個工單關閉,同時呼叫應用自定義的上線介面,完成伺服器上線。
所以這套東西基本上跟應用是屬於鬆耦合的,只要應用提供滿足條件的上下線 API 介面,基本上都可以轉起來。
第三步是硬體維修,我們內部有個硬體全生命週期管理工具稱之為是 DAM,在日常工作中它能夠涵蓋整個硬體迴圈的生命週期,上線以後如果發現線上有硬體問題,它會調應用自定義的下線介面,把這臺機器從具體應用裡摘出來,從應用層面隔離完之後,再去調機房維修自動介面進行報修。
報修以後會監測這個維修單子狀態,等維修結單後,自動做上線前硬體檢查,檢查通過以後會把這個工單關閉,同時呼叫應用自定義的上線介面,完成伺服器上線。
所以這套東西基本上跟應用是屬於鬆耦合的,只要應用提供滿足條件的上下線 API 介面,基本上都可以轉起來。
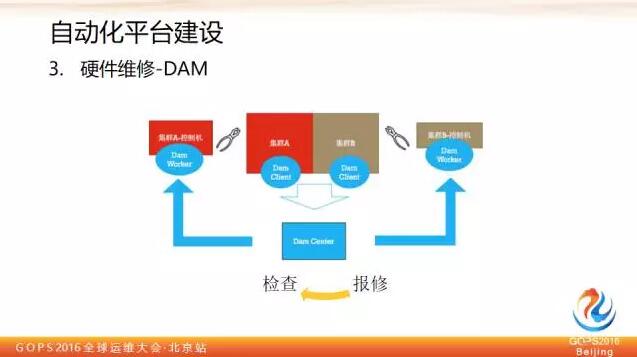 這是它的一個架構簡圖,主要有三大模組:Dam Worker 、Dam Client、Dam Center.
這裡面主要難點還是在於硬體資訊收集和分析,怎麼判斷這塊磁碟壞了,怎麼判斷 CPU 是有問題的。這其中需要長期的資料和經驗積累。
這裡我可以簡單介紹一下我們現在採集的資訊源:
硬碟主要依賴於 kernel log/smartctl/tsar
記憶體是 ipmitool/mcelog/stream,
CPU/風扇是 mcelog/cpu 頻率/ipmitool,
網路/網絡卡/交換機埠是tsar/kernel log。
主機板方面如果我們分析以後都不是以上資訊,那可能就是主機板的原因。
這是它的一個架構簡圖,主要有三大模組:Dam Worker 、Dam Client、Dam Center.
這裡面主要難點還是在於硬體資訊收集和分析,怎麼判斷這塊磁碟壞了,怎麼判斷 CPU 是有問題的。這其中需要長期的資料和經驗積累。
這裡我可以簡單介紹一下我們現在採集的資訊源:
硬碟主要依賴於 kernel log/smartctl/tsar
記憶體是 ipmitool/mcelog/stream,
CPU/風扇是 mcelog/cpu 頻率/ipmitool,
網路/網絡卡/交換機埠是tsar/kernel log。
主機板方面如果我們分析以後都不是以上資訊,那可能就是主機板的原因。
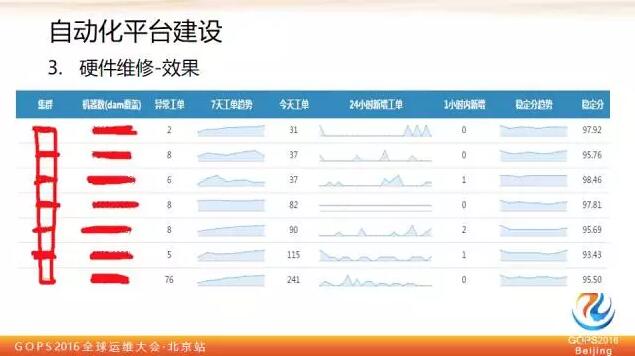 上面這個圖是一個最終的效果,這個系統在規模化場景下還是非常有用的,以前沒有這個的時候,值班人員是比較痛苦的,因為我們知道現在網際網路用的機器都不是高可靠的,去 IOE 都差不多了,都是廉價的伺服器,所以出現一些硬體問題還是比較常見的。
很可能一個電話過來,客戶就開始抱怨作業又長尾了,你上去一看,這個機器硬碟有問題,加入黑名單,重跑一下,使用者和我們自己都搞得很痛苦。
現在我們就不會因為單臺機器的硬體問題而受到騷擾了。主要白天看看那些異常工單原因,不斷優化邏輯即可。
對於這類自動處理我們肯定採取比較保守的策略,任何系統拿不準的或者不是完全精準匹配的就不動,先做隔離而不做進一步自動處理,放到異常工單池子裡,由人工介入分析異常 case 什麼原因,不斷完善我們硬體檢測判斷的模型。
3.4 第四步:完善的交付檢查
交付檢查分為軟體交付檢查和硬體交付檢查,軟體交付檢查就是用前面介紹過的工作流,硬體交付檢查主要針對 CPU、記憶體和磁碟,對於 CPU 做法是繫結每個 CPU 算 π,算算它的消耗時間分佈,最終把曲線畫出來,標準就是看曲線的偏離程度。
上面這個圖是一個最終的效果,這個系統在規模化場景下還是非常有用的,以前沒有這個的時候,值班人員是比較痛苦的,因為我們知道現在網際網路用的機器都不是高可靠的,去 IOE 都差不多了,都是廉價的伺服器,所以出現一些硬體問題還是比較常見的。
很可能一個電話過來,客戶就開始抱怨作業又長尾了,你上去一看,這個機器硬碟有問題,加入黑名單,重跑一下,使用者和我們自己都搞得很痛苦。
現在我們就不會因為單臺機器的硬體問題而受到騷擾了。主要白天看看那些異常工單原因,不斷優化邏輯即可。
對於這類自動處理我們肯定採取比較保守的策略,任何系統拿不準的或者不是完全精準匹配的就不動,先做隔離而不做進一步自動處理,放到異常工單池子裡,由人工介入分析異常 case 什麼原因,不斷完善我們硬體檢測判斷的模型。
3.4 第四步:完善的交付檢查
交付檢查分為軟體交付檢查和硬體交付檢查,軟體交付檢查就是用前面介紹過的工作流,硬體交付檢查主要針對 CPU、記憶體和磁碟,對於 CPU 做法是繫結每個 CPU 算 π,算算它的消耗時間分佈,最終把曲線畫出來,標準就是看曲線的偏離程度。
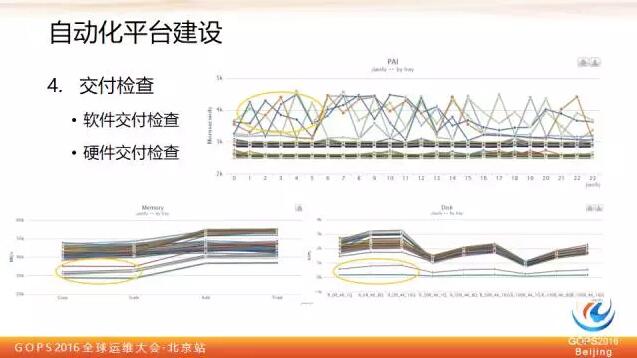 其實大家可以看出,大部分還是很規矩的,會集中在一起,類似上面有幾條偏離曲線的就是我們認為有問題的。那麼這裡大家可能會問,為什麼你這裡集中在兩個區段,是不是有一半的機器都是有問題的,其實是因為這個叢集機器是異構的,本來就有兩種型別的 cpu。
記憶體壓測採用通用的 stream 方法,就是對記憶體做拷貝、讀取相加,讀取做乘法諸如此類的,對於效能指標明顯偏離的機器也是有問題的。
磁碟主要用 Linux FIO 命令按照不同的讀寫比例和塊大小,來看它的表現。
其實這裡並沒有用到什麼高深的技術,我之所以拿來說是告訴大家這個極其重要,尤其是對於離線場景。離線計算在公司裡一般給的是都是更廉價,更低成本的硬體裝置,甚至很多時候線上應用退役的機器也會拿來用,即所謂的利舊。這種時候再加上機器是經過搬遷的話,那硬體的壓測就必須做,否則線上會很長時間不得消停。
4、資料驅動精細化運維
下面我們講講資料驅動精細化運維,今天主要是講一些點,舉一些例子,以此來表達我的一些想法。
其實大家可以看出,大部分還是很規矩的,會集中在一起,類似上面有幾條偏離曲線的就是我們認為有問題的。那麼這裡大家可能會問,為什麼你這裡集中在兩個區段,是不是有一半的機器都是有問題的,其實是因為這個叢集機器是異構的,本來就有兩種型別的 cpu。
記憶體壓測採用通用的 stream 方法,就是對記憶體做拷貝、讀取相加,讀取做乘法諸如此類的,對於效能指標明顯偏離的機器也是有問題的。
磁碟主要用 Linux FIO 命令按照不同的讀寫比例和塊大小,來看它的表現。
其實這裡並沒有用到什麼高深的技術,我之所以拿來說是告訴大家這個極其重要,尤其是對於離線場景。離線計算在公司裡一般給的是都是更廉價,更低成本的硬體裝置,甚至很多時候線上應用退役的機器也會拿來用,即所謂的利舊。這種時候再加上機器是經過搬遷的話,那硬體的壓測就必須做,否則線上會很長時間不得消停。
4、資料驅動精細化運維
下面我們講講資料驅動精細化運維,今天主要是講一些點,舉一些例子,以此來表達我的一些想法。
 大家都知道資料是有很大價值的,我們通過歷史資料分析,能夠知道平臺過去是發生過的事情,對於現在的資料分析,可以知道平臺現在正在發生的事情,還可以通過建模預測未來可能會發生的事情,所以資料可以說是能夠通曉過去未來之事。
我們運維的大資料平臺上每天都在產生海量的各種運維日誌、資訊,我們手裡擁有線上、離線,各種大資料平臺,我們也想把運維做得更精細化一些,可以說是有資料,有需求,有平臺,正可謂天時、地利、人和,所以一直在這方面做些嘗試。
4.1 實時大屏背後的精細化運維實踐
大家都知道資料是有很大價值的,我們通過歷史資料分析,能夠知道平臺過去是發生過的事情,對於現在的資料分析,可以知道平臺現在正在發生的事情,還可以通過建模預測未來可能會發生的事情,所以資料可以說是能夠通曉過去未來之事。
我們運維的大資料平臺上每天都在產生海量的各種運維日誌、資訊,我們手裡擁有線上、離線,各種大資料平臺,我們也想把運維做得更精細化一些,可以說是有資料,有需求,有平臺,正可謂天時、地利、人和,所以一直在這方面做些嘗試。
4.1 實時大屏背後的精細化運維實踐
 第一個例子是關於雙十一大促的,這個屏相信大家不會太陌生,這是雙十一大促在深圳晚會現場直播的一個媒體屏,上面有雙十一大促最終定格的成交額 1207億。
這是一個 GMV 翻牌器,它的作用就是實時彙總當前每一筆成交,並且把成交額顯示在上面,在光鮮亮麗的媒體屏背後,其實我們還有很多保障用的技術屏,今天就帶大家一起來看看其中的一塊技術屏。
第一個例子是關於雙十一大促的,這個屏相信大家不會太陌生,這是雙十一大促在深圳晚會現場直播的一個媒體屏,上面有雙十一大促最終定格的成交額 1207億。
這是一個 GMV 翻牌器,它的作用就是實時彙總當前每一筆成交,並且把成交額顯示在上面,在光鮮亮麗的媒體屏背後,其實我們還有很多保障用的技術屏,今天就帶大家一起來看看其中的一塊技術屏。
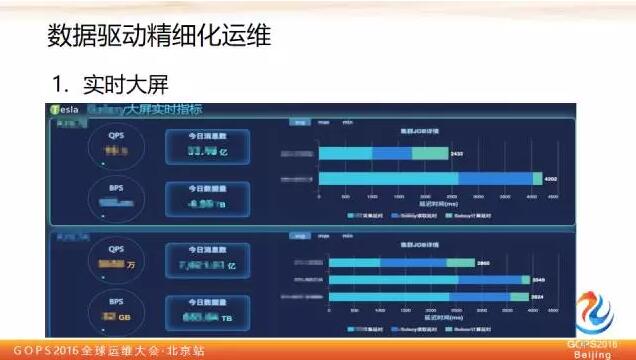 這上面的數字都抹掉了,簡單介紹一下我想說的事情,左邊部分是用於承載翻牌器成交額實時計算作業主備叢集負載情況,在它的右邊顯示的就是幾個關鍵的核心作業當前實時的延時情況,單位是毫秒。
這裡最右邊的這幾個白色的數字,代表了每個作業對應的延時,有了這個之後我們才能知道當前算的成交額比真實的使用者下單時間,它的延時有多大,超過一定的量,我們就要進行鏈路切換。
所以有了這個數字以後,可以更好地幫助我們判斷現在哪條鏈路是好的,哪條鏈路不好的,不好到什麼程度,好的話什麼程度,不能盲目的去拍腦袋判斷,需要有實時化的量化指標做評判。
這裡還要強調說明一點,這裡用不同的顏色深淺分成三段,這三段分別代表這個作業它的日誌採集延時、訊息佇列讀取延時和讀到之後計算的延時,把三段延時進行了分開展現,這個有什麼用呢?
當鏈路有問題之後,我們可以知道哪段出的問題,因為實時計算整個鏈路是非常長的,對於秒級應用來講,每個環節消耗的時間都是需要被清晰度量的,也就是說,有了這個時間你才能準確判斷現在是因為哪裡出現的瓶頸導致整體延時不達標。
也就是說,不但能夠知道哪條鏈路有問題,還可以知道鏈路具體問題點在哪,加快問題定位。
所以對於這個核心指標我建議大家做到三化
量化,這些壓力值都可以清晰看到。
細化,每個指標再分細一點,可以更精準判斷和定位問題。
持久化,這些實時屏不能看完就算了,還要把資料存起來,非常有用。
所以做到三化,量化、細化、持久化,在核心指標量化分析裡是很重要的。
4.2 儲存分析在精細化運維中的實踐
下面講一個儲存分析的例子,這個例子起源是因為叢集規模太大了,每年都被老闆盯著能不能省出一點錢來,我們分析了下儲存的資料,看看每個 byte 是被什麼佔用了,這是可以分析的。
這上面的數字都抹掉了,簡單介紹一下我想說的事情,左邊部分是用於承載翻牌器成交額實時計算作業主備叢集負載情況,在它的右邊顯示的就是幾個關鍵的核心作業當前實時的延時情況,單位是毫秒。
這裡最右邊的這幾個白色的數字,代表了每個作業對應的延時,有了這個之後我們才能知道當前算的成交額比真實的使用者下單時間,它的延時有多大,超過一定的量,我們就要進行鏈路切換。
所以有了這個數字以後,可以更好地幫助我們判斷現在哪條鏈路是好的,哪條鏈路不好的,不好到什麼程度,好的話什麼程度,不能盲目的去拍腦袋判斷,需要有實時化的量化指標做評判。
這裡還要強調說明一點,這裡用不同的顏色深淺分成三段,這三段分別代表這個作業它的日誌採集延時、訊息佇列讀取延時和讀到之後計算的延時,把三段延時進行了分開展現,這個有什麼用呢?
當鏈路有問題之後,我們可以知道哪段出的問題,因為實時計算整個鏈路是非常長的,對於秒級應用來講,每個環節消耗的時間都是需要被清晰度量的,也就是說,有了這個時間你才能準確判斷現在是因為哪裡出現的瓶頸導致整體延時不達標。
也就是說,不但能夠知道哪條鏈路有問題,還可以知道鏈路具體問題點在哪,加快問題定位。
所以對於這個核心指標我建議大家做到三化
量化,這些壓力值都可以清晰看到。
細化,每個指標再分細一點,可以更精準判斷和定位問題。
持久化,這些實時屏不能看完就算了,還要把資料存起來,非常有用。
所以做到三化,量化、細化、持久化,在核心指標量化分析裡是很重要的。
4.2 儲存分析在精細化運維中的實踐
下面講一個儲存分析的例子,這個例子起源是因為叢集規模太大了,每年都被老闆盯著能不能省出一點錢來,我們分析了下儲存的資料,看看每個 byte 是被什麼佔用了,這是可以分析的。
 我們通過分析之後得到右邊的圖,這個是真實的圖。看了這個圖之後,你會注意到,原來儲存是這麼被消耗的。其中我們可以找到一些應用層的優化。
譬如平臺是分層的,每一層為了資料安全都會做自己的回收站(延遲刪除)功能,站在每一層獨立去看都是合理的,但各種回收站累加在一起就會發現回收站佔用比例有些高(尤其是對於頻繁刪除型別應用)。可以從整體運維的角度去看,對於各層回收站策略做評估。
另外我們還發現一個優化點,就是 inode。我們可以計算下看看我們要不要用到這麼多 inode,按照PPT公式計算可能只需要原來的1.75%就夠了,萬臺叢集可以因此省下6PB的儲存。
當然這裡面實際適用 inode 大小還是要根據自己應用場景去評估。大家經常做資料運營,資料分析,其實它在很多地方都在那兒等著大家,有很多點可以去做,包括我們日常忽略的,司空見慣的,覺得不值一提的地方,大家可以細究一下,會發現那裡有另外一番天地。
4.3 精細化運維在資源優化上的成果
我們通過分析之後得到右邊的圖,這個是真實的圖。看了這個圖之後,你會注意到,原來儲存是這麼被消耗的。其中我們可以找到一些應用層的優化。
譬如平臺是分層的,每一層為了資料安全都會做自己的回收站(延遲刪除)功能,站在每一層獨立去看都是合理的,但各種回收站累加在一起就會發現回收站佔用比例有些高(尤其是對於頻繁刪除型別應用)。可以從整體運維的角度去看,對於各層回收站策略做評估。
另外我們還發現一個優化點,就是 inode。我們可以計算下看看我們要不要用到這麼多 inode,按照PPT公式計算可能只需要原來的1.75%就夠了,萬臺叢集可以因此省下6PB的儲存。
當然這裡面實際適用 inode 大小還是要根據自己應用場景去評估。大家經常做資料運營,資料分析,其實它在很多地方都在那兒等著大家,有很多點可以去做,包括我們日常忽略的,司空見慣的,覺得不值一提的地方,大家可以細究一下,會發現那裡有另外一番天地。
4.3 精細化運維在資源優化上的成果
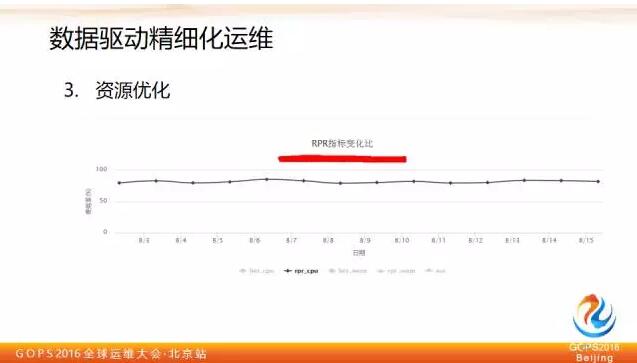 還有一個是資源優化例子,大家知道資源排程器裡有一個使用者資源申請的值,和申請之後真正跑起來的實際消耗值,我們建立了一個使用者實際消耗和使用者資源申請的比例,理想值我們希望接近100%,這個指標能夠說明排程模型的資源使用狀態,有了這樣的衡量指標之後,我們做進一步細化分解,看看怎麼優化這個指標。
這個是實時計算裡面作業的情況,每個作業我們會去看它的資源使用趨勢,這上面紅色的兩條直線是作業裡設的申請值,下面藍色波動比較大的是這一週來資源使用的尖峰值,大家可以看到即使按照這一週作業使用物理資源峰值來看,離申請值也是很遠的。
所以這裡面還是有不少優化的事情可以做,包括提醒使用者自己做優化,也可以在平臺層面自動做優化,來達到節省成本的目的。因為一旦排程器認為可以申請的資源都分配出去了,哪怕這時平臺物理水位非常低,它也不會排程更多的作業了,所以這件事情也是我們可以深度去做的。
5、如何擺脫苦逼運維的魔咒
5.1 轉向運營或許是破解之道
我個人對於運維轉型的一些理解和思考。運維轉型最近被談的比較多,有一個論調就是運維向運營轉。
還有一個是資源優化例子,大家知道資源排程器裡有一個使用者資源申請的值,和申請之後真正跑起來的實際消耗值,我們建立了一個使用者實際消耗和使用者資源申請的比例,理想值我們希望接近100%,這個指標能夠說明排程模型的資源使用狀態,有了這樣的衡量指標之後,我們做進一步細化分解,看看怎麼優化這個指標。
這個是實時計算裡面作業的情況,每個作業我們會去看它的資源使用趨勢,這上面紅色的兩條直線是作業裡設的申請值,下面藍色波動比較大的是這一週來資源使用的尖峰值,大家可以看到即使按照這一週作業使用物理資源峰值來看,離申請值也是很遠的。
所以這裡面還是有不少優化的事情可以做,包括提醒使用者自己做優化,也可以在平臺層面自動做優化,來達到節省成本的目的。因為一旦排程器認為可以申請的資源都分配出去了,哪怕這時平臺物理水位非常低,它也不會排程更多的作業了,所以這件事情也是我們可以深度去做的。
5、如何擺脫苦逼運維的魔咒
5.1 轉向運營或許是破解之道
我個人對於運維轉型的一些理解和思考。運維轉型最近被談的比較多,有一個論調就是運維向運營轉。
 這個問題我是這麼看的,傳統運維更多關注的是平臺穩定、安全,也就是非常傳統的兩個領域,更多關心的是平臺是不是活著,這個平臺沒有出問題,沒有掛掉,這是傳統運維關心的事情,重點關鍵詞活著。
對於運營來說,除了活著,還要看平臺質量怎麼樣,使用者用得好不好,這個平臺本身它的效益怎麼樣,它的成本是不是還能進一步優化,使用者感受怎麼樣,使用者滿意度怎麼樣。
而對運維來講,包括運營,我們大部分都是跟垂直的具體產品或者平臺繫結的。不可能完全脫離他們,去談運維的價值。
所以運營是以一種更積極開放的態度,去看待我們所運維的物件,多看一點,不光看它的活著,還想想怎麼能夠幫助它和自己一起去成長和發展。
5.2 自動化在轉型過程中的四個階段
然後講到轉型逃不開自動化,我個人認為自動化可以分為四個階段:
這個問題我是這麼看的,傳統運維更多關注的是平臺穩定、安全,也就是非常傳統的兩個領域,更多關心的是平臺是不是活著,這個平臺沒有出問題,沒有掛掉,這是傳統運維關心的事情,重點關鍵詞活著。
對於運營來說,除了活著,還要看平臺質量怎麼樣,使用者用得好不好,這個平臺本身它的效益怎麼樣,它的成本是不是還能進一步優化,使用者感受怎麼樣,使用者滿意度怎麼樣。
而對運維來講,包括運營,我們大部分都是跟垂直的具體產品或者平臺繫結的。不可能完全脫離他們,去談運維的價值。
所以運營是以一種更積極開放的態度,去看待我們所運維的物件,多看一點,不光看它的活著,還想想怎麼能夠幫助它和自己一起去成長和發展。
5.2 自動化在轉型過程中的四個階段
然後講到轉型逃不開自動化,我個人認為自動化可以分為四個階段:
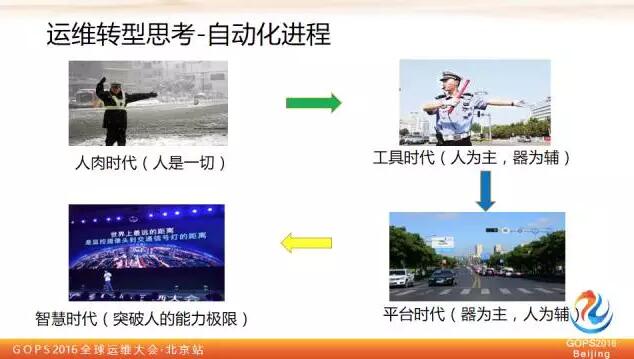 第一個階段人肉時代
這時候人就是一切,你說了算,你說什麼命令就是什麼命令,這時候沒有任何校驗標準機制,就像交警純人肉指揮交通一樣,什麼時候讓你走就走,什麼時候讓你停你就停。
第二階段工具時代
好比交警手裡的指揮棒和哨子,這些工具提升了他的個人能力,比如哨子可以讓更遠的車輛聽到他的指令,棒子可以在天氣不好的時候讓汽車看到他的指令。
這個階段還是以我們人為主體,工具在能力上做了一定延伸和拓展,但是始終還是人為主,器為輔。還是人在決定這個操作要不要做,什麼時候做,引數應該是什麼。只是人做完決定後,可以由工具搞定具體落地執行,提升了執行效率,節約下來了時間。
但是離開了人還是什麼也不是。所以這個時代,單兵作戰能力增強了,但是人逐漸成為整個運維的瓶頸點,因為工具的能力是遠遠大於人的能力的,更多需求就堆在你手裡的,你怎麼編排和控制。你成為瓶頸點了,工具越多,人的瓶頸點就會凸顯。
第三個階段平臺時代
這個階段過渡到器為主,人為輔的階段,還是以交通舉例,這裡面大家可以看到由很多工具沉澱變成了完整的交通疏導指揮平臺,包括紅綠燈,包括限速和車道劃分等等,這一系列規則和工具,最終不是零散的在那裡放著,而是通過一個有序組織變成一個固化的平臺,通過這個平臺,能夠完成交警日常工作中交通疏導的事情。
對於我們運維也一樣,我們怎麼把我們的經驗、想法和技能放到平臺裡,最終變化自助或者自動化運維平臺,這樣的時代才能稱之為平臺時代,就像我剛才前面說的變更平臺一樣。
我不知道大家有沒有經歷過,其實很多公司經歷過,變更平臺可能有很多不同的人開發過很多撥,第一撥可能是開發寫的,第二撥可能是工具團隊寫的,第三撥可能是運維團隊自己寫的。
這裡做一個變更平臺並不難,難的是怎麼把運維的想法和思考沉澱到平臺裡面去,怎麼讓平臺有和你相當的能力,這時候它才能代替你日常的職責,所以它這裡面的靈魂和思想很重要。
同樣是做開發變更平臺,開發考慮的是怎麼快速高效的執行變更,那運維做的時候會有些什麼更多的思考呢?
你會考慮是否有灰度功能,是不是應該先灰度釋出一部分,然後有自動冒煙機制,冒煙過了我再引流,然後有沒有快速回滾機制,這就是區別,為什麼我們要自己去做,自己轉型,我覺得別人很難理解我們,也很難救我們,所以要自己轉型做自己想要的運維平臺。
這裡面大家多想想你平常怎麼工作的,重要的是把你的能力進行平臺化,而不僅僅是簡單開發一個系統。
第四個階段智慧時代
第一個時代是人解決問題,第二個時代是人藉助工具更好的解決問題,第三個時代是讓平臺能像人一樣解決問題,第四個時代是讓平臺超越人類能力去解決問題。這張圖是阿里雲棲大會上王博士釋出城市大腦的照片。城市大腦是解決城市交通擁堵問題,這個問題已經突破人的能力極限,安排再多的交警到各路口執勤也搞不定這件事。
但城市大腦可以,它通過對每天的車流量預測資料,再加上其他的一些補充資料,包括實時紅綠燈,每個探頭採集到的實時流量等等,把這些資料進行綜合判斷,它就能夠智慧的實時控制所有的交通訊號燈,從而達到緩解城市擁堵的目標。
在這裡其實一樣的,當上升到一個智慧時代以後,平臺能力就能夠突破人的極限,做到一些人的能力以外的事情,譬如故障的預測、快速自恢復等等。這也是未來的方向——智慧運維時代。
5.3 運維效率向運維價值轉型
第一個階段人肉時代
這時候人就是一切,你說了算,你說什麼命令就是什麼命令,這時候沒有任何校驗標準機制,就像交警純人肉指揮交通一樣,什麼時候讓你走就走,什麼時候讓你停你就停。
第二階段工具時代
好比交警手裡的指揮棒和哨子,這些工具提升了他的個人能力,比如哨子可以讓更遠的車輛聽到他的指令,棒子可以在天氣不好的時候讓汽車看到他的指令。
這個階段還是以我們人為主體,工具在能力上做了一定延伸和拓展,但是始終還是人為主,器為輔。還是人在決定這個操作要不要做,什麼時候做,引數應該是什麼。只是人做完決定後,可以由工具搞定具體落地執行,提升了執行效率,節約下來了時間。
但是離開了人還是什麼也不是。所以這個時代,單兵作戰能力增強了,但是人逐漸成為整個運維的瓶頸點,因為工具的能力是遠遠大於人的能力的,更多需求就堆在你手裡的,你怎麼編排和控制。你成為瓶頸點了,工具越多,人的瓶頸點就會凸顯。
第三個階段平臺時代
這個階段過渡到器為主,人為輔的階段,還是以交通舉例,這裡面大家可以看到由很多工具沉澱變成了完整的交通疏導指揮平臺,包括紅綠燈,包括限速和車道劃分等等,這一系列規則和工具,最終不是零散的在那裡放著,而是通過一個有序組織變成一個固化的平臺,通過這個平臺,能夠完成交警日常工作中交通疏導的事情。
對於我們運維也一樣,我們怎麼把我們的經驗、想法和技能放到平臺裡,最終變化自助或者自動化運維平臺,這樣的時代才能稱之為平臺時代,就像我剛才前面說的變更平臺一樣。
我不知道大家有沒有經歷過,其實很多公司經歷過,變更平臺可能有很多不同的人開發過很多撥,第一撥可能是開發寫的,第二撥可能是工具團隊寫的,第三撥可能是運維團隊自己寫的。
這裡做一個變更平臺並不難,難的是怎麼把運維的想法和思考沉澱到平臺裡面去,怎麼讓平臺有和你相當的能力,這時候它才能代替你日常的職責,所以它這裡面的靈魂和思想很重要。
同樣是做開發變更平臺,開發考慮的是怎麼快速高效的執行變更,那運維做的時候會有些什麼更多的思考呢?
你會考慮是否有灰度功能,是不是應該先灰度釋出一部分,然後有自動冒煙機制,冒煙過了我再引流,然後有沒有快速回滾機制,這就是區別,為什麼我們要自己去做,自己轉型,我覺得別人很難理解我們,也很難救我們,所以要自己轉型做自己想要的運維平臺。
這裡面大家多想想你平常怎麼工作的,重要的是把你的能力進行平臺化,而不僅僅是簡單開發一個系統。
第四個階段智慧時代
第一個時代是人解決問題,第二個時代是人藉助工具更好的解決問題,第三個時代是讓平臺能像人一樣解決問題,第四個時代是讓平臺超越人類能力去解決問題。這張圖是阿里雲棲大會上王博士釋出城市大腦的照片。城市大腦是解決城市交通擁堵問題,這個問題已經突破人的能力極限,安排再多的交警到各路口執勤也搞不定這件事。
但城市大腦可以,它通過對每天的車流量預測資料,再加上其他的一些補充資料,包括實時紅綠燈,每個探頭採集到的實時流量等等,把這些資料進行綜合判斷,它就能夠智慧的實時控制所有的交通訊號燈,從而達到緩解城市擁堵的目標。
在這裡其實一樣的,當上升到一個智慧時代以後,平臺能力就能夠突破人的極限,做到一些人的能力以外的事情,譬如故障的預測、快速自恢復等等。這也是未來的方向——智慧運維時代。
5.3 運維效率向運維價值轉型
 假如我們前面的自動化事情做得不錯了,有時間了,該乾點什麼,原來有一句老話叫做“喝著咖啡幹運維”,我個人認為這個觀點從生活的角度來講是不錯的,但從工作和個人發展的角度來看還是太過於消極了。
當你達到這個階段,如果你真這麼去做的話,慢慢你可能有時間喝咖啡,但卻沒錢喝了,很有可能會被淘汰掉。我們應該轉變思路,更多的去關注資料分析,視覺化及運維平臺的產品化。
當我們建立了前面說的自動化運維平臺以後,可以更多去想一想如何通過資料分析,讓我們運維平臺更加智慧,達到一個智慧運維的時代。利用計算機強大的計算能力,最終實現機器管理機器的目標。另一方面也可以藉助資料分析和運營,幫助我們所運維的產品做改善,如效能、易用性、成本等等。
另外我們也要更多的去思考怎麼把運維平臺進一步產品化,使我們的運維能力可以輸出,產生更大的價值。
這些目標都是可以實現的,當然有很多的事情需要去做,我們可以分階段的,先從一些簡單的事情做起,逐步深入。
6、最後的思考
假如我們前面的自動化事情做得不錯了,有時間了,該乾點什麼,原來有一句老話叫做“喝著咖啡幹運維”,我個人認為這個觀點從生活的角度來講是不錯的,但從工作和個人發展的角度來看還是太過於消極了。
當你達到這個階段,如果你真這麼去做的話,慢慢你可能有時間喝咖啡,但卻沒錢喝了,很有可能會被淘汰掉。我們應該轉變思路,更多的去關注資料分析,視覺化及運維平臺的產品化。
當我們建立了前面說的自動化運維平臺以後,可以更多去想一想如何通過資料分析,讓我們運維平臺更加智慧,達到一個智慧運維的時代。利用計算機強大的計算能力,最終實現機器管理機器的目標。另一方面也可以藉助資料分析和運營,幫助我們所運維的產品做改善,如效能、易用性、成本等等。
另外我們也要更多的去思考怎麼把運維平臺進一步產品化,使我們的運維能力可以輸出,產生更大的價值。
這些目標都是可以實現的,當然有很多的事情需要去做,我們可以分階段的,先從一些簡單的事情做起,逐步深入。
6、最後的思考
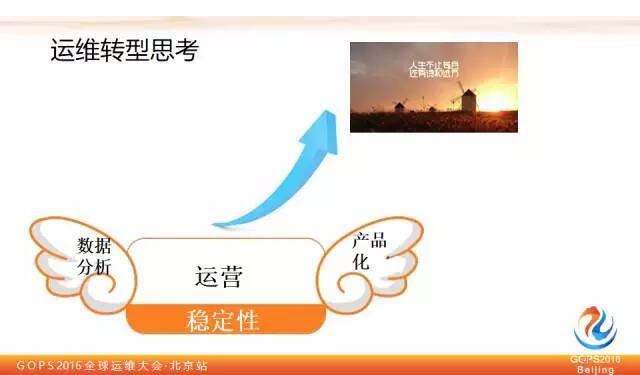 最後用一張圖來總結我對於運維轉型的思考。運維應該始終以穩定性為基石,一旦脫離穩定性,其他一切都是扯淡,都是浮雲。在穩定性基礎之上,我們應該以更積極的運營思路來思考我們自身的發展和平臺的發展,藉助於資料分析和運維能力產品化這樣兩個翅膀,實現華麗的轉型。運維的人生不止苟且,還有詩和遠方!
最後用一張圖來總結我對於運維轉型的思考。運維應該始終以穩定性為基石,一旦脫離穩定性,其他一切都是扯淡,都是浮雲。在穩定性基礎之上,我們應該以更積極的運營思路來思考我們自身的發展和平臺的發展,藉助於資料分析和運維能力產品化這樣兩個翅膀,實現華麗的轉型。運維的人生不止苟且,還有詩和遠方!
範倫挺
阿里巴巴 基礎架構事業群-技術專家
花名蕭一,2010年加入阿里巴巴,現任阿里巴巴集團大資料計算平臺運維負責人。團隊主要負責阿里巴巴各類離線上大資料計算平臺(如MaxCompute、AnalyticDB、StreamCompute等)的運維、架構優化及容量管理等
1、前言
本文主要會從以下四個方面來寫,分別是:
阿里大規模計算平臺運維面臨的一些挑戰;
阿里自動化平臺建設;
資料精細化運維;
我對運維轉型的思考和理解;
2、在阿里我們面對的挑戰
在講挑戰之前,我們可以簡單看一下阿里大資料平臺演進歷史,我們的 MaxCompute(原ODPS)平臺是2011年4月上線的,2013年8月份單叢集超過5K,2015年6月單叢集超10K,目前在進行異地多活和離線上混布方面的事情。
關於自動化平臺建設,自動化的意義我想讀者們應該是有共識的。
第一自動化能夠提升穩定性,機器的操作比人要靠譜,固化的操作交給機器去做,可以減少人犯錯機會,提高線上穩定性。
第二自動化能夠提高效率,機器代替人做很多事情之後,把我們從日常繁瑣運維操作中解放出來,解放出來以後我們可以做更有價值和意義的事情。
今天因為時間關係,我會從以下四個最常見自動化方向做簡單舉例介紹,變更、問題排查、硬體維修,交付檢查。右邊是我們內部用的運維平臺架構簡圖,下面介紹的東西都是基於這個平臺的功能模組。
3、 四步走讓平臺自動跑起來
說到變更,做運維的總是有很多共同語言要聊。變更在我們日常工作中佔的時間還是比較多的,包括變更方案整理,變更跟進執行,都是比較耗時的,另外變更也是非常危險的。
原來有過統計,號稱70%穩定性事件是跟變更相關的,有可能是運維工程師直接變更操作引起的,也有可能是上線程式碼有 bug 引入的,這兩類都歸結在一起,反正是“線上不作不死,一作就死”。
但是不能因為這個不釋出,還有很多功能開發也是跟我們一樣,天天加班熬夜,搞出來的程式碼不給他推上去也說不過去,還要滿足業務需求,那這個問題得解。怎麼解呢?
我們內部思路是首先會把最底層的一些操作進行原子抽象,比如像把一臺機器從 VIP 裡摘取出來,裝一些包進行固化,固化之後抽象出來,稱為工作流,然後把工作流進行組裝把它稱之為組合工作流。
一個組合工作流對應一種日常的固化變更型別,比如控制叢集服務升級等等,這樣固化的變更就可以由對應的組合工作流去做。
在組合工作流之上,還會有一層封裝需求單。主要解決開發的自助申請,審批等環節。在工作流執行頁面可以檢視詳情,包括對應的每個步驟具體命令,返回資訊,執行超時時間,超時或者失敗的通知方式和人等等。
通過這樣一套平臺,基本上能夠解決日常固化的那一類變更請求,能夠做到變更由開發自己申請發起,運維只需稽核一些引數、測試報告等等。
3.2 第二步:高效穩定的解決問題
第二個例子是關於問題排查的,上圖畫的是我們當前用的實時日誌分析系統的架構,阿里因為這塊的產品自研的都有,所以用的都是自研的產品。
為了便於理解,我在邊上備註了對應的開源產品,基本上的流程或者邏輯也是比較好理解的,首先在伺服器上部署 Agent,Agent 會依據日誌服務裡配置的規則進行過濾以後,將對應的資訊推送到日誌服務。日誌服務裡資料可以實時進入到流計算平臺進行實時分析計算,並且把結果存到 RDS 裡面,然後 tesla 通過 RDS 進行調取和展現。
另外日誌服務存的資料,也會通過實時建立索引,提供 WEB 級別日誌查詢,幫助使用者做日誌查詢。同時也會匯入 max compute 做永久儲存和進一步分析。
基於這套系統,我們舉一個例子:異常流量排查。流量打滿是很常見的問題,通過這樣的機制怎麼幫忙我們排查和定位這些問題呢?
比如有N個機房,機房與機房之間有很多鏈路,每一條鏈路頻寬都是有限的,有時一個突發流量尖峰過來會導致流量擁塞,假設平臺上有一條鏈路,流量打滿以後,呈現黃色預警狀態,通過點選這條鏈路,就會進入流量分析實時介面。
這裡可以看到從某個時間段到某個時間段,從某個機房到另外一個機房最近十分鐘的情況,這裡顯示的是最近十分鐘對應作業流量總的情況,點選流量最高的點可以在右側看到每個作業對於流量貢獻情況及其最近10分鐘的變化趨勢。
下面還可以列出來這些作業具體的專案歸屬,作業名稱等等。通過這個機制就可以很快定位到問題的原因。這裡收集的日誌是阿里雲飛天盤古 master audit log,盤古 master 有點類似 Hadoop 裡的 name node 節點,它會記錄所有叢集發起的資料訪問請求,包括來源 IP 是什麼,獲取資料大小是多少,發起的作業名稱等。
把這些資訊通過前面介紹的實時架構收集完之後,放到流計算平臺算,然後再結合網路地域和 IP 歸屬,就可以畫出整個網路拓撲和實時流量圖。
基於這套平臺還可以做很多其他的事情,比如說網路靜默丟包,這個理論上來講在網路層很難做到監控。但可以通過收集作業執行日誌,分析長尾和失敗的作業相應的源IP及目的IP分佈情況,可以發現某些交換機的異常情況。做到先進行隔離,再讓網工去排查解決。
3.3 第三步:更高效的硬體維護
第三步是硬體維修,我們內部有個硬體全生命週期管理工具稱之為是 DAM,在日常工作中它能夠涵蓋整個硬體迴圈的生命週期,上線以後如果發現線上有硬體問題,它會調應用自定義的下線介面,把這臺機器從具體應用裡摘出來,從應用層面隔離完之後,再去調機房維修自動介面進行報修。
報修以後會監測這個維修單子狀態,等維修結單後,自動做上線前硬體檢查,檢查通過以後會把這個工單關閉,同時呼叫應用自定義的上線介面,完成伺服器上線。
所以這套東西基本上跟應用是屬於鬆耦合的,只要應用提供滿足條件的上下線 API 介面,基本上都可以轉起來。
這是它的一個架構簡圖,主要有三大模組:Dam Worker 、Dam Client、Dam Center.
這裡面主要難點還是在於硬體資訊收集和分析,怎麼判斷這塊磁碟壞了,怎麼判斷 CPU 是有問題的。這其中需要長期的資料和經驗積累。
這裡我可以簡單介紹一下我們現在採集的資訊源:
硬碟主要依賴於 kernel log/smartctl/tsar
記憶體是 ipmitool/mcelog/stream,
CPU/風扇是 mcelog/cpu 頻率/ipmitool,
網路/網絡卡/交換機埠是tsar/kernel log。
主機板方面如果我們分析以後都不是以上資訊,那可能就是主機板的原因。
上面這個圖是一個最終的效果,這個系統在規模化場景下還是非常有用的,以前沒有這個的時候,值班人員是比較痛苦的,因為我們知道現在網際網路用的機器都不是高可靠的,去 IOE 都差不多了,都是廉價的伺服器,所以出現一些硬體問題還是比較常見的。
很可能一個電話過來,客戶就開始抱怨作業又長尾了,你上去一看,這個機器硬碟有問題,加入黑名單,重跑一下,使用者和我們自己都搞得很痛苦。
現在我們就不會因為單臺機器的硬體問題而受到騷擾了。主要白天看看那些異常工單原因,不斷優化邏輯即可。
對於這類自動處理我們肯定採取比較保守的策略,任何系統拿不準的或者不是完全精準匹配的就不動,先做隔離而不做進一步自動處理,放到異常工單池子裡,由人工介入分析異常 case 什麼原因,不斷完善我們硬體檢測判斷的模型。
3.4 第四步:完善的交付檢查
交付檢查分為軟體交付檢查和硬體交付檢查,軟體交付檢查就是用前面介紹過的工作流,硬體交付檢查主要針對 CPU、記憶體和磁碟,對於 CPU 做法是繫結每個 CPU 算 π,算算它的消耗時間分佈,最終把曲線畫出來,標準就是看曲線的偏離程度。
其實大家可以看出,大部分還是很規矩的,會集中在一起,類似上面有幾條偏離曲線的就是我們認為有問題的。那麼這裡大家可能會問,為什麼你這裡集中在兩個區段,是不是有一半的機器都是有問題的,其實是因為這個叢集機器是異構的,本來就有兩種型別的 cpu。
記憶體壓測採用通用的 stream 方法,就是對記憶體做拷貝、讀取相加,讀取做乘法諸如此類的,對於效能指標明顯偏離的機器也是有問題的。
磁碟主要用 Linux FIO 命令按照不同的讀寫比例和塊大小,來看它的表現。
其實這裡並沒有用到什麼高深的技術,我之所以拿來說是告訴大家這個極其重要,尤其是對於離線場景。離線計算在公司裡一般給的是都是更廉價,更低成本的硬體裝置,甚至很多時候線上應用退役的機器也會拿來用,即所謂的利舊。這種時候再加上機器是經過搬遷的話,那硬體的壓測就必須做,否則線上會很長時間不得消停。
4、資料驅動精細化運維
下面我們講講資料驅動精細化運維,今天主要是講一些點,舉一些例子,以此來表達我的一些想法。
大家都知道資料是有很大價值的,我們通過歷史資料分析,能夠知道平臺過去是發生過的事情,對於現在的資料分析,可以知道平臺現在正在發生的事情,還可以通過建模預測未來可能會發生的事情,所以資料可以說是能夠通曉過去未來之事。
我們運維的大資料平臺上每天都在產生海量的各種運維日誌、資訊,我們手裡擁有線上、離線,各種大資料平臺,我們也想把運維做得更精細化一些,可以說是有資料,有需求,有平臺,正可謂天時、地利、人和,所以一直在這方面做些嘗試。
4.1 實時大屏背後的精細化運維實踐
第一個例子是關於雙十一大促的,這個屏相信大家不會太陌生,這是雙十一大促在深圳晚會現場直播的一個媒體屏,上面有雙十一大促最終定格的成交額 1207億。
這是一個 GMV 翻牌器,它的作用就是實時彙總當前每一筆成交,並且把成交額顯示在上面,在光鮮亮麗的媒體屏背後,其實我們還有很多保障用的技術屏,今天就帶大家一起來看看其中的一塊技術屏。
這上面的數字都抹掉了,簡單介紹一下我想說的事情,左邊部分是用於承載翻牌器成交額實時計算作業主備叢集負載情況,在它的右邊顯示的就是幾個關鍵的核心作業當前實時的延時情況,單位是毫秒。
這裡最右邊的這幾個白色的數字,代表了每個作業對應的延時,有了這個之後我們才能知道當前算的成交額比真實的使用者下單時間,它的延時有多大,超過一定的量,我們就要進行鏈路切換。
所以有了這個數字以後,可以更好地幫助我們判斷現在哪條鏈路是好的,哪條鏈路不好的,不好到什麼程度,好的話什麼程度,不能盲目的去拍腦袋判斷,需要有實時化的量化指標做評判。
這裡還要強調說明一點,這裡用不同的顏色深淺分成三段,這三段分別代表這個作業它的日誌採集延時、訊息佇列讀取延時和讀到之後計算的延時,把三段延時進行了分開展現,這個有什麼用呢?
當鏈路有問題之後,我們可以知道哪段出的問題,因為實時計算整個鏈路是非常長的,對於秒級應用來講,每個環節消耗的時間都是需要被清晰度量的,也就是說,有了這個時間你才能準確判斷現在是因為哪裡出現的瓶頸導致整體延時不達標。
也就是說,不但能夠知道哪條鏈路有問題,還可以知道鏈路具體問題點在哪,加快問題定位。
所以對於這個核心指標我建議大家做到三化
量化,這些壓力值都可以清晰看到。
細化,每個指標再分細一點,可以更精準判斷和定位問題。
持久化,這些實時屏不能看完就算了,還要把資料存起來,非常有用。
所以做到三化,量化、細化、持久化,在核心指標量化分析裡是很重要的。
4.2 儲存分析在精細化運維中的實踐
下面講一個儲存分析的例子,這個例子起源是因為叢集規模太大了,每年都被老闆盯著能不能省出一點錢來,我們分析了下儲存的資料,看看每個 byte 是被什麼佔用了,這是可以分析的。
我們通過分析之後得到右邊的圖,這個是真實的圖。看了這個圖之後,你會注意到,原來儲存是這麼被消耗的。其中我們可以找到一些應用層的優化。
譬如平臺是分層的,每一層為了資料安全都會做自己的回收站(延遲刪除)功能,站在每一層獨立去看都是合理的,但各種回收站累加在一起就會發現回收站佔用比例有些高(尤其是對於頻繁刪除型別應用)。可以從整體運維的角度去看,對於各層回收站策略做評估。
另外我們還發現一個優化點,就是 inode。我們可以計算下看看我們要不要用到這麼多 inode,按照PPT公式計算可能只需要原來的1.75%就夠了,萬臺叢集可以因此省下6PB的儲存。
當然這裡面實際適用 inode 大小還是要根據自己應用場景去評估。大家經常做資料運營,資料分析,其實它在很多地方都在那兒等著大家,有很多點可以去做,包括我們日常忽略的,司空見慣的,覺得不值一提的地方,大家可以細究一下,會發現那裡有另外一番天地。
4.3 精細化運維在資源優化上的成果
還有一個是資源優化例子,大家知道資源排程器裡有一個使用者資源申請的值,和申請之後真正跑起來的實際消耗值,我們建立了一個使用者實際消耗和使用者資源申請的比例,理想值我們希望接近100%,這個指標能夠說明排程模型的資源使用狀態,有了這樣的衡量指標之後,我們做進一步細化分解,看看怎麼優化這個指標。
這個是實時計算裡面作業的情況,每個作業我們會去看它的資源使用趨勢,這上面紅色的兩條直線是作業裡設的申請值,下面藍色波動比較大的是這一週來資源使用的尖峰值,大家可以看到即使按照這一週作業使用物理資源峰值來看,離申請值也是很遠的。
所以這裡面還是有不少優化的事情可以做,包括提醒使用者自己做優化,也可以在平臺層面自動做優化,來達到節省成本的目的。因為一旦排程器認為可以申請的資源都分配出去了,哪怕這時平臺物理水位非常低,它也不會排程更多的作業了,所以這件事情也是我們可以深度去做的。
5、如何擺脫苦逼運維的魔咒
5.1 轉向運營或許是破解之道
我個人對於運維轉型的一些理解和思考。運維轉型最近被談的比較多,有一個論調就是運維向運營轉。
這個問題我是這麼看的,傳統運維更多關注的是平臺穩定、安全,也就是非常傳統的兩個領域,更多關心的是平臺是不是活著,這個平臺沒有出問題,沒有掛掉,這是傳統運維關心的事情,重點關鍵詞活著。
對於運營來說,除了活著,還要看平臺質量怎麼樣,使用者用得好不好,這個平臺本身它的效益怎麼樣,它的成本是不是還能進一步優化,使用者感受怎麼樣,使用者滿意度怎麼樣。
而對運維來講,包括運營,我們大部分都是跟垂直的具體產品或者平臺繫結的。不可能完全脫離他們,去談運維的價值。
所以運營是以一種更積極開放的態度,去看待我們所運維的物件,多看一點,不光看它的活著,還想想怎麼能夠幫助它和自己一起去成長和發展。
5.2 自動化在轉型過程中的四個階段
然後講到轉型逃不開自動化,我個人認為自動化可以分為四個階段:
第一個階段人肉時代
這時候人就是一切,你說了算,你說什麼命令就是什麼命令,這時候沒有任何校驗標準機制,就像交警純人肉指揮交通一樣,什麼時候讓你走就走,什麼時候讓你停你就停。
第二階段工具時代
好比交警手裡的指揮棒和哨子,這些工具提升了他的個人能力,比如哨子可以讓更遠的車輛聽到他的指令,棒子可以在天氣不好的時候讓汽車看到他的指令。
這個階段還是以我們人為主體,工具在能力上做了一定延伸和拓展,但是始終還是人為主,器為輔。還是人在決定這個操作要不要做,什麼時候做,引數應該是什麼。只是人做完決定後,可以由工具搞定具體落地執行,提升了執行效率,節約下來了時間。
但是離開了人還是什麼也不是。所以這個時代,單兵作戰能力增強了,但是人逐漸成為整個運維的瓶頸點,因為工具的能力是遠遠大於人的能力的,更多需求就堆在你手裡的,你怎麼編排和控制。你成為瓶頸點了,工具越多,人的瓶頸點就會凸顯。
第三個階段平臺時代
這個階段過渡到器為主,人為輔的階段,還是以交通舉例,這裡面大家可以看到由很多工具沉澱變成了完整的交通疏導指揮平臺,包括紅綠燈,包括限速和車道劃分等等,這一系列規則和工具,最終不是零散的在那裡放著,而是通過一個有序組織變成一個固化的平臺,通過這個平臺,能夠完成交警日常工作中交通疏導的事情。
對於我們運維也一樣,我們怎麼把我們的經驗、想法和技能放到平臺裡,最終變化自助或者自動化運維平臺,這樣的時代才能稱之為平臺時代,就像我剛才前面說的變更平臺一樣。
我不知道大家有沒有經歷過,其實很多公司經歷過,變更平臺可能有很多不同的人開發過很多撥,第一撥可能是開發寫的,第二撥可能是工具團隊寫的,第三撥可能是運維團隊自己寫的。
這裡做一個變更平臺並不難,難的是怎麼把運維的想法和思考沉澱到平臺裡面去,怎麼讓平臺有和你相當的能力,這時候它才能代替你日常的職責,所以它這裡面的靈魂和思想很重要。
同樣是做開發變更平臺,開發考慮的是怎麼快速高效的執行變更,那運維做的時候會有些什麼更多的思考呢?
你會考慮是否有灰度功能,是不是應該先灰度釋出一部分,然後有自動冒煙機制,冒煙過了我再引流,然後有沒有快速回滾機制,這就是區別,為什麼我們要自己去做,自己轉型,我覺得別人很難理解我們,也很難救我們,所以要自己轉型做自己想要的運維平臺。
這裡面大家多想想你平常怎麼工作的,重要的是把你的能力進行平臺化,而不僅僅是簡單開發一個系統。
第四個階段智慧時代
第一個時代是人解決問題,第二個時代是人藉助工具更好的解決問題,第三個時代是讓平臺能像人一樣解決問題,第四個時代是讓平臺超越人類能力去解決問題。這張圖是阿里雲棲大會上王博士釋出城市大腦的照片。城市大腦是解決城市交通擁堵問題,這個問題已經突破人的能力極限,安排再多的交警到各路口執勤也搞不定這件事。
但城市大腦可以,它通過對每天的車流量預測資料,再加上其他的一些補充資料,包括實時紅綠燈,每個探頭採集到的實時流量等等,把這些資料進行綜合判斷,它就能夠智慧的實時控制所有的交通訊號燈,從而達到緩解城市擁堵的目標。
在這裡其實一樣的,當上升到一個智慧時代以後,平臺能力就能夠突破人的極限,做到一些人的能力以外的事情,譬如故障的預測、快速自恢復等等。這也是未來的方向——智慧運維時代。
5.3 運維效率向運維價值轉型
假如我們前面的自動化事情做得不錯了,有時間了,該乾點什麼,原來有一句老話叫做“喝著咖啡幹運維”,我個人認為這個觀點從生活的角度來講是不錯的,但從工作和個人發展的角度來看還是太過於消極了。
當你達到這個階段,如果你真這麼去做的話,慢慢你可能有時間喝咖啡,但卻沒錢喝了,很有可能會被淘汰掉。我們應該轉變思路,更多的去關注資料分析,視覺化及運維平臺的產品化。
當我們建立了前面說的自動化運維平臺以後,可以更多去想一想如何通過資料分析,讓我們運維平臺更加智慧,達到一個智慧運維的時代。利用計算機強大的計算能力,最終實現機器管理機器的目標。另一方面也可以藉助資料分析和運營,幫助我們所運維的產品做改善,如效能、易用性、成本等等。
另外我們也要更多的去思考怎麼把運維平臺進一步產品化,使我們的運維能力可以輸出,產生更大的價值。
這些目標都是可以實現的,當然有很多的事情需要去做,我們可以分階段的,先從一些簡單的事情做起,逐步深入。
6、最後的思考
最後用一張圖來總結我對於運維轉型的思考。運維應該始終以穩定性為基石,一旦脫離穩定性,其他一切都是扯淡,都是浮雲。在穩定性基礎之上,我們應該以更積極的運營思路來思考我們自身的發展和平臺的發展,藉助於資料分析和運維能力產品化這樣兩個翅膀,實現華麗的轉型。運維的人生不止苟且,還有詩和遠方!