
python之美--開發原則篇
上一篇詳細的介紹了python的幾個有深度的知識點,本篇我想再昇華到一個高度,python開發中到底要遵守哪些原則。
1 可讀性:
我把可讀性放在python原則第一位,是因為python太大的靈活性,導致了每個人的程式碼風格天馬行空。像Java那種語言規定的很嚴謹,雖然程式碼相對較長,但是通過變數定義、函數出入參、介面型別等都可以猜得出程式碼要做什麼。但是python卻不一樣,不review玩全部程式碼根本沒把握知道函式或類到底要達到什麼目的。所以在編寫程式碼時儘量用一些別人看得懂的寫法。
例如list[::-1]和reversed(list)雖然都可以讓list倒轉,但是明顯後者的可讀性要好得多。你可能說前者的程式碼更簡潔,但是我們要追求的簡潔是從函式設計層面來說的,而不是犧牲可讀性的細節層面上。
2 儘量用函式思想去程式設計
例如:
def numSwitch(x) :
return{
0 : 'value is 0',
1 : 'value is 1',
2 : 'value is 2'
}.get(x,'No match x value')
if __name__ == '__main__':
print(numSwitch(2))
print(numSwitch(4))
儘量不要用if elsif elsif else這樣去寫,會讓可讀性變很差,維護性和擴充套件性也不好。
3 註解註解註解,重要的事情說3遍。
雖然所有語言的程式碼都需要註解,但是python我認為更需要註解,因為它太靈活了,誰知道你的函式裡新增或者刪除了什麼新的變數,Java看一眼介面方法和出入參能明白裡面在幹什麼,但是python做不到,沒有註解的話需要別人review完一遍你的程式碼才能搞明白在幹啥。
做了10年的開發,我理想中的最好的程式碼就是隻看註解就能明白程式碼。所以在某種程度上來講,註解比程式碼本身還要重要。
4儘量用import a,有節制的用from a import A,不要用from a import *
Python的記憶體中維護著一批內建模組,存放在sys.modules中。
from a會讓a儲存到sys.modules
當然直接import a也有缺點,要想使用a中的functionA時每次都要a.functionA這樣來使用。
5 降低演算法的複雜度
演算法的複雜度主要從時間複雜度和空間複雜度兩個維度來衡量,我前面有篇介紹八大排序演算法的博文中有詳細介紹過複雜度的問題《排序演算法的詳解與總結》
我們來看下複雜度之間的大小關係:
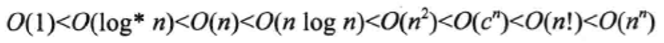
你可能說將,難道我沒寫一行程式碼或者演算法,我都要計算下它的複雜度然後再去想下有沒有更好的演算法,那每天都不要幹活了。是的,這樣確實燒腦而且影響開發效率,所以我給出的建議是,當代碼中涉及到
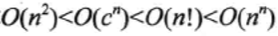
這幾層複雜度時需要考慮下優化的問題,其它的情況可以忽略,優化效果不明顯。
既然談到優化,我們就需要掌握一些計算程式執行速率的小技巧。
執行時間分析推薦使用time.time()、cProfile、pstats,其中前者用在簡單的小模組程式碼監控,後兩者用於深層次的全面的分析。
程式碼如下:
def foo(num):
x = 0
for i in range(num):
x += i**2
return x
if __name__ == '__main__' :
import cProfile
cProfile.run('print(foo(10000))',filename='C:\\python\\tmp\\report.txt',sort='tottime')
import pstats
p = pstats.Stats('C:\\python\\tmp\\report.txt')
p.sort_stats('tottime').print_stats()
import time
t1 = time.time()
foo(10000)
print('time wast : %f' %(time.time()-t1))
輸出如下:
5 function calls in 0.004 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.004 0.004 0.004 0.004 C:/python/work/smart/pyart/yieldtest.py:1(foo)
1 0.000 0.000 0.004 0.004 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method builtins.print}
1 0.000 0.000 0.004 0.004 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
0.0040225982666015625
一般只用cProfile也可以,其中輸出檔案地址和排序是可選的;pstats比cProfile分析的更全面。
6 做好單元測試
單元測試在我眼裡有兩點作用,第一,可以保證程式的可用性,這一點不需要解釋,是單元測試的根本目的;第二,可以作為程式的另一種API,好的單元測試可以引導呼叫者如何來使用你的程式。
Python自帶的單元測試模組是unittest,使用起來很簡單,我們從淺入深來了解它。
Unittest最重要的是TestCase,每一個最簡單驗證單元被稱為一個case;
執行測試的物件叫TestRunner,它相當於一個容器,來載入和執行測試任務;
TestSuite可以把多個case組裝起來形成一個相對較複雜的測試用例。
瞭解了TestCase、TestRunner、TestSuite的定義和關係,我們來看下我的案例。
我的目錄結構是這個樣子的:
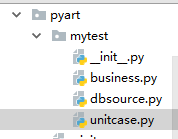
business.py裡是我的業務邏輯,裡面是個業務類以及testcase
dbsource.py裡是我的資料庫互動邏輯,裡面是幾個函式以及testcase
unitcase.py裡是我想整合業務與資料編排更復雜的測試。
business.py程式碼如下:
import unittest
class Business(object):
def __init__(self,x,y):
self.x = x
self.y = y
def sum(self):
return self.x+self.y
def mult(self):
return self.x * self.y
class BuninessTest(unittest.TestCase):
# 實體級的預處理
@classmethod
def setUpClass(cls):
print('Invoke setup class function')
# 實體級的結束回收
@classmethod
def tearDownClass(cls):
print('Invoke tearDown class function')
#函式級的預處理
def setUp(self):
print('Invoke setup function')
self.business = Business(2,3)
#函式級的結束回收
def tearDown(self):
print('Invoke tearDown function')
self.business = None
def test_1_sum(self):
print('Invoke test_sum function')
self.assertEqual(5,self.business.sum())
def test_2_mult(self):
print('Invoke test_mult function')
self.assertEqual(6, self.business.mult())
if __name__ == '__main__':
unittest.main()測試用例類必須繼承Testcase;setUp()和tearDown()是非必需的,如果自己實現了就是覆蓋了父類中的函式,這兩個函式在每個測試方法執行前後被呼叫;setUpClass()和tearDownClass()也是非必需的,在每個測試實體執行前後被呼叫;所有的測試用例方法必須以test開頭,我之所以給他們加了數字是因為如果不經過編排它們的執行順序是按照函式名稱的大小從小到大來執行的,也就說通過新增數字我想控制它們的預設的執行順序。
如果還不是很清楚,對照著單獨執行business.py的輸出結果:
Ran 2 tests in 0.002s
OK
Invoke setup class functionInvoke setup function
Invoke test_sum function
Invoke tearDown function
Invoke setup function
Invoke test_mult function
Invoke tearDown function
Invoke tearDown class functiondbsource.py程式碼如下:
import unittest
class DBManager(object):
pass
#連線資料庫
def connect():
print('DB connected')
return True
#關閉資料庫
def drop():
print('DB droped')
manager = None
return True
class DBmanagerTest(unittest.TestCase):
def test_1_connect(self):
print('Invoke test_connect function')
self.assertEqual(True,connect())
def test_2_drop(self):
print('Invoke test_drop function')
self.assertEqual(True, drop())
if __name__ == '__main__':
unittest.main()對比business來說簡單多了,不再做詳細說明,我這裡只是為了演示單元測試可以測類中的方法,也可以直接測函式。
unitcase.py程式碼如下:
import unittest
import pyart.mytest.business as business
import pyart.mytest.dbsource as dbsource
if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTest(dbsource.DBmanagerTest('test_1_connect'))
suite.addTest(business.BuninessTest('test_2_mult'))
suite.addTest(business.BuninessTest('test_1_sum'))
suite.addTest(dbsource.DBmanagerTest('test_2_drop'))
with open('C:\\python\\tmp\\UnittestTextReport.txt', 'a') as f:
runner = unittest.TextTestRunner(stream=f, verbosity=2)
runner.run(suite)
#unittest.TextTestRunner().run(suite)
unitcase.py中對前面兩個模組裡的testcase做了整合,並且將測試結果輸出到檔案中,verbosity代表著case一旦不通過堆疊等內容的詳細程度,預設為1,0最簡單,2最詳細。
當然本地調測可以用最後註釋的那一行,不一定非要輸出到檔案中。
結果如下:
Invoke test_connect function
DB connected
Invoke setup class function
Invoke setup function
Invoke test_mult function
Invoke tearDown function
Invoke setup function
Invoke test_sum function
Invoke tearDown function
Invoke tearDown class function
Invoke test_drop function
DB droped除開unittest模組,我們還可以通過pip安裝一個叫nose的測試元件

nose可以在指定的目錄下遍歷test開頭的模組,自動執行裡面的test開發的函式,我們可以將模組或者子包裡的unittest測試與nose結合起來,就組成了更大目錄的直到全專案的自動測試了。
例如我對unitcase.py做如下改動:
先把模組名改成test.py
再把裡面單元測試的內容封裝在一個test開頭的函式內,程式碼如下:
import unittest
import pyart.mytest.business as business
import pyart.mytest.dbsource as dbsource
def testfunction():
suite = unittest.TestSuite()
suite.addTest(dbsource.DBmanagerTest('test_1_connect'))
suite.addTest(business.BuninessTest('test_2_mult'))
suite.addTest(business.BuninessTest('test_1_sum'))
suite.addTest(dbsource.DBmanagerTest('test_2_drop'))
unittest.TextTestRunner().run(suite)
if __name__ == '__main__':
testfunction()這樣我就可以用nose來測試該package了:
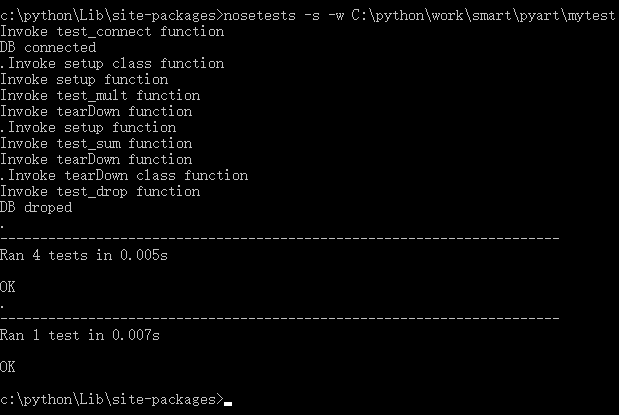
設想如果我規定專案中所有package都按照此要求來開發,那麼我可以直接node我整個專案做全內容的單元測試了。
7 藉助風格檢查工具
一個專案同一個team最好是規定一種寫作風格,我推薦使用pep8
安裝:pip install –U pep8
檢索風格錯誤:pep8 –first optparse.py
詳細檢索,甚至可以給出修改意見:pep8 –show-source –show-pep8 testsuite/E40.py
類似的還有Pyflakes、Pylint等,自己可以去了解下。
8 糾結
原則基本總結那麼多吧,我對python的瞭解目前也只有這麼些,以後持續努力。不過在寫python的過程中也有很糾結的時候,例如我們要計算對從1到100求和。
一般我們會這麼寫:
def mySum1(n) :
sum = 0
for i in range(n):
sum += i
return sum
但是如果1到1億呢?是不是這樣寫執行效率更高:
def mySum2(n) :
return (n * (n + 1) / 2)
但這就涉及到一個性能與可讀性的取捨問題,我也不知道哪種寫法更好,可能給第二種加上註釋更好一些吧。
作為python之美的Ending,我最後說一點python的不足吧。
第一:版本迭代對語法衝擊很大,作為開發人員不僅需要知識上的更新,還需要對現有程式碼進行改造。
第二:CPU密集型高併發支撐能力太差了,雖然有多程序但是程序數太可憐了,而且程序往往沒有執行緒來的快,這方面一直被Java碾壓。
可能python還是太年輕了吧,目前只到第三個版本,Java也是到了JDK1.4才出露鋒芒,5.0開始大放異彩,相信再給它點時間,它能帶給我們更多的驚喜。