
Zookeeper master選舉
Master/slave 主從,單點故障處理
有一個向外提供的服務,服務必須7*24小時提供服務,不能有單點故障。所以採用叢集的方式,採用master、slave的結構。一臺主機多臺備機。主機向外提供服務,備機負責監聽主機的狀態,一旦主機宕機,備機要迅速接代主機繼續向外提供服務。從備機選擇一臺作為主機,就是master選舉。
主從有多重方式,或者有成熟的產品,但是如果我們自己實現一個主從,該如何下手?像mysql-cluster叢集版本。等等…很多產品內部的實現。現在我們來描述一個Zookeeper生成主從單點故障後切換服務的應用。
原理解析
右邊三臺主機會嘗試建立master節點,誰建立成功了,就是master,向外提供。其他兩臺就是slave。
所有slave必須關注master的刪除事件(臨時節點,如果伺服器宕機了,Zookeeper會自動把master節點刪除)。如果master宕機了,會進行新一輪的master選舉。本次我們主要關注master選舉,服務註冊、發現先不討論。
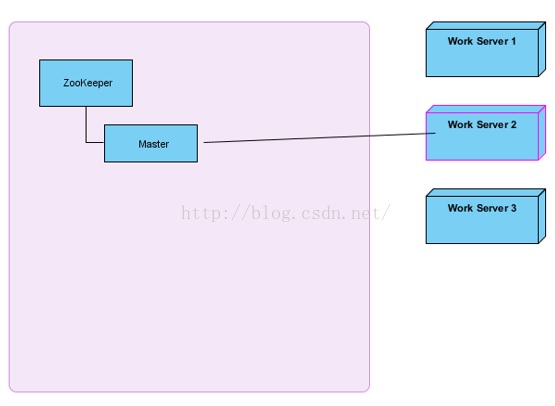
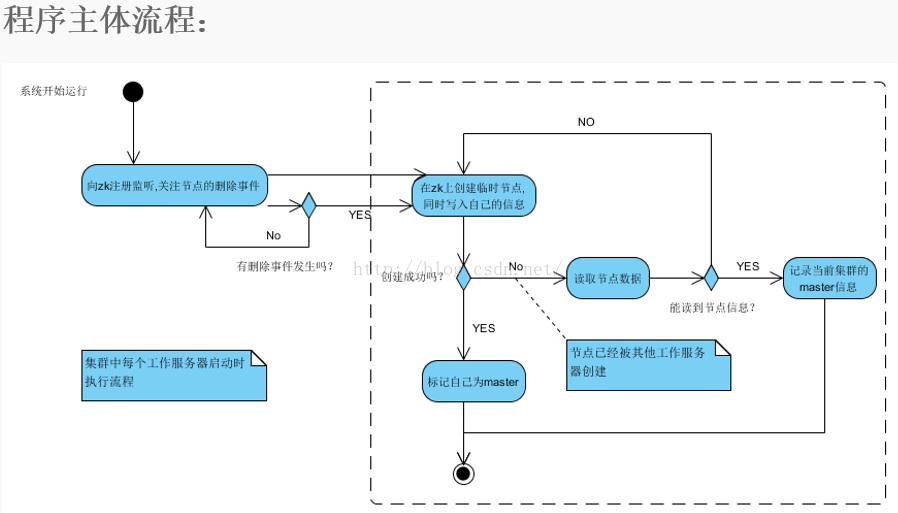
其實蠻簡單的,zookeeper支援臨時資料的建立和持久節點的建立,首先我們多個服務節點啟動的時候去想zookeeper建立臨時資料,建立成功,則意味著這臺機器是master,之後的其他服務節點再去建立同樣的臨時資料時,zookeeper是不支援建立的。就會建立失敗,這時去監聽zookeeper臨時資料的刪除。(臨時資料的刪除發生在master 與 zookeeper session失效的時候)在臨時資料被刪除的時候,我們的其他服務節點,就去搶著再次建立臨時資料,建立的成功的服務節點從salve切換成master。其他salve又失敗,然後繼續監聽這個臨時資料。這就是註冊到zookeeper做master/salve 服務的支援。非常簡單且高效。
臨時資料:zookeeper 的 path。
不貼程式碼了,主從服務的最核心的實現,當然服務的提供還需要做業務的處理,如:
apache lucene 服務的索引服務,當master的某個埠的介面服務崩掉時候,我們的slave搶到master角色之後,啟動新的埠介面服務。這是一個最簡單的應用。真實的場景要複雜得多。程式碼下一天在貼出來,玩的就是先理論後實踐.