
第40課: CacheManager徹底解密:CacheManager執行原理流程圖和原始碼詳解
第40課: CacheManager徹底解密:CacheManager執行原理流程圖和原始碼詳解
CacheManager管理是快取,而快取可以是基於記憶體的快取,也可以是基於磁碟的快取。CacheManager需要通過BlockManager來操作資料。
Task發生計算的時候要呼叫RDD的compute進行計算。我們看一下MapPartitionsRDD的compute方法:
MapPartitionsRDD的原始碼:
1. private[spark] class MapPartitionsRDD[U:ClassTag, T: ClassTag](
2. var prev: RDD[T],
3. f: (TaskContext, Int, Iterator[T]) =>Iterator[U], // (TaskContext, partitionindex, iterator)
4. preservesPartitioning: Boolean = false)
5. extends RDD[U](prev) {
6.
7. override val partitioner = if(preservesPartitioning) firstParent[T].partitioner else None
8.
9. override def getPartitions: Array[Partition]= firstParent[T].partitions
10.
11. override def compute(split: Partition,context: TaskContext): Iterator[U] =
12. f(context, split.index,firstParent[T].iterator(split, context))
13.
14. override def clearDependencies() {
15. super.clearDependencies()
16. prev = null
17. }
18. }
compute真正計算的時候通過iterator計算,MapPartitionsRDD的iterator依賴父RDD計算。iterator是RDD內部的方法,如有快取將從快取中讀取資料,否則進行計算。這不是被使用者直接呼叫,但可用於實現自定義子RDD。
RDD.scala的iterator方法:
1. final def iterator(split: Partition, context:TaskContext): Iterator[T] = {
2. if (storageLevel != StorageLevel.NONE) {
3. getOrCompute(split, context)
4. } else {
5. computeOrReadCheckpoint(split, context)
6. }
7. }
RDD.scala的iterator方法中判斷storageLevel!= StorageLevel.NONE說明資料可能存放記憶體、磁碟中,呼叫getOrCompute(split, context)方法。如果之前計算過一次,再次計算可以找CacheManager要資料。
RDD.scala的getOrCompute原始碼:
1. private[spark] def getOrCompute(partition:Partition, context: TaskContext): Iterator[T] = {
2. val blockId = RDDBlockId(id,partition.index)
3. var readCachedBlock = true
4. // This method is called on executors, sowe need call SparkEnv.get instead of sc.env.
5. SparkEnv.get.blockManager.getOrElseUpdate(blockId,storageLevel, elementClassTag, () => {
6. readCachedBlock = false
7. computeOrReadCheckpoint(partition, context)
8. }) match {
9. case Left(blockResult) =>
10. if (readCachedBlock) {
11. val existingMetrics =context.taskMetrics().inputMetrics
12. existingMetrics.incBytesRead(blockResult.bytes)
13. new InterruptibleIterator[T](context,blockResult.data.asInstanceOf[Iterator[T]]) {
14. override def next(): T = {
15. existingMetrics.incRecordsRead(1)
16. delegate.next()
17. }
18. }
19. } else {
20. new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])
21. }
22. case Right(iter) =>
23. new InterruptibleIterator(context,iter.asInstanceOf[Iterator[T]])
24. }
25. }
有快取的情況下,快取可能基於記憶體也可能基於磁碟,getOrCompute獲取快取;如沒有快取則需重新計算RDD。為何需要重新計算?如果資料放在記憶體中,假設快取了1百萬個數據分片,下一個步驟計算的時候需要記憶體,因為需要進行計算的記憶體空間佔用比之前快取的資料佔用記憶體空間重要,假設需騰出1萬個資料分片所在的空間,因此從BlockManager中將記憶體中的快取資料drop到磁碟上,如果不是記憶體和磁碟的儲存級別,那1萬個資料分片的快取資料就可能丟失,99萬個資料分片可以複用,而這1萬個資料分片需重新進行計算。
Cache在工作的時候會最大化的保留資料,但是資料不一定絕對完整,因為當前的計算如果需要記憶體空間的話,那麼Cache在記憶體中的資料必須讓出空間,此時如何在RDD持久化的時候同時指定了可以把資料放在Disk上,那麼部分Cache的資料就可以從記憶體轉入磁碟,否則的話,資料就會丟失!
getOrCompute方法返回的是Iterator。進行了Cache以後,BlockManager對其進行管理,通過blockId可以獲得曾經快取的資料。具體CacheManager在獲得快取資料的時候會通過BlockManager來抓到資料:
getOrElseUpdate方法中:如果block存在,檢索給定的塊block;如果不存在,則呼叫提供`makeIterator`方法計算塊block,對塊block進行持久化,並返回block的值。
BlockManager.scala的getOrElseUpdate原始碼:
1. defgetOrElseUpdate[T](
2. blockId: BlockId,
3. level: StorageLevel,
4. classTag: ClassTag[T],
5. makeIterator: () => Iterator[T]):Either[BlockResult, Iterator[T]] = {
6. // Attempt to read the block from local orremote storage. If it's present, then we don't need
7. // to go through the local-get-or-put path.
8. get[T](blockId)(classTag) match {
9. case Some(block) =>
10. return Left(block)
11. case _ =>
12. // Need to compute the block.
13. }
14. // Initially we hold no locks on thisblock.
15. doPutIterator(blockId, makeIterator, level,classTag, keepReadLock = true) match {
16. case None =>
17. // doPut() didn't hand work back to us,so the block already existed or was successfully
18. // stored. Therefore, we now hold aread lock on the block.
19. val blockResult =getLocalValues(blockId).getOrElse {
20. // Since we held a read lock betweenthe doPut() and get() calls, the block should not
21. // have been evicted, so get() notreturning the block indicates some internal error.
22. releaseLock(blockId)
23. throw new SparkException(s"get()failed for block $blockId even though we held a lock")
24. }
25. // We already hold a read lock on theblock from the doPut() call and getLocalValues()
26. // acquires the lock again, so we needto call releaseLock() here so that the net number
27. // of lock acquisitions is 1 (since thecaller will only call release() once).
28. releaseLock(blockId)
29. Left(blockResult)
30. case Some(iter) =>
31. // The put failed, likely because thedata was too large to fit in memory and could not be
32. // dropped to disk. Therefore, we needto pass the input iterator back to the caller so
33. // that they can decide what to do withthe values (e.g. process them without caching).
34. Right(iter)
35. }
36. }
BlockManager.scala的getOrElseUpdate中根據blockId呼叫了get[T](blockId)方法,get方法從block塊管理器(本地或遠端)獲取一個塊block。如果塊在本地儲存且沒獲取鎖,則先獲取塊block的讀取鎖。如果該塊是從遠端塊管理器獲取的,當`data`迭代器被完全消費以後,那麼讀取鎖將自動釋放。
BlockManager.scala的get方法原始碼如下:
1. def get[T: ClassTag](blockId: BlockId):Option[BlockResult] = {
2. val local = getLocalValues(blockId)
3. if (local.isDefined) {
4. logInfo(s"Found block $blockIdlocally")
5. return local
6. }
7. val remote = getRemoteValues[T](blockId)
8. if (remote.isDefined) {
9. logInfo(s"Found block $blockIdremotely")
10. return remote
11. }
12. None
13. }
BlockManager.的get方法從Local的角度講:如果資料在本地,get方法呼叫getLocalValues獲取資料。如果資料如果在記憶體中(level.useMemory且memoryStore包含了blockId),則從memoryStore中獲取資料;如果資料在磁碟中(level.useDisk且diskStore包含了blockId),則從diskStore中獲取資料。這說明資料在本地快取,可以在記憶體中,也可以在磁碟上。
BlockManager.scala的getLocalValues方法原始碼如下:
1. def getLocalValues(blockId: BlockId):Option[BlockResult] = {
2. logDebug(s"Getting local block$blockId")
3. blockInfoManager.lockForReading(blockId)match {
4. case None =>
5. logDebug(s"Block $blockId was notfound")
6. None
7. case Some(info) =>
8. val level = info.level
9. logDebug(s"Level for block$blockId is $level")
10. if (level.useMemory &&memoryStore.contains(blockId)) {
11. val iter: Iterator[Any] = if(level.deserialized) {
12. memoryStore.getValues(blockId).get
13. } else {
14. serializerManager.dataDeserializeStream(
15. blockId,memoryStore.getBytes(blockId).get.toInputStream())(info.classTag)
16. }
17. val ci = CompletionIterator[Any,Iterator[Any]](iter, releaseLock(blockId))
18. Some(new BlockResult(ci,DataReadMethod.Memory, info.size))
19. } else if (level.useDisk &&diskStore.contains(blockId)) {
20. val iterToReturn: Iterator[Any] = {
21. val diskBytes =diskStore.getBytes(blockId)
22. if (level.deserialized) {
23. val diskValues =serializerManager.dataDeserializeStream(
24. blockId,
25. diskBytes.toInputStream(dispose= true))(info.classTag)
26. maybeCacheDiskValuesInMemory(info,blockId, level, diskValues)
27. } else {
28. val stream =maybeCacheDiskBytesInMemory(info, blockId, level, diskBytes)
29. .map {_.toInputStream(dispose =false)}
30. .getOrElse {diskBytes.toInputStream(dispose = true) }
31. serializerManager.dataDeserializeStream(blockId,stream)(info.classTag)
32. }
33. }
34. val ci = CompletionIterator[Any,Iterator[Any]](iterToReturn, releaseLock(blockId))
35. Some(new BlockResult(ci,DataReadMethod.Disk, info.size))
36. } else {
37. handleLocalReadFailure(blockId)
38. }
39. }
40. }
BlockManager的get方法從remote的角度講:get方法中將呼叫getRemoteValues方法。
BlockManager.Scala的getRemoteValues原始碼:
1. private def getRemoteValues[T:ClassTag](blockId: BlockId): Option[BlockResult] = {
2. val ct = implicitly[ClassTag[T]]
3. getRemoteBytes(blockId).map { data =>
4. val values =
5. serializerManager.dataDeserializeStream(blockId,data.toInputStream(dispose = true))(ct)
6. new BlockResult(values,DataReadMethod.Network, data.size)
7. }
8. }
getRemoteValues方法中呼叫getRemoteBytes方法,通過blockTransferService.fetchBlockSync從遠端節點獲取資料。
BlockManager.Scala的getRemoteBytes原始碼:
1. defgetRemoteBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
2. logDebug(s"Getting remote block$blockId")
3. require(blockId != null, "BlockId isnull")
4. var runningFailureCount = 0
5. var totalFailureCount = 0
6. val locations = getLocations(blockId)
7. val maxFetchFailures = locations.size
8. var locationIterator = locations.iterator
9. while (locationIterator.hasNext) {
10. val loc = locationIterator.next()
11. logDebug(s"Getting remote block$blockId from $loc")
12. val data = try {
13. blockTransferService.fetchBlockSync(
14. loc.host, loc.port, loc.executorId,blockId.toString).nioByteBuffer()
15. } catch {
16. case NonFatal(e) =>
17. runningFailureCount += 1
18. totalFailureCount += 1
19.
20. if (totalFailureCount >=maxFetchFailures) {
21. // Give up trying anymorelocations. Either we've tried all of the original locations,
22. // or we've refreshed the list oflocations from the master, and have still
23. // hit failures after tryinglocations from the refreshed list.
24. logWarning(s"Failed to fetchblock after $totalFailureCount fetch failures. " +
25. s"Most recent failurecause:", e)
26. return None
27. }
28.
29. logWarning(s"Failed to fetchremote block $blockId " +
30. s"from $loc (failed attempt$runningFailureCount)", e)
31.
32. // If there is a large number ofexecutors then locations list can contain a
33. // large number of stale entriescausing a large number of retries that may
34. // take a significant amount of time.To get rid of these stale entries
35. // we refresh the block locationsafter a certain number of fetch failures
36. if (runningFailureCount >=maxFailuresBeforeLocationRefresh) {
37. locationIterator =getLocations(blockId).iterator
38. logDebug(s"Refreshed locationsfrom the driver " +
39. s"after${runningFailureCount} fetch failures.")
40. runningFailureCount = 0
41. }
42.
43. // This location failed, so we retryfetch from a different one by returning null here
44. null
45. }
46.
47. if (data != null) {
48. return Some(newChunkedByteBuffer(data))
49. }
50. logDebug(s"The value of block $blockIdis null")
51. }
52. logDebug(s"Block $blockId notfound")
53. None
54. }
BlockManager的get方法,如果本地有資料,從本地獲取資料返回;如果遠端有資料,從遠端獲取資料返回;如果都沒有資料,就返回None。get方法的返回型別是Option[BlockResult],Option的結果分為二種情況:1,如果有內容,返回Some[BlockResult]2,如果沒有內容,返回None。這是Option的基礎語法。
Option.scala原始碼如下:
1. sealedabstract class Option[+A] extends Product with Serializable {
2. self =>
3. .....
4. final case class Some[+A](x: A)extends Option[A] {
5. def isEmpty = false
6. def get = x
7. }
8.
9. .......
10. case object None extendsOption[Nothing] {
11. def isEmpty = true
12. def get = throw newNoSuchElementException("None.get")
13. }
回到BlockManager的getOrElseUpdate方法,從get方法返回的結果進行模式匹配,如果有資料,則對Some(block)返回Left(block),這是獲取到block的情況;如果沒資料,則是None,需進行計算block。
BlockManager的getOrElseUpdate原始碼:
1. defgetOrElseUpdate[T](
2. blockId: BlockId,
3. level: StorageLevel,
4. classTag: ClassTag[T],
5. makeIterator: () => Iterator[T]):Either[BlockResult, Iterator[T]] = {
6. // Attempt to read the block from local orremote storage. If it's present, then we don't need
7. // to go through the local-get-or-put path.
8. get[T](blockId)(classTag) match {
9. case Some(block) =>
10. return Left(block)
11. case _ =>
12. // Need to compute the block.
13. }
14. ......
回到RDD.scala的getOrCompute方法, 在getOrCompute方法中呼叫SparkEnv.get.blockManager.getOrElseUpdate方法時,傳入blockId、storageLevel、elementClassTag,其中第四個引數是一個匿名函式,在匿名函式中呼叫了computeOrReadCheckpoint(partition, context)。然後在getOrElseUpdate方法中,根據blockId獲取資料,如果獲取到快取資料,就返回;如果沒有資料,就呼叫doPutIterator(blockId, makeIterator, level, classTag, keepReadLock =true)進行計算,doPutIterator其中第二個引數makeIterator就是getOrElseUpdate方法中傳入的匿名函式,在匿名函式獲取到的Iterator資料。
RDD. getOrCompute原始碼:
1. private[spark] def getOrCompute(partition:Partition, context: TaskContext): Iterator[T] = {
2. val blockId = RDDBlockId(id,partition.index)
3. var readCachedBlock = true
4. // This method is called on executors, sowe need call SparkEnv.get instead of sc.env.
5. SparkEnv.get.blockManager.getOrElseUpdate(blockId,storageLevel, elementClassTag, () => {
6. readCachedBlock = false
7. computeOrReadCheckpoint(partition,context)
8. })
9. …….
其中computeOrReadCheckpoint方法, 如果RDD進行了checkpoint,則從父RDD的iterator中直接獲取資料;或者沒有Checkpoint物化,則重新計算RDD的資料。
RDD.scala的computeOrReadCheckpoint原始碼:
1. private[spark] def computeOrReadCheckpoint(split:Partition, context: TaskContext): Iterator[T] =
2. {
3. if (isCheckpointedAndMaterialized) {
4. firstParent[T].iterator(split, context)
5. } else {
6. compute(split, context)
7. }
8. }
BlockManager.scala的getOrElseUpdate方法中如果根據blockID沒有獲取到本地資料,則呼叫doPutIterator將通過BlockManager再次進行持久化。。
BlockManager.scala的getOrElseUpdate方法原始碼:
1. def getOrElseUpdate[T](
2. blockId: BlockId,
3. level: StorageLevel,
4. classTag: ClassTag[T],
5. makeIterator: () => Iterator[T]):Either[BlockResult, Iterator[T]] = {
6. // Attempt to read the block from local orremote storage. If it's present, then we don't need
7. // to go through the local-get-or-put path.
8. get[T](blockId)(classTag) match {
9. case Some(block) =>
10. return Left(block)
11. case _ =>
12. // Need to compute the block.
13. }
14. // Initially we hold no locks on thisblock.
15. doPutIterator(blockId, makeIterator, level,classTag, keepReadLock = true) match {
16. …….
BlockManager.scala的getOrElseUpdate方法中呼叫了doPutIterator,doPutIterator將makeIterator從父RDD的checkpoint讀取的資料或者重新計算的資料存放到記憶體中,如果記憶體不夠,就溢位到磁碟中持久化。
BlockManager.scala的doPutIterator方法原始碼:
1. privatedef doPutIterator[T](
2. blockId: BlockId,
3. iterator: () => Iterator[T],
4. level: StorageLevel,
5. classTag: ClassTag[T],
6. tellMaster: Boolean = true,
7. keepReadLock: Boolean = false):Option[PartiallyUnrolledIterator[T]] = {
8. doPut(blockId, level, classTag, tellMaster= tellMaster, keepReadLock = keepReadLock) { info =>
9. val startTimeMs =System.currentTimeMillis
10. var iteratorFromFailedMemoryStorePut:Option[PartiallyUnrolledIterator[T]] = None
11. // Size of the block in bytes
12. var size = 0L
13. if (level.useMemory) {
14. // Put it in memory first, even if italso has useDisk set to true;
15. // We will drop it to disk later if thememory store can't hold it.
16. if (level.deserialized) {
17. memoryStore.putIteratorAsValues(blockId,iterator(), classTag) match {
18. case Right(s) =>
19. size = s
20. case Left(iter) =>
21. // Not enough space to unrollthis block; drop to disk if applicable
22. if (level.useDisk) {
23. logWarning(s"Persistingblock $blockId to disk instead.")
24. diskStore.put(blockId) {fileOutputStream =>
25. serializerManager.dataSerializeStream(blockId,fileOutputStream, iter)(classTag)
26. }
27. size =diskStore.getSize(blockId)
28. } else {
29. iteratorFromFailedMemoryStorePut= Some(iter)
30. }
31. }
32. } else { // !level.deserialized
33. memoryStore.putIteratorAsBytes(blockId,iterator(), classTag, level.memoryMode) match {
34. case Right(s) =>
35. size = s
36. caseLeft(partiallySerializedValues) =>
37. // Not enough space to unrollthis block; drop to disk if applicable
38. if (level.useDisk) {
39. logWarning(s"Persistingblock $blockId to disk instead.")
40. diskStore.put(blockId) {fileOutputStream =>
41. partiallySerializedValues.finishWritingToStream(fileOutputStream)
42. }
43. size = diskStore.getSize(blockId)
44. } else {
45. iteratorFromFailedMemoryStorePut= Some(partiallySerializedValues.valuesIterator)
46. }
47. }
48. }
49.
50. } else if (level.useDisk) {
51. diskStore.put(blockId) {fileOutputStream =>
52. serializerManager.dataSerializeStream(blockId,fileOutputStream, iterator())(classTag)
53. }
54. size = diskStore.getSize(blockId)
55. }
56.
57. val putBlockStatus =getCurrentBlockStatus(blockId, info)
58. val blockWasSuccessfullyStored =putBlockStatus.storageLevel.isValid
59. if (blockWasSuccessfullyStored) {
60. // Now that the block is in either thememory or disk store, tell the master about it.
61. info.size = size
62. if (tellMaster &&info.tellMaster) {
63. reportBlockStatus(blockId,putBlockStatus)
64. }
65. addUpdatedBlockStatusToTaskMetrics(blockId,putBlockStatus)
66. logDebug("Put block %s locallytook %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
67. if (level.replication > 1) {
68. val remoteStartTime =System.currentTimeMillis
69. val bytesToReplicate =doGetLocalBytes(blockId, info)
70. // [SPARK-16550] Erase the typedclassTag when using default serialization, since
71. // NettyBlockRpcServer crashes whendeserializing repl-defined classes.
72. // TODO(ekl) remove this once theclassloader issue on the remote end is fixed.
73. val remoteClassTag = if(!serializerManager.canUseKryo(classTag)) {
74. scala.reflect.classTag[Any]
75. } else {
76. classTag
77. }
78. try {
79. replicate(blockId,bytesToReplicate, level, remoteClassTag)
80. } finally {
81. bytesToReplicate.unmap()
82. }
83. logDebug("Put block %s remotelytook %s"
84. .format(blockId,Utils.getUsedTimeMs(remoteStartTime)))
85. }
86. }
87. assert(blockWasSuccessfullyStored ==iteratorFromFailedMemoryStorePut.isEmpty)
88. iteratorFromFailedMemoryStorePut
89. }
90. }
總結CacheManager內幕解密如下:
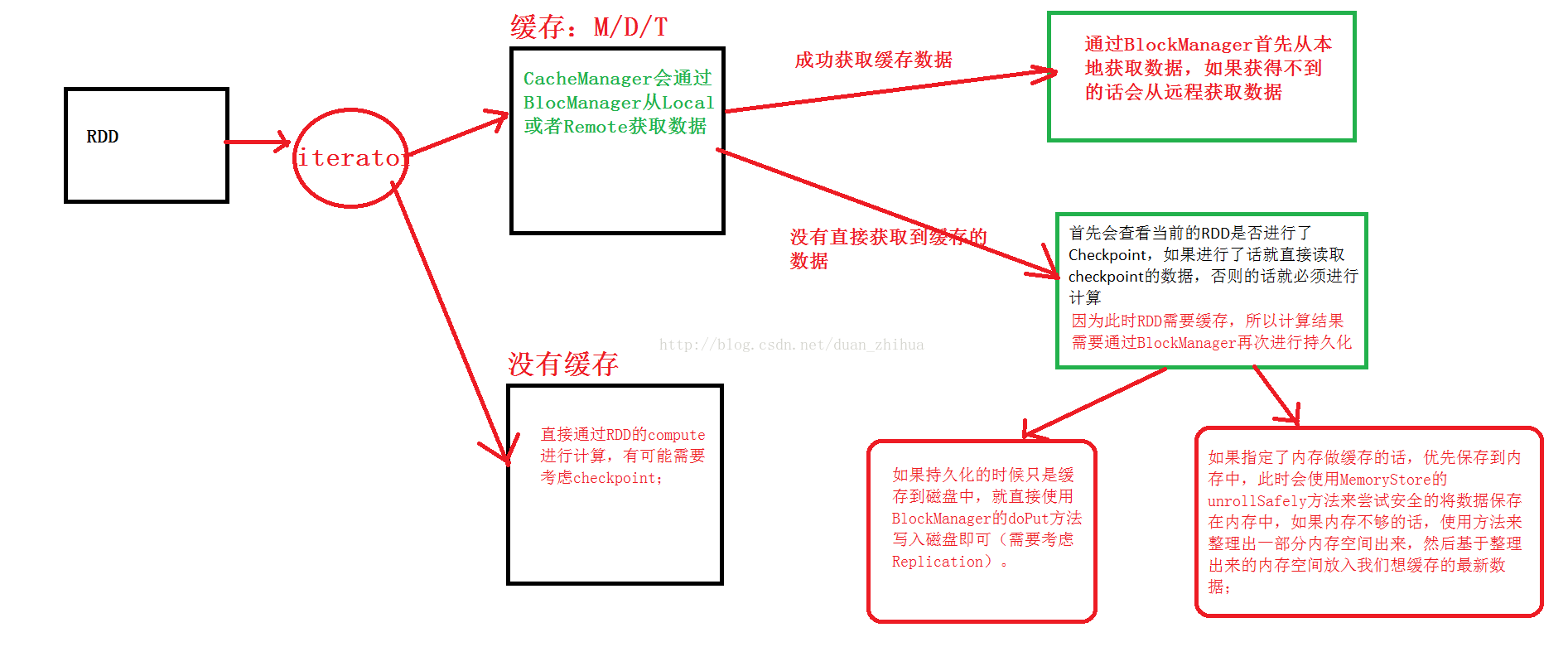
圖 9- 1 Cache示意圖
首先呼叫RDD的iterator方法:
(一)如果在記憶體或磁碟中有快取,則通過BlockManager從Local或者Remote獲取資料。
l 如果成功獲取快取資料,通過BlockManager首先從本地獲取資料,如果獲得不到資料,則從遠端獲取資料。
l 如果沒有直接獲取快取資料,首先會檢視當前的RDD是否進行了Checkpoint,如果進行了Checkpoint就直接讀取Checkpoint的資料,否則必須進行計算。因為此時RDD需要快取,所以計算結果需要通過BlockManager再次進行持久化。
1)如果持久化的時候只是快取到磁碟中,就直接使用BlockManager的doPut方法寫入磁碟(需要考慮replication副本)的情況。
2)如果指定了記憶體做快取,優先儲存到記憶體中,此時使用memoryStore的unrollSafely方法來嘗試安全的將資料儲存到記憶體中,如果記憶體不夠的話,使用方法整理出一部分空間,然後基於整理出來的記憶體空間放入我們想快取的最新資料。
(二)如果在記憶體或磁碟中沒有快取,直接通過RDD的compute進行計算,有可能需要考慮Checkpoint。