
瀏覽器工作原理詳解
這篇文章是以色列開發人員塔利·加希爾的研究成果。她在查閱了所有公開發布的關於瀏覽器內部機制的資料,並花了很多時間來研讀網路瀏覽器的原始碼。她寫道:
在 IE 佔據 90%市場份額的年代,我們除了把瀏覽器當成一個“黑箱”,什麼也做不了。但是現在,開放原始碼的瀏覽器擁有了過半的市場份額,因此,是時候來揭開神祕的面紗,一探網路瀏覽器的內幕了。呃,裡面只有數以百萬行計的C++ 程式碼…
作為一名網路開發人員,學習瀏覽器的內部工作原理將有助於您作出更明智的決策,並理解那些最佳開發實踐的箇中緣由。儘管這是一篇相當長的文件,但是我們建議您花些時間來仔細閱讀;讀完之後,您肯定會覺得所費不虛。
保羅·愛麗詩(Paul Irish),Chrome 瀏覽器開發人員事務部
第一章 簡介
瀏覽器是使用最廣的軟體之一。在這篇博文中,我將介紹瀏覽器的幕後工作原理。通過閱讀本文,我們將會了解,從您在位址列輸入 google.com ,直到您在瀏覽器螢幕上看到 Google 首頁的整個過程中都發生了些什麼。
1.1 討論的瀏覽器
目前使用的主流瀏覽器有五個:Internet Explorer、Firefox、Safari、Chrome和 Opera瀏覽器。本文主要以開源瀏覽器為主進行分析,即 Firefox、Chrome和 Safari(部分開源)。根據 StatCounter 瀏覽器統計資料,目前(2016年 2 月)Firefox(14.67%)、Safari(9.46%)和 Chrome(55.33%) 瀏覽器的總市場佔有率將近 80%(這個數字在2011年8月的時候,才將近60%)。由此可見,如今開源瀏覽器在瀏覽器市場中佔據絕大多數的市場份額。
1.2 瀏覽器的主要功能
瀏覽器的主要功能就是向伺服器發出請求,在瀏覽器視窗中展示您想要訪問的網路資源。這裡所說的資源一般是指 HTML 文件,也可以是 PDF、圖片或其他的型別。資源的位置由使用者使用 URI(統一資源標示符)指定。
瀏覽器解釋並顯示HTML檔案的方式是在 HTML 和 CSS 規範中指定的。這些規範由網路標準化組織 W3C(全球資訊網聯盟)進行維護。多年以來,各瀏覽器都沒有完全遵從這些規範,同時還在開發自己獨有的擴充套件程式,這給網路開發人員帶來了嚴重的相容性問題。如今,大多數的瀏覽器都開始儘量遵從規範。
瀏覽器的使用者介面有很多彼此相同的元素,其中包括:用來輸入 URI 的位址列;前進和後退按鈕;書籤設定選項;用於重新整理和停止載入當前文件的重新整理和停止按鈕;用於返回主頁的主頁按鈕。
奇怪的是,瀏覽器的使用者介面並沒有任何正式的規範,這是多年來的最佳實踐自然發展以及彼此模仿的結果。HTML5 也沒有定義瀏覽器必須具有的使用者介面元素,但列出了一些通用的元素,例如位址列、狀態列和工具欄等。當然,各瀏覽器也可以有自己獨特的功能,比如 Firefox 的下載管理器。
1.3 瀏覽器的高層結構(High Level Structure)
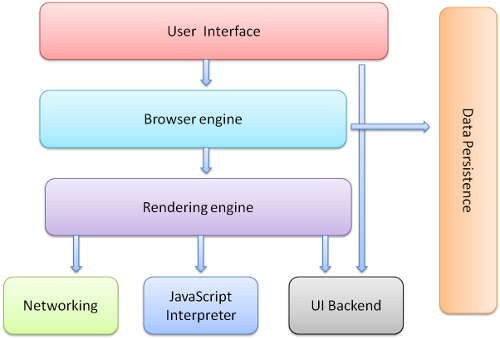
瀏覽器的主要元件包括:
- 使用者介面 - 包括位址列、前進/後退按鈕、書籤選單等。除了瀏覽器主視窗顯示的你請求的頁面外,其他顯示的各個部分都屬於使用者介面。
- 瀏覽器引擎 - 在使用者介面和渲染引擎之間傳送指令。
- 渲染引擎 - 負責顯示請求的內容。如果請求的內容是 HTML,它就負責解析 HTML 和 CSS 內容,並將解析後的內容顯示在螢幕上。
- 網路 - 用於網路呼叫,比如 HTTP 請求。其介面與平臺無關,併為所有平臺提供底層實現。
- 使用者介面後端 - 用於繪製基本的視窗小部件,比如組合框和視窗。其公開了與平臺無關的通用介面,而在底層使用作業系統的使用者介面方法。
- JavaScript 直譯器。用於解析和執行 JavaScript 程式碼,比如chrome的javascript直譯器是V8。
-
資料儲存。這是持久層。瀏覽器需要在硬碟上儲存各種資料,例如 Cookie。新的 HTML 規範 (HTML5)定義了“網路資料庫”,這是一個完整(但是輕便)的瀏覽器內資料庫。
圖1.1:瀏覽器的主要元件。 值得注意的是,不同於大多數瀏覽器,Chrome 瀏覽器為每個標籤頁(Tab)都分配了各自的渲染引擎例項,每個標籤頁都是一個獨立的程序(即每個標籤頁面都在獨立的“沙箱”內執行,在提高安全性的同時,一個標籤頁面的崩潰也不會導致其他標籤頁面被關閉)。
對於構成瀏覽器的這些元件,後面會逐一詳細討論。
第二章 渲染引擎(The rendering engine)
渲染引擎的職責就是渲染,即在瀏覽器視窗中顯示所請求的內容。這是每一個瀏覽器的核心部分,所以渲染引擎也稱為瀏覽器核心。
預設情況下,渲染引擎可顯示 HTML 和 XML 文件及圖片。通過外掛(或瀏覽器擴充套件程式),還瀏覽器渲染引擎也可以顯示其它型別的內容。例如,使用 PDF 檢視器外掛就能顯示 PDF 文件。在本章中,我們將集中介紹其主要用途:顯示應用了CSS的 HTML 內容和圖片。
2.1 渲染引擎簡介
本文所討論的瀏覽器(Firefox、Chrome和Safari)是基於兩種渲染引擎構建的。Firefox 使用的是 Gecko,這是 Mozilla 公司“自制”的渲染引擎。而 Safari 和 Chrome(28版本以前)瀏覽器使用的都是 Webkit。
2013年7月10日釋出的Chrome 28 版本中,Chrome瀏覽器開始正式使用Blink核心。所以,Webkit已經成為了Chrome瀏覽器的前核心。
Webkit 是一種開放原始碼渲染引擎,起初用於 Linux 平臺,隨後由 Apple 公司進行修改,從而支援蘋果機和 Windows。有關詳情,請參閱 webkit.org。
2.2 主流程(The main flow)
渲染引擎一開始會從網路層獲取請求文件的內容,通常以8K分塊的方式完成。
獲取了文件內容之後,渲染引擎開始正式工作,其基本流程:

渲染引擎解析HTML文件,並將文件中的標籤轉化為dom節點樹,即”內容樹”。同時,它也會解析外部CSS檔案以及style標籤中的樣式資料。這些樣式資訊連同HTML中的”可見內容”一道,被用於構建另一棵樹——”渲染樹(Render樹)”。
渲染樹由一些帶有視覺屬性(如顏色、大小等)的矩形組成,這些矩形將按照正確的順序顯示在頻幕上。
渲染樹構建完畢之後,將會進入”佈局”處理階段,即為每一個節點分配一個螢幕座標。再下一步就是繪製(painting),即遍歷render樹,並使用UI後端層繪製每個節點。
值得注意的是,這個過程是逐步完成的,為了更好的使用者體驗,渲染引擎將會盡可能早的將內容呈現到螢幕上,並不會等到所有的html都解析完成之後再去構建和佈局render樹。它是解析完一部分內容就顯示一部分內容,同時,可能還在通過網路下載其餘內容。
主流程示例
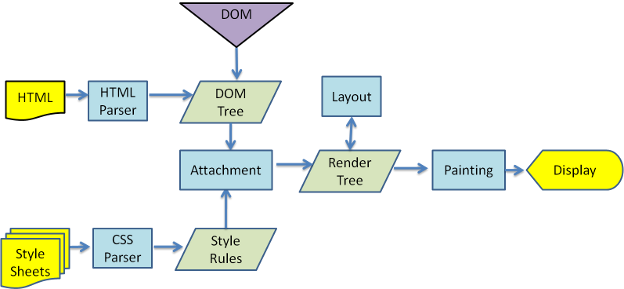
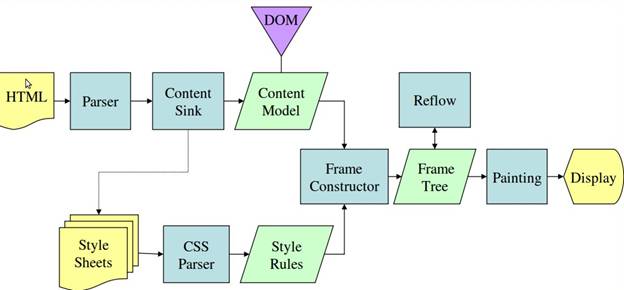
從圖2.2 和圖2.3可以看出,雖然 Webkit 和 Gecko 使用的術語略有不同,但整體流程還是基本相同的。
- Gecko將視覺格式化元素組成的樹稱為”框架樹”(frame)。每個元素都是一個框架。Webkit使用的術語是”渲染樹”(render),它由”渲染物件”組成。
- 對於元素的放置,Webkit 使用的術語是”佈局”(layout),而 Gecko 稱之為”重排”(reflow)。
- Webkit稱利用dom節點及樣式資訊去構建render樹的過程為attachment,Gecko在html和dom樹之間附加了一層,這層稱為內容接收器,相當製造dom元素的工廠。
我們會逐一論述流程中的每一部分:
第三章 解析與DOM樹構建(Parsing and DOM tree construction)
3.1 解析(Parsing-general)
既然解析是渲染引擎中一個非常重要的過程,我們將稍微深入的研究它。首先明白什麼叫做解析(parsing)。
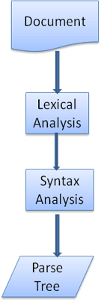
解析一個文件就是指將這個文件翻譯成一個可以讓程式碼理解和使用的有意義的結構。得到的結構通常是一個代表了該文件結構的節點樹,通常稱之為解析樹或語法樹。
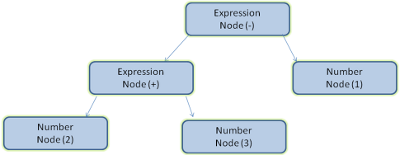
例如, 解析“2+3-1”這個表示式,可能返回這樣一棵樹。
1.文法(Grammars)
解析是以文件所遵循的語法規則(編寫文件所用的語言或格式)為基礎的。所有可以解析的格式都必須對應確定的語法(由詞彙和語法規則構成)。這稱為與上下文無關的文法。人類語言並不屬於這樣的語言,因此無法用常規的解析技術進行解析。
2.解析器-詞法分析器(Parser-Lexer combination)
解析一般可分為兩個子過程:語法分析和詞法分析。
語法分析指對語言應用語法規則。
詞法分析就是將輸入分解為符號,符號是語言的詞彙表——基本有效單元的集合。對於人類語言來說,它相當於我們字典中出現的所有單詞。
解析工作一般由兩個元件共同完成:
1)詞法分析器(有時也稱為標記生成器),負責將輸入內容分解成一個個有效標記。詞法分析器知道如何將無關的字元(比如空格和換行符)分離出來。;
2)解析器負責根據語言的語法規則分析文件的結構,從而構建解析樹。
解析是一個迭代的過程。通常,解析器會向詞法分析器請求一個新標記,並嘗試將其與某條語法規則進行匹配。如果發現了匹配規則,解析器會將一個對應於該標記的節點新增到解析樹中,然後繼續請求下一個標記。
如果沒有規則與該標記匹配,解析器就會將標記儲存到內部,並繼續請求下一個標記,直至找到可與所有內部儲存的標記匹配的規則。
如果沒有規則(即沒有找到相應的語法規則),解析器就會引發一個異常。這意味著文件無效,包含語法錯誤。
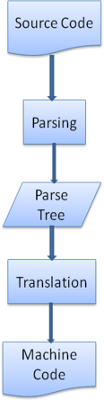
3.轉換(Translation)
很多時候,解析樹還不是最終結果。解析通常是在轉換過程中使用的,而轉換是指將輸入文件轉換成另一種格式。編譯就是一個例子。編譯器可將原始碼編譯成機器程式碼,具體過程是首先將原始碼解析成解析樹,然後將解析樹翻譯成機器程式碼文件。
4.解析示例(Parsing example)
在圖3.1中,我們通過一個數學表示式建立了解析樹。現在,讓我們試著定義一個簡單的數學語言,用來演示解析的過程。
詞彙表:我們用的語言可包含整數、加號和減號。
語法規則:1)構成語言的語法單位是表示式、項和運算子。2)該語言可以包括多個表示式。3)一個表示式定義為兩個項通過一個操作符連線。4)運算子可以是加號或減號。5)項可以是一個整數或一個表示式。
現在來分析一下”2+3-1”這個輸入。
匹配語法規則的第一個子串是2,而根據第5條語法規則,這是一個項。匹配語法規則的第二個子串是 2 + 3,而根據第 3 條規則(一個項接一個運算子,然後再接一個項),這是一個表示式。下一個匹配項已經到了輸入的結束。2 + 3 - 1 是一個表示式,因為我們已經知道 2 + 3 是一個項,這樣就符合“一個項接一個運算子,然後再接一個項”的規則。2 + +不與任何規則匹配,因此是無效的輸入。
5.詞彙和語法的正式定義
-
1)詞彙通常用正則表示式表示。
例如,我們的示例語言可以定義如下:
- 1
- 2
- 3
正如您所看到的,這裡用正則表示式給出了整數的定義。
-
2)語法通常使用一種稱為 BNF 的格式來定義。
我們的示例語言可以定義如下:
- 1
- 2
- 3
之前我們說過,如果語言的語法是與上下文無關的語法,就可以由常規解析器進行解析。
與上下文無關的語法的直觀定義就是可以完全用BNF格式表達的語法。有關正式定義,請參閱關於與上下文無關的語法的維基百科文章。
6.解析器型別
有兩種基本型別的解析器:自上而下解析器和自下而上解析器。直觀地來說,自上而下的解析器從語法的高層結構出發,嘗試從中找到匹配的結構。而自下而上的解析器從低層規則出發,將輸入內容逐步轉化為語法規則,直至滿足高層規則。
讓我們來看看這兩種解析器會如何解析我們的示例:
自頂向下解析器從最高層規則開始——它先識別出”2+3”,將其視為一個表示式,然後識別出”2+3-1”為一個表示式(識別表示式的過程中匹配了其他規則,但起點是最高層規則)。
自下而上的解析器將掃描輸入內容,找到匹配的規則後,將匹配的輸入內容替換成規則。如此繼續替換,直到輸入內容的結尾。部分匹配的表示式儲存在解析器的堆疊中。
| 堆疊(Stack) | 輸入(Input) |
|---|---|
| 2+3-1 | |
| 項 | +3-1 |
| 項運算 | 3-1 |
| 表示式 | -1 |
| 表示式運算子 | 1 |
| 表示式 | - |
這種自下而上的解析器稱為移位歸約解析器,因為輸入在向右移位(設想有一個指標從輸入內容的開頭移動到結尾),並逐漸簡化語法規則。
7.自動生成解析器(Generating parsers automatically)
解析器生成器這個工具可以自動生成解析器,只需要指定語言的文法———詞彙表及語法規則,它就可以生成一個解析器。建立一個解析器需要對解析有深入的理解,而且手動的建立一個有較好效能的解析器並不容易,所以解析生成器很有用。
Webkit使用兩個知名的解析生成器——用於建立語法分析器的Flex及建立解析器的Bison(你可能接觸過Lex和Yacc)。Flex的輸入是一個包含了符號定義的正則表示式,Bison的輸入是用BNF格式表示的語法規則。
3.2 HTML 解析器(HTML Parser)
HTML 解析器的任務是將 HTML 標記解析成解析樹。
1.HTML 語法定義(The HTML grammar definition)
W3C組織制定規範定義了HTML的詞彙表和語法。
2.非與上下文無關的語法(Not a context free grammar)
正如在解析簡介中提到的,上下文無關文法的語法可以用類似BNF的格式來定義。
很遺憾,所有的常規解析器都不適用於 HTML(我並不是開玩笑,它們可以用於解析 CSS 和 JavaScript)。HTML 並不能用解析器所需的與上下文無關的語法來定義。
Html有一個正式的格式定義:DTD(Document Type Definition,文件型別定義),但它並不是上下文無關的語法。
這初看起來很奇怪:HTML 和 XML 非常相似。有很多 XML 解析器可以使用。HTML 存在一個 XML 變體 (XHTML),那麼有什麼大的區別呢?區別在於 HTML 的處理更為“寬容”,它允許您省略某些隱式新增的標記,有時還能省略一些起始或者結束標記等等。和 XML 嚴格的語法不同,HTML 整體來看是一種“軟性”的語法。
顯然,這種看上去細微的差別實際上卻帶來了巨大的影響。一方面,這是 HTML 如此流行的原因:它能包容您的錯誤,簡化網路開發。另一方面,這使得它很難編寫正式的語法。概括地說,HTML 無法很容易地通過常規解析器解析(因為它的語法不是與上下文無關的語法),也無法通過 XML 解析器來解析。
3.HTML DTD
HTML的定義採用了DTD格式。此格式適用於定義SGML族的語言。它包括所有允許使用的元素及其屬性和層次結構的定義。如上文所述,HTML DTD無法構成與上下文無關的語法。
DTD存在一些變體。嚴格模式完全遵守HTML規範,而其他模式可支援以前的瀏覽器所使用的標記。這樣做的目的是確保向下相容一些早期版本的內容。最新的嚴格模式DTD可以在這裡找到:www.w3.org/TR/html4/strict.dtd
4.DOM
解析器的輸出(即”解析樹”)是由DOM元素及屬性節點組成的。DOM是文件物件模型(Document Object Model) 的縮寫。它是HTML文件的物件表示,同時也是外部內容(例如 JavaScript)與HTML元素之間的介面。
解析樹的根節點是”Document”物件。DOM與標記之間幾乎是一一對應的關係。比如下面這段標記:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可翻譯成如下的 DOM 樹:
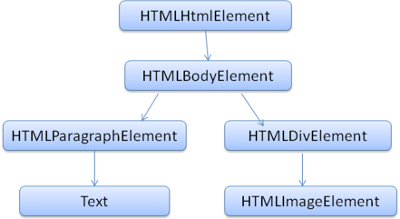
和HTML一樣,DOM也是由W3C組織制定的。請參見www.w3.org/DOM/DOMTR。這是關於文件操作的通用規範。其中一個特定模組描述針對HTML的元素。HTML的定義可以在這裡找到:www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html。
這裡所說的DOM節點樹,指的是那些實現了DOM介面的元素組成的樹。
5.解析演算法(The parsing algorithm)
我們在之前章節已經說過,HTML無法用常規的自上而下或自下而上的解析器進行解析。原因在於:
語言本身的寬容特性;
瀏覽器對一些常見的非法html有容錯機制;
解析過程需要不斷地反覆。源內容在解析過程中通常不會改變,但是在HTML中,指令碼標記如果包含 “document.write”,就會新增額外的標記,這樣解析過程實際上就更改了輸入內容。
由於不能使用常規的解析技術,瀏覽器為html定製了專屬的解析器。
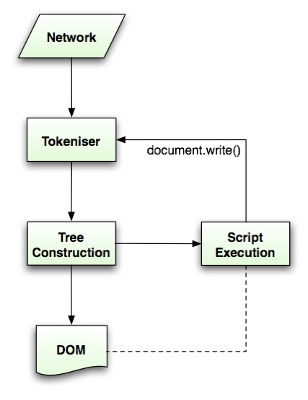
HTML5規範詳細地描述瞭解析演算法。此演算法由兩個階段組成:符號化及構建樹。
符號化是詞法分析的過程,將輸入內容解析成多個標記,HTML標記包括起始標記、結束標記、屬性名稱和屬性值。標記生成器識別標記,傳遞給樹構造器,然後讀取下一個字元以識別下一個標記,如此反覆直到輸入的結束。
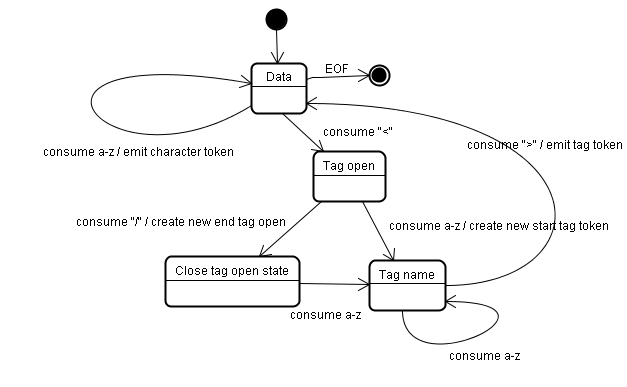
6.符號識別演算法(The tokenization algorithm)
該演算法的輸出結果是HTML標記。該演算法使用狀態機來表示。每一個狀態接收來自輸入資訊流的一個或多個字元,並根據這些字元更新下一個狀態。當前的標記化狀態和樹結構狀態會影響進入下一狀態的決定。這意味著,即使接收的字元相同,對於下一個正確的狀態也會產生不同的結果,具體取決於當前的狀態。該演算法相當複雜,無法在此詳述,所以我們通過一個簡單的示例來幫助大家理解其原理。
基本示例 - 將下面的 HTML 程式碼標記化:
- 1
- 2
- 3
- 4
- 5
初始狀態是資料狀態。遇到字元 < 時,狀態更改為“標記開啟狀態”。接收一個 a-z字元會建立“起始標記”,狀態更改為“標記名稱狀態”。這個狀態會一直保持到接收> 字元。在此期間接收的每個字元都會附加到新的標記名稱上。在本例中,我們建立的標記是
html 標記。
遇到 > 標記時,會發送當前的標記,狀態改回“資料狀態”。<body> 標記也會進行同樣的處理。目前
html 和 body 標記均已發出。現在我們回到“資料狀態”。接收到 Hello world 中的 H 字元時,將建立併發送字元標記,直到接收 </body> 中的<。我們將為
Hello world 中的每個字元都發送一個字元標記。
現在我們回到“標記開啟狀態”。接收下一個輸入字元 / 時,會建立 end tag token 並改為“標記名稱狀態”。我們會再次保持這個狀態,直到接收 >。然後將傳送新的標記,並回到“資料狀態”。</html> 輸入也會進行同樣的處理。
7.樹構建演算法
在建立解析器的同時,也會建立 Document 物件。在樹構建階段,以 Document 為根節點的 DOM 樹也會不斷進行修改,向其中新增各種元素。標記生成器傳送的每個節點都會由樹構建器進行處理。規範中定義了每個標記所對應的 DOM 元素,這些元素會在接收到相應的標記時建立。這些元素不僅會新增到 DOM 樹中,還會新增到開放元素的堆疊中。此堆疊用於糾正巢狀錯誤和處理未關閉的標記。其演算法也可以用狀態機來描述。這些狀態稱為“插入模式”。
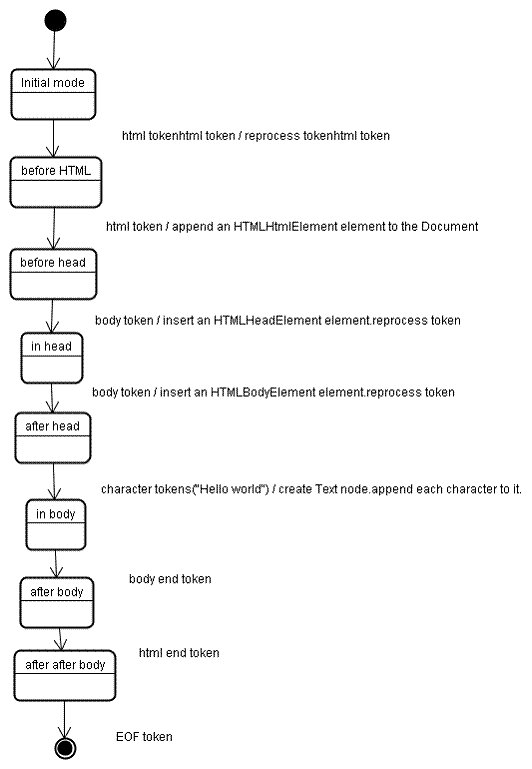
讓我們來看看示例輸入的樹構建過程:
- 1
- 2
- 3
- 4
- 5
樹構建階段的輸入是一個來自標記化階段的標記序列。第一個模式是“initial mode”。接收 HTML 標記後轉為“before html”模式,並在這個模式下重新處理此標記。這樣會建立一個 HTMLHtmlElement 元素,並將其附加到 Document 根物件上。
然後狀態將改為“before head”。此時我們接收“body”標記。即使我們的示例中沒有“head”標記,系統也會隱式建立一個 HTMLHeadElement,並將其新增到樹中。
現在我們進入了“in head”模式,然後轉入“after head”模式。系統對 body 標記進行重新處理,建立並插入 HTMLBodyElement,同時模式轉變為“body”。
現在,接收由“Hello world”字串生成的一系列字元標記。接收第一個字元時會建立並插入“Text”節點,而其他字元也將附加到該節點。
接收 body 結束標記會觸發“after body”模式。現在我們將接收 HTML 結束標記,然後進入“after after body”模式。接收到檔案結束標記後,解析過程就此結束。
8.解析結束後的操作
在此階段,瀏覽器會將文件標註為互動狀態,並開始解析那些處於“deferred”模式的指令碼,也就是那些應在文件解析完成後才執行的指令碼。然後,文件狀態將設定為“完成”,一個“載入”事件將隨之觸發。您可以在 HTML5 規範中檢視標記化和樹構建的完整演算法
9.瀏覽器的容錯機制
您在瀏覽 HTML 網頁時從來不會看到“語法無效”的錯誤。這是因為瀏覽器會糾正任何無效內容,然後繼續工作。
以下面的 HTML 程式碼為例:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在這裡,我已經違反了很多語法規則(“mytag”不是標準的標記,“p”和“div”元素之間的巢狀有誤等等),但是瀏覽器仍然會正確地顯示這些內容,並且毫無怨言。因為有大量的解析器程式碼會糾正 HTML 網頁作者的錯誤。
不同瀏覽器的錯誤處理機制相當一致,但令人稱奇的是,這種機制並不是 HTML 當前規範的一部分。和書籤管理以及前進/後退按鈕一樣,它也是瀏覽器在多年發展中的產物。很多網站都普遍存在著一些已知的無效 HTML 結構,每一種瀏覽器都會嘗試通過和其他瀏覽器一樣的方式來修復這些無效結構。
HTML5 規範定義了一部分這樣的要求。Webkit 在 HTML 解析器類的開頭註釋中對此做了很好的概括。
解析器對標記化輸入內容進行解析,以構建文件樹。如果文件的格式正確,就直接進行解析。
遺憾的是,我們不得不處理很多格式錯誤的 HTML 文件,所以解析器必須具備一定的容錯性。
我們至少要能夠處理以下錯誤情況:
明顯不能在某些外部標記中新增的元素。在此情況下,我們應該關閉所有標記,直到出現禁止新增的元素,然後再加入該元素。
我們不能直接新增的元素。這很可能是網頁作者忘記添加了其中的一些標記(或者其中的標記是可選的)。這些標籤可能包括:HTML HEAD BODY TBODY TR TD LI(還有遺漏的嗎?)。
向 inline 元素內新增 block 元素。關閉所有 inline 元素,直到出現下一個較高階的 block 元素。
如果這樣仍然無效,可關閉所有元素,直到可以新增元素為止,或者忽略該標記。
讓我們看一些 Webkit 容錯的示例:
使用了 </br> 而不是 <br>
有些網站使用了 </br> 而不是