
基於ZooKeeper的分散式Session實現
1.認識ZooKeeper
ZooKeeper——“動物園管理員”。動物園裡當然有好多的動物,遊客可以根據動物園提供的嚮導圖到不同的場館觀賞各種型別的動物,而不是像走在原始叢林裡,心驚膽顫的被動物所觀賞。為了讓各種不同的動物呆在它們應該呆的地方,而不是相互串門,或是相互廝殺,就需要動物園管理員按照動物的各種習性加以分類和管理,這樣我們才能更加放心安全的觀賞動物。回到我們企業級應用系統中,隨著資訊化水平的不斷提高,我們的企業級系統變得越來越龐大臃腫,效能急劇下降,客戶抱怨頻頻。拆分系統是目前我們可選擇的解決系統可伸縮性和效能問題的唯一行之有效的方法。但是拆分系統同時也帶來了系統的複雜性——各子系統不是孤立存在的,它們彼此之間需要協作和互動,這就是我們常說的分散式系統。各個子系統就好比動物園裡的動物,為了使各個子系統能正常為使用者提供統一的服務,必須需要一種機制來進行協調——這就是ZooKeeper
關於ZooKeeper更正式的介紹——ZooKeeper是一個為分散式應用程式提供高效能協調服務的工具集合。它可以應用在一些需要提供統一協調服務的case中,例如命名、配置管理、同步和組服務等。而在我們的case中,它被作為一個協調分散式環境中各子系統之間共享狀態資料的基礎設施。
2.ZooKeeper之特性
ZooKeeper本質上是一個分散式的小檔案儲存系統。原本是Apache
Hadoop的一個元件,現在被拆分為一個Hadoop的獨立子專案,在HBase(Hadoop的另外一個被拆分出來的子專案,用於分散式環境下的超大資料量的DBMS)中也用到了ZooKeeper
1)簡單
ZooKeeper核心是一個精簡的檔案系統,它提供了一些簡單的檔案操作以及附加的功能,例如排序和通知。
2)易表達
ZooKeeper的資料結構原型是一棵znode樹(類似Linux的檔案系統),並且它們是一些已經被構建好的塊,可以用來構建大型的協作資料結構和協議。
3)高可用性
ZooKeeper可以執行在一組伺服器上,同時它們被設計成高可用性,為你的應用程式避免單點故障。
4)鬆耦合互動
ZooKeeper提供的Watcher機制使得各客戶端與伺服器的互動變得鬆耦合,每個客戶端無需知曉其他客戶端的存在,就可以和其他客戶端進行資料互動。
5)豐富的API
ZooKeeper為開發人員提供了一套豐富的API,減輕了開發人員編寫通用協議的負擔。
這篇文章是關於如何在ZooKeeper上建立分散式Session系統,所以關於ZooKeeper的安裝、使用、管理等主題不在本文的討論範圍內,如果想了解ZooKeeper更加詳細的情況,請看另外一篇文章《ZooKeeper實戰》。
3.為什麼使用ZooKeeper
目前有關於分散式Session的實現基本上都是基於memcached。memcached本質上是一個記憶體快取系統。雖然memcached也可以是分散式叢集環境的,但是對於一份資料來說,它總是儲存在某一臺memcached伺服器上。如果發生網路故障或是伺服器當機,則儲存在這臺伺服器上的所有資料都將不可訪問。由於資料是儲存在記憶體中的,重啟伺服器,將導致資料全部丟失。當然你可以自己實現一套機制,用來在分散式memcached之間進行資料的同步和持久化,但是實現這套機制談何容易!
由上述ZooKeeper的特性可知,ZooKeeper是一個分散式小檔案系統,並且被設計為高可用性。通過選舉演算法和叢集複製可以避免單點故障,由於是檔案系統,所以即使所有的ZooKeeper節點全部掛掉,資料也不會丟失,重啟伺服器之後,資料即可恢復。另外ZooKeeper的節點更新是原子的,也就是說更新不是成功就是失敗。通過版本號,ZooKeeper實現了更新的樂觀鎖,當版本號不相符時,則表示待更新的節點已經被其他客戶端提前更新了,而當前的整個更新操作將全部失敗。當然所有的一切ZooKeeper已經為開發者提供了保障,我們需要做的只是呼叫API。
有人會懷疑ZooKeeper的執行能力,在ZooKeeper誕生的地方——Yahoo!給出了一組資料將打消你的懷疑。它的吞吐量標準已經達到大約每秒10000基於寫操作的工作量。對於讀操作的工作量來說,它的吞吐量標準還要高几倍。
4.實現分散式Session所面臨的挑戰
實現分散式session最大的挑戰莫過於如何實現session在分散式系統之間的共享。在分散式環境下,每個子系統都是跨網路的獨立JVM,在這些JVM之間實現共享資料的方式無非就是TCP/IP通訊。無論是memcached,還是ZooKeeper,底層都是基於TCP/IP的。所以,我認為使用何種工具實現分散式Session都是可行的,沒有那種實現優於另外一種實現,在不同的應用場景,各有優缺點。世間萬物,無十全十美,不要盲目的崇拜某種技術,唯有適合才是真理。
1)Session ID的共享
Session ID是一個例項化Session物件的唯一標識,也是它在Web容器中可以被識別的唯一身份標籤。Jetty和Tomcat容器會通過一個Hash演算法,得到一個唯一的ID字串,然後賦值給某個例項化的Session,此時,這個Session就可以被放入Web容器的SessionManager中開始它短暫的一生。在Servlet中,我們可以通過HttpSession的getId()方法得到這個值,但是我們無法改變這個值。當Session走到它一生盡頭的時候,Web容器的SessionManager會根據這個ID將其“火化”。所以Session ID是非常重要的一個屬性,並且要保證它的唯一性。在單系統中,Session ID只需要被自身的Web容器讀寫,但是在分散式環境中,多個Web容器需要共享同一個Session ID。因此,當某個子系統的Web容器產生一個新的ID時,它必須需要一種機制來通知其他子系統,並且告知新ID是什麼。
2)Session中資料的複製
和共享Session ID的問題一樣,在分散式環境下,Session中的使用者資料也需要在各個子系統中共享。當用戶通過HttpSession的setAttribute()方法在Session中設定了一個使用者資料時,它只存在於當前與使用者互動的那個Web容器中,而對其他子系統的Web容器來說,這些資料是不可見的。當用戶在下一步跳轉到另外一個Web容器時,則又會建立一個新的Session物件,而此Session中並不包含上一步驟使用者設定的資料。其實Session在分散式系統之間的複製實現是簡單的,但是每次在Session資料發生變化時,都在子系統之間複製一次資料,會大大降低使用者的響應速度。因此我們需要一種機制,即可以保證Session資料的一致性,又不會降低使用者操作的響應度。
3)Session的失效
Session是有生命週期的,當Session的空閒時間(maxIdle屬性值)超出限制時,Session就失效了,這種設計主要是考慮到了Web容器的可靠性。當一個系統有上萬人使用時,就會產生上萬個Session物件,由於HTTP的無狀態特性,伺服器無法確切的知道使用者是否真的離開了系統。因此如果沒有失效機制,所有被Session佔據的記憶體資源將永遠無法被釋放,直到系統崩潰為止。在分散式環境下,Session被簡單的建立,並且通過某種機制被複制到了其他系統中。你無法保證每個子系統的時鐘都是一致的,可能相差幾秒,甚至相差幾分鐘。當某個Web容器的Session失效時,可能其他的子系統中的Session並未失效,這時會產生一個有趣的現象,一個使用者在各個子系統之間跳轉時,有時會提示Session超時,而有時又能正常操作。因此我們需要一種機制,當某個系統的Session失效時,其他所有系統的與之相關聯的Session也要同步失效。
4)類裝載問題
在單系統環境下,所有類被裝載到“同一個”ClassLoader中。我在同一個上打了引號,因為實際上並非是同一個ClassLoader,只是邏輯上我們認為是同一個。這裡涉及到了JVM的類裝載機制,由於這個主題不是本文的討論重點,所以相關詳情可以參考相關的JVM文件。因此即使是由memcached或是ZooKeeper返回的位元組陣列也可以正常的反序列化成相對應的物件型別。但是在分散式環境下,問題就變得異常的複雜。我們通過一個例子來描述這個問題。使用者在某個子系統的Session中設定了一個User型別的物件,通過序列化,將User型別的物件轉換成位元組陣列,並通過網路傳輸到了memcached或是ZooKeeper上。此時,使用者跳轉到了另外一個子系統上,需要通過getAttribute方法從memcached或是ZooKeeper上得到先前設定的那個User型別的物件資料。但是問題出現了,在這個子系統的ClassLoader中並沒有裝載User型別。因此在做反序列化時出現了ClassNotFoundException異常。
當然上面描述的4點挑戰只是在實現分散式Session過程中面臨的關鍵問題,並不是全部。其實在我實現分散式Session的整個過程中還遇到了其他的一些挑戰。比如,需要通過filter機制攔截HttpServletRequest,以便覆蓋其getSession方法。但是在不同的Web容器中(例如Jetty或是Tomcat)對HttpServletRequest的實現是不一樣的,雖然都是實現了HttpServletRequest介面,但是各自又添加了一些特性在其中。例如,在Jetty容器中,HttpSession的實現類是一個保護內部類,無法從其繼承並覆蓋相關的方法,只能從其實現類的父類中繼承更加抽象的Session實現。這樣就會造成一個問題,我必須重新實現對Session整個生命週期管理的SessionManager介面。有人會說,那就放棄它的實現吧,我們自己實現HttpSession介面。很不幸,那是不可能的。因為在Jetty的HttpServletRequest實現類的一些方法中對Session的型別進行了強制轉換(轉換成它自定義的HttpSession實現類),如果不從其繼承,則會出現ClassCastException異常。相比之下,Tomcat的對HttpServletRequest和HttpSession介面的實現還是比較標準的。由此可見,實現分散式Session其實是和某種Web容器緊密耦合的。並不像網上有些人的輕描淡寫,僅僅覆蓋setAttribute和getAttribute方法是行不通的。
5.演算法實現
從上述的挑戰來看,要寫一個分散式應用程式是困難的,主要原因是因為區域性故障。由於資料需要通過網路傳輸,而網路是不穩定的,所以如果網路發生故障,則所有的資料通訊都將終止。ZooKeeper並不能解決網路故障的發生,甚至它本身也是基於網路的分散式應用程式。但是它為我們提供了一套工具集合,幫助我們建立安全處理區域性故障的分散式應用程式。接下來我們就開始描述如何實現基於ZooKeeper的分散式Session系統。
1)基於ZooKeeper的分散式Session系統架構
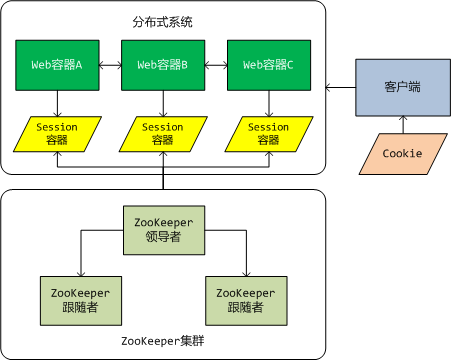
為了實現高可用性,採用了ZooKeeper叢集,ZooKeeper叢集是由一臺領導者伺服器和若干臺跟隨者伺服器構成(總伺服器數要奇數)。所有的讀操作由跟隨者提供,而寫操作由領導者提供,並且領導者還負責將寫入的資料複製到叢集中其他的跟隨者。當領導者伺服器由於故障無法訪問時,剩下的所有跟隨者伺服器就開始進行領導者的選舉。通過選舉演算法,最終由一臺原本是跟隨者的伺服器升級為領導者。當然原來的領導者伺服器一旦被恢復,它就只能作為跟隨者伺服器,並在下一次選舉中爭奪領導者的位置。
Web容器中的Session容器也將發生變化。它不再對使用者的Session進行本地管理,而是委託給ZooKeeper和我們自己實現的Session管理器。也就是說,ZooKeeper負責Session資料的儲存,而我們自己實現的Session管理器將負責Session生命週期的管理。
最後是關於在分散式環境下共享Session ID的策略。我們還是通過客戶端的Cookie來實現,我們會自定義一個Cookie,並通過一定的演算法在多個子系統之間進行共享。下面會對此進行詳細的描述。
2)分散式Session的資料模型
Session資料的儲存是有一定格式的,下圖展示了一個Session ID為”1gyh0za3qmld7”的Session在ZooKeeper上的儲存結構:
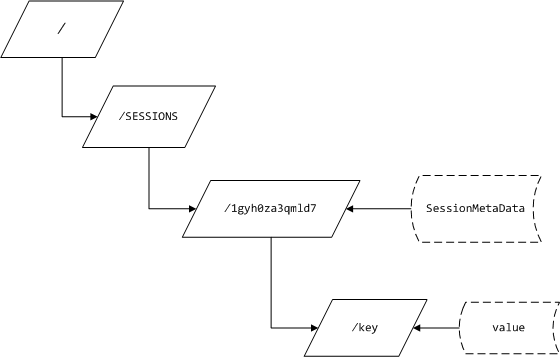
“/SESSIONS”是一個組節點,用來在ZooKeeper上劃分不同功能組的定義。你可以把它理解為一個資料夾目錄。在這個目錄下可以存放0個或N個子節點,我們就把一個Session的例項作為一個節點,節點的名稱就是Session ID。在ZooKeeper中,每個節點本身也可以存放一個位元組陣列。因此,每個節點天然就是一個Key-Value鍵值對的資料結構。
我們將Session中的使用者資料(本質上就是一個Map)設計成多節點,節點名稱就是Session的key,而節點的資料就是Session的Value。採用這種設計主要是考慮到效能問題和ZooKeeper對節點大小的限制問題。當然,我們可以將Session中的使用者資料儲存在一個Map中,然後將Map序列化之後儲存在對應的Session節點中。但是大部分情況下,我們在讀取資料時並不需要整個Map,而是Map中的一個或幾個值。這樣就可以避免一個非常大的Map在網路間傳來傳去。同理,在寫Session的時候,也可以最大限度的減少資料流量。另外由於ZooKeeper是一個小檔案系統,為了效能,每個節點的大小為1MB。如果Session中的Map大於1MB,就不能單節點的儲存了。當然,一個Key的資料量是很少會超過1MB的,如果真的超過1MB,你就應該考慮一下,是否應該將此資料儲存在Session中。
最後我們來關注一下Session節點中的資料——SessionMetaData。它是一個Session例項的元資料,儲存了一些與Session生命週期控制有關的資料。以下程式碼就是SessionMetaData的實現:
publicclass SessionMetaDataimplements Serializable {
privatestaticfinallongserialVersionUID = -6446174402446690125L;
private Stringid;
/**session的建立時間*/
private LongcreateTm;
/**session的最大空閒時間*/
private LongmaxIdle;
/**session的最後一次訪問時間*/
private LonglastAccessTm;
/**是否可用*/
private Booleanvalidate=false;
/**當前版本*/
privateintversion= 0;
/**
*構造方法
*/
public SessionMetaData() {
this.createTm = System.currentTimeMillis();
this.lastAccessTm = this.createTm;
this.validate = true;
}
……以下是N多getter和setter方法
其中需要關注的屬性有:
a)id屬性:Session例項的ID。
b)maxIdle屬性:Session的最大空閒時間,預設情況下是30分鐘。
c)lastAccessTm屬性:Session的最後一次訪問時間,每次呼叫Request.getSession方法時都會去更新這個值。用來計算當前Session是否超時。如果lastAccessTm+maxIdle小於System.currentTimeMillis(),就表示當前Session超時。
d)validate屬性:表示當前Session是否可用,如果超時,則此屬性為false。
e)version屬性:這個屬性是為了冗餘Znode的version值,用來實現樂觀鎖,對Session節點的元資料進行更新操作。
這裡有必要提一下一個老生常談的問題,就是所有儲存在節點上的物件必須是可序列化的,也就是必須實現Serializable介面,否則無法儲存。這個問題在memcached和ZooKeeper上都存在的。
3)實現過程
實現分散式Session的第一步就是要定義一個filter,用來攔截HttpServletRequest物件。以下程式碼片段,展現了在Jetty容器下的filter實現。
publicclass JettyDistributedSessionFilterextends DistributedSessionFilter {
private Loggerlog = Logger.getLogger(getClass());
@Override
publicvoid init(FilterConfig filterConfig)throws ServletException {
super.init(filterConfig);
//例項化Jetty容器下的Session管理器
sessionManager =new JettyDistributedSessionManager(conf);
try {
sessionManager.start();//啟動初始化
//建立組節點
ZooKeeperHelper.createGroupNode();
log.debug("DistributedSessionFilter.init completed.");
}catch (Exception e) {
log.error(e);
}
}
@Override
publicvoid doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException,
ServletException {
//Jetty容器的Request物件包裝器,用於重寫Session的相關操作
JettyRequestWrapper req =new JettyRequestWrapper(request,sessionManager);
chain.doFilter(req, response);
}
}
這個filter是繼承自DistributedSessionFilter的,這個父類主要是負責完成初始化引數設定等通用方法的實現,程式碼如下所示:
publicabstractclass DistributedSessionFilterimplements Filter {
protected Loggerlog= Logger.getLogger(getClass());
/**引數配置*/
protected Configurationconf;
/**Session管理器*/
protected SessionManagersessionManager;
/**初始化引數名稱*/
publicstaticfinal StringSERVERS="servers";
publicstaticfinal StringTIMEOUT="timeout";
publicstaticfinal StringPOOLSIZE ="poolsize";
/**
*初始化
*@see javax.servlet.Filter#init(javax.servlet.FilterConfig)
*/
@Override
publicvoid init(FilterConfig filterConfig)throws ServletException {
conf =new Configuration();
String servers = filterConfig.getInitParameter(SERVERS);
if (StringUtils.isNotBlank(servers)) {
conf.setServers(servers);
}
String timeout = filterConfig