
MySQL中針對大資料量常用技術:查詢優化,資料轉移
如今隨著網際網路的發展,資料的量級也是撐指數的增長,從GB到TB到PB。對資料的各種操作也是愈加的困難,傳統的關係性資料庫已經無法滿足快速查詢與插入資料的需求。這個時候NoSQL的出現暫時解決了這一危機。它通過降低資料的安全性,減少對事務的支援,減少對複雜查詢的支援,來獲取效能上的提升。但是,在有些場合NoSQL一些折衷是無法滿足使用場景的,就比如有些使用場景是絕對要有事務與安全指標的。這個時候NoSQL肯定是無法滿足的,所以還是需要使用關係性資料庫。
雖然關係型資料庫在海量資料中遜色於NoSQL資料庫,但是如果你操作正確,它的效能還是會滿足你的需求的。針對資料的不同操作,其優化方向也是不盡相同。對於資料移植,查詢和插入等操作,可以從不同的方向去考慮。而在優化的時候還需要考慮其他相關操作是否會產生影響。就比如你可以通過建立索引提高查詢效能,但是這會導致插入資料的時候因為要建立更新索引導致插入效能降低,你是否可以接受這一降低那。所以,對資料庫的優化是要考慮多個方向,尋找一個折衷的最佳方案。
一:查詢優化
1:建立索引。
最簡單也是最常用的優化就是查詢。因為對於CRUD操作,read操作是佔據了絕大部分的比例,所以read的效能基本上決定了應用的效能。對於查詢效能最常用的就是建立索引。經過測試,2000萬條記錄,每條記錄200位元組兩列varchar型別的。當不使用索引的時候查詢一條記錄需要一分鐘,而當建立了索引的時候查詢時間可以忽略。但是,當你在已有資料上新增索引的時候,則需要耗費非常大的時間。我插入2000萬條記錄之後,再建立索引大約話費了幾十分鐘的樣子。
建立索引的弊端和場合。雖然建立索引可以很大程度上優化查詢的速度,但是弊端也是很明顯的。一個是在插入資料的時候,建立索引也需要消耗部分的時間,這就使得插入效能在一定程度上降低;另一個很明顯的是資料檔案變的更大。在列上建立索引的時候,每條索引的長度是和你建立列的時候制定的長度相同的。比如你建立varchar(100),當你在該列上建立索引,那麼索引的長度則是102位元組,因為長度超過64位元組則會額外增加2位元組記錄索引的長度。
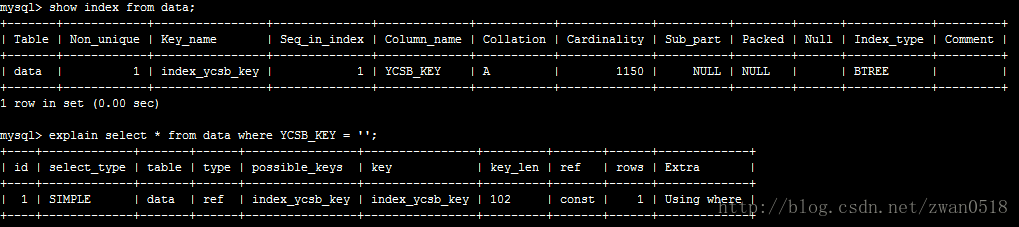
從上圖可以看到我在YCSB_KEY這一列(長度100)上建立了一個名字為index_ycsb_key的索引,每條索引長度都為102,想象一下當資料變的巨大無比的時候,索引的大小也是不可以小覷的。而且從這也可以看出,索引的長度和列型別的長度還不同,比如varchar它是變長的字元型別(請看MySQL資料型別分析),實際儲存長度是是實際字元的大小,但是索引卻是你宣告的長度的大小。你建立列的時候宣告100位元組,那麼索引長度就是這個位元組再加上2,它不管你實際儲存是多大。
除了建立索引需要消耗時間,索引檔案體積會變的越來越大之外,建立索引也需要看的你儲存資料的特徵。當你儲存資料很大一部分都是重複記錄,那這個時候建立索引是百害而無一利。請先檢視
2:快取的配置。
在MySQL中有多種多樣的快取,有的快取負責快取查詢語句,也有的負責快取查詢資料。這些快取內容客戶端無法操作,是由server端來維護的。它會隨著你查詢與修改等相應不同操作進行不斷更新。通過其配置檔案我們可以看到在MySQL中的快取:
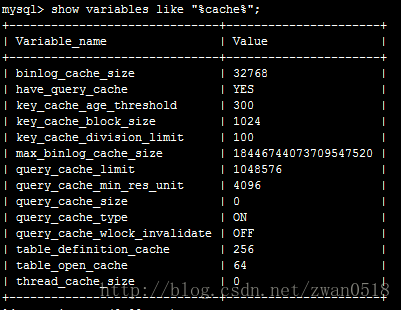
在這裡主要分析query cache,它是主要用來快取查詢資料。當你想使用該cache,必須把query_cache_size大小設定為非0。當設定大小為非0的時候,server會就會快取每次查詢返回的結果,到下次相同查詢server就直接從快取獲取資料,而不是再執行查詢。能快取的資料量就和你的size大小設定有關,所以當你設定的足夠大,資料可以完全快取到記憶體,速度就會非常之快。
但是,query cache也有它的弊端。當你對資料表做任何的更新操作(update/insert/delete)等操作,server為了保證快取與資料庫的一致性,會強制重新整理快取資料,導致快取資料全部失效。所以,當一個表格的更新資料表操作非常多的話,query cache是不會起到查詢提升的效能,還會影響其他操作的效能。
3:slow_query_log分析。
其實對於查詢效能提升,最重要也是最根本的手段也是slow_query的設定。
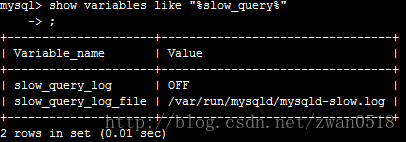
當你設定slow_query_log為on的時候,server端會對每次的查詢進行記錄,當超過你設定的慢查詢時間(long_query_time)的時候就把該條查詢記錄到日誌。而你對效能進行優化的時候,就可以分析慢查詢日誌,對慢查詢的查詢語句進行有目的的優化。可以通過建立各種索引,可以通過分表等操作。那為什麼要分庫分表那,當不分庫分表的時候那個地方是限制性能的地方啊。下面我們就簡單介紹。
4:分庫分表
分庫分表應該算是查詢優化的殺手鐗了。上述各種措施在資料量達到一定等級之後,能起到優化的作用已經不明顯了。這個時候就必須對資料量進行分流。分流一般有分庫與分表兩種措施。而分表又有垂直切分與水平切分兩種方式。下面我們就針對每一種方式簡單介紹。
對於mysql,其資料檔案是以檔案形式儲存在磁碟上的。當一個數據檔案過大的時候,作業系統對大檔案的操作就會比較麻煩與耗時,而且有的作業系統就不支援大檔案,所以這個時候就必須分表了。另外對於mysql常用的儲存引擎是Innodb,它的底層資料結構是B+樹。當其資料檔案過大的時候,B+樹就會從層次和節點上比較多,當查詢一個節點的時候可能會查詢很多層次,而這必定會導致多次IO操作進行裝載進記憶體,肯定會耗時的。除此之外還有Innodb對於B+樹的鎖機制。對每個節點進行加鎖,那麼當更改表結構的時候,這時候就會樹進行加鎖,當表文件大的時候,這可以認為是不可實現的。
所以綜上我們就必須進行分表與分庫的操作。
5:子查詢優化
在查詢中經常會用到子查詢,在子查詢的時候一般使用in或者exist關鍵詞。針對in和exist在查詢的時候當資料量大到一定程度以後,查詢執行時間就差別比較大。但是,為了避免此類情況出現,最好的方式是使用join查詢。因為在絕大多數情況下,伺服器對join的查詢優化要遠遠高於子查詢優化。在比較高的版本5.6,mysql查詢會自動把in查詢優化成joint查詢,就不會出現子查詢比較慢的問題。有時候也可以採用distinct關鍵詞來限制子查詢的數量,但是需要注意的是distinct很多時候會轉化為group by,這個時候就會出現一個臨時表,就會出現copy資料到臨時表的時延。 更多的子查詢優化請點選。二:資料轉移
當資料量達到一定等級之後,那麼移庫將是一個非常慎重又危險的工作。在移庫中保證前後資料的一致性,各種突發情況的處理,移庫過程中資料的變遷,每一個都是一個非常困難的問題。
2.1:插入資料
當進行資料遷移的時候,肯定會存在大資料的重新匯入,你可以選擇直接load檔案,有的時候可能就需要程式碼插入了。這個時候就需要對插入語句進行一定的優化了。這個時候可以使用INSERT DELAYED語句,該語句是當你發出插入請求的時候,不是馬上就插入到資料庫而是放在快取裡面,等待時機成熟之後再進行插入。待補充。。。