
NMT:神經網路機器翻譯
前言
SMT是在神經網路之前最主流的翻譯模式,統計機器翻譯;NMT則是基於神經網路的翻譯模式,也是當前效果最好的翻譯模式。現在基於幾篇paper來梳理下神經網路下的翻譯模型。
NMT based RNN
1) First End-to-End RNN Trial
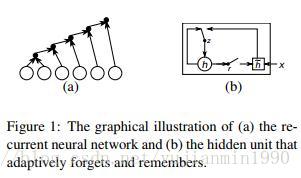
2014年,Cho首次將End-to-End的RNN結構應用到翻譯領域,是以統計機器翻譯模型為主,但是用NMT訓練得到的短語對,來給SMT作新增特徵。另外也是GRU第一次被提出的paper,就是圖結構有點糙,GRU的結構比LSTM要簡單。看不動就看下面的圖。

2) Complete End-to-End RNN NMT
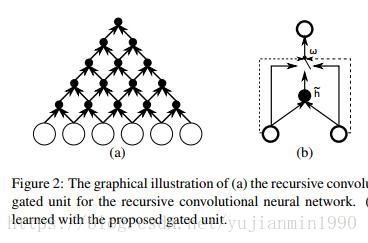
Properties of NMT是Learning Phrase的兄弟篇,也是Cho的同年佳作,首次以GRU和grConv【GRU的升級版本】實現End-to-End的NMT結構,並分析了NMT時的特性。
a) NMT在句子長度增加是,效果下降得厲害。
b) 詞表長度對NMT有很大的影響。
c) grConv的NMT可以在無監督的情況下,學習到目標語言的語法結構。
其中對GRU和grConv【gated Recurrent Convolutional Network】的結構拆分非常有意思,如下圖:
2014年,Sutskever 首次實現完整意義上的end-to-end的LSTM版本的NMT模型,兩個Deep LSTM分別做encoder 和 decoder,其中,反轉輸入(target不動)訓練會提高翻譯效果。
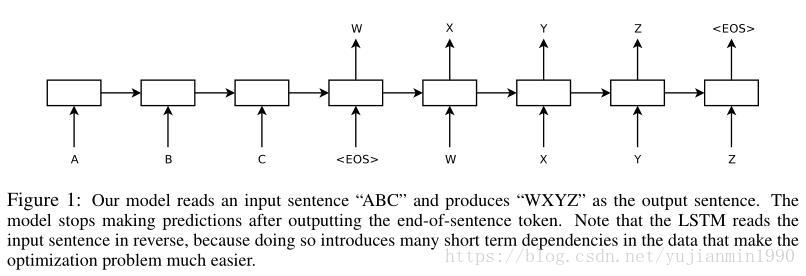
具體操作部分,out-of-vocabulary 作UNKNOWN詞,評估是用beam-search 。並行在8張GPU上,每層在一個卡上。使用了4層Deep LSTM,堆疊的LSTM結構,整體資料集迭代次數在8次以內。並且根據句子長短對minibatch作了優化,長度基本一致的在一個batch內,防止空轉計算。用了個類似clicp-gradient的約束梯度爆炸的技巧。
notice 1:這個方法很好,就是訓練太耗時,需要10天的時間。
notice 2:不是補充訓練,而是就用反轉直接訓練。【反轉訓練效果好的非正式解釋:引入了許多短期依賴】
3) attention in NMT
這篇文章《NMT by Jointly Learning to Align and Translate》從14年就開始提交,7易其稿,一直到16年才完成最終版,看下作者Bahdanau和Cho,都是Bengio實驗室的,已經產學研一條龍了。
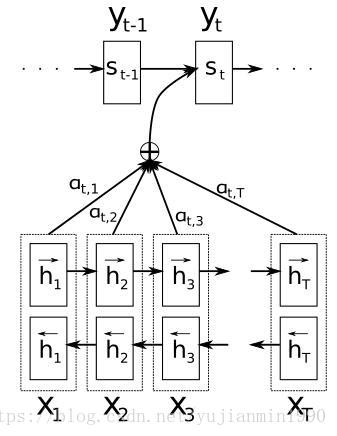

每個輸入序列的詞,都有個解釋向量,其對當前預測詞的貢獻權重採用softmax方式計算,某個詞對當前預測詞的匹配度由來確定,所有輸入序列中的詞都通過對注意力向量作貢獻。
好在有其他的研究文章可以來輔助確認模型細節,強烈推薦這篇,給出了Attention的基本結構型別說明,其開放原始碼。一個很好地介紹Attention的部落格,後面會作為翻譯部落格。另外專門寫篇部落格,討論NMT by Jointly Learning 與Effective Approaches to Attention-based NMT 和Show and Tell, Neural Image Generation with Visual Attention。
notice 1: Attenttion是一種思想,並不是一種模型,有很多變種attention方法Effective Approaches to Attention-based NMT,並且在翻譯之外很多地方都有應用,比如影象描述:《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,文字分類:《Hierarchical Attention Networks for Document Classification》,關係分類:《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》。
notice 2: 非常需要吐槽下NMT by Jointly Learning這篇文章,看似寫得很清晰,但是你根據論文內容是沒法回答下面兩個問題的:
a) 為什麼不能直接model化和的關係,而是繞道和匹配度?
b) 無法確定和是否用同一個BiRNN來描述,即便有圖也沒法確認,更沒有文字明確給出,只能看原始碼。
關於第一點,有模糊地解釋:“The probability , or its associated energy , reflects the importance of the annotation with respect to the previous hidden state in deciding the next state and generating . Intuitively, this implements a mechanism of attention in the decoder.”,這種解釋都是似是而非的,決定當前狀態,那麼為什麼不包含呢?為什麼不直接對和直接建模呢?
NMT in google
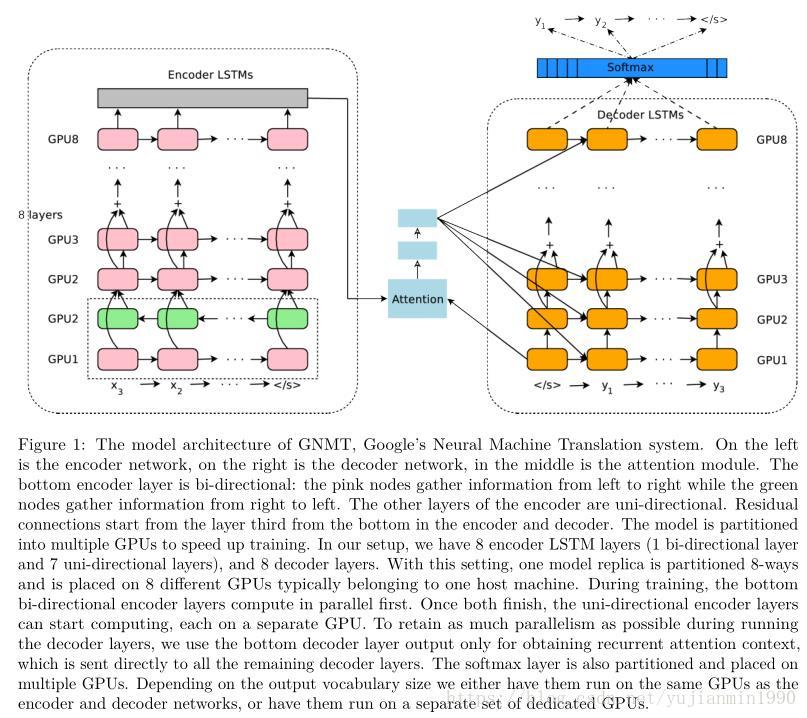
Google翻譯這麼拽,集合了attention機制,Deep機制,並且做了各種工程優化,非常值得一看。
NMT的三個主要缺陷:1)訓練和推斷速度慢。2)處理稀少詞時會失效。3)有時翻譯不能cover全部輸入。
google的NMT作了很大的工程改進,具體如下,更具體見論文。
1) 8層LSTM分別作 Encoder和 Decoder,同時加以Residual Block以降低學習難度;
2) 使用Attention,僅連線Encoder的bottom層和Decoder的top層;
3) 用低精度的推斷來加快翻譯速度;
4) 為改善稀少詞的處理,使用wordpiece,將單詞拆成有限子集單元,極大地平衡了單字母的複雜性和完整單詞的有效性,並且避開了對未知單詞的處理;
5) 利用強化學習來改善翻譯效果。
NMT based CNN
思考 與 總結
1) NMT大部分以Encoder-Decoder結構為基礎結構。
2) 翻譯模型特別喜歡bidirectional,注意其無法適應線上的缺陷。
3) Attention並不侷限於翻譯模型上,而是在各個地方都有應用。
4) NMT的訓練耗時是個長久存在的問題,需要在工程中密切關注。
補充知識
1) 關於翻譯結果的查詢方法:Beam Search
如果直接搜尋模型的最優路徑,需要比較所有的可能路徑,耗時耗力。Beam Search則每次選擇Top-N個選項,相當於每次只對比當次所有輸出,然後選擇Top-N。

2) 關於翻譯效果的評估方法:BLEU 和 Meteor
BLEU-2005是改進unigram-precision的改進版,是[1,n]-gram precision的幾何平均值,通常足矣。是penalty,是候選翻譯的平均長度,是參考翻譯的平均長度。
是修正的n-gram precision,候選翻譯的n-gram 出現在任意參考翻譯中的數量,除以總候選翻譯的n-gram數量。