
成功安裝hadoop叢集
之前學習了一段時間的hadoop,最近想總結一下自己的成果,便用寫部落格的方式去複習。hadoop入門難就難在搭建叢集。初學的開發人員大可不必去研究hadoop安裝,可以先往後面學習。所以這裡總結hadoop安裝步驟供初學者拷貝。
1:hadoop和jdk下載
為了保證之後不出任何因為版本問題,請使用本人選用版本。我選擇的jdk1.7和hadoop2.7.2。所以:
首先下載安裝包jdk-7u71-linux-i586.tar.gz。
如果不會下載jdk歷史版本,請百度搜索“如何下載jdk歷史版本”。下載jdk1.7是因為1.7版本以上jdk支援hadoop,選擇32位是因為,我之前使用64位後,hadoop安裝出現很多錯誤,spark安裝也會出現錯誤
其次下載安裝包hadoop-2.7.2.tar.gz。
進入http://apache.fayea.com/hadoop/common/,點選下載hadoop2.7.2。
2:VMware下安裝centOS
下載centOS,我選擇的版本是CentOS-6.4-i386-bin-DVD1.iso。 (以上所有工具不會下載者,請加我的百度雲好友:鵬少1996) 開啟VMware,點選檔案->建立虛擬機器->下一步->下一步->(找到你的CentOS映像檔案後)下一步->輸入全名,使用者名稱,密碼,確認,這裡最好全部用hadoop便於記憶->將虛擬機器名稱改為hadoop_01,選擇一個位置,最好新建一個位置,便於管理如下圖。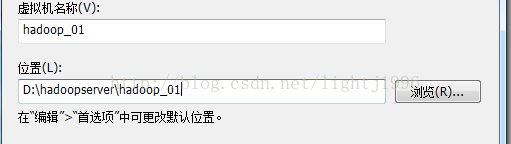
後面全部預設點選下一步。
後面作業系統便開始安裝了。。。。。
如果遇到提示需要按f12,就按f12,進入如下介面,就只要等待即可

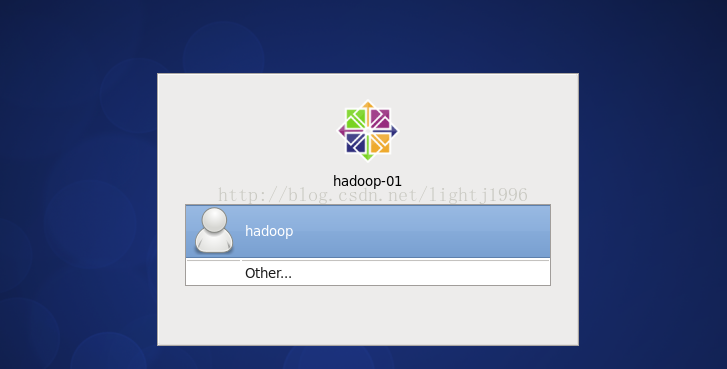
在VMware上點選編輯後點擊虛擬網路編輯器
選擇圖中劃線部分,將劃線部分設定和我一樣,然後點選“NAT設定”-->然後將閘道器設為192.168.117.2.
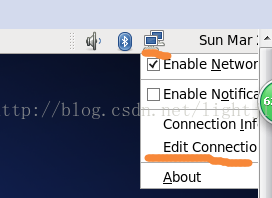
進入CentOS,右擊螢幕右上角的電腦圖示,然後選擇Edit Connection
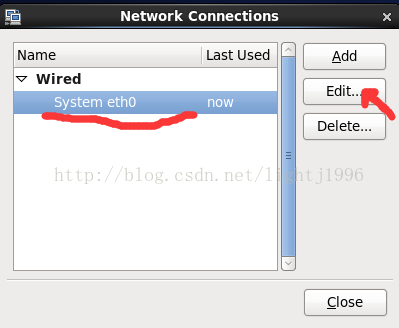
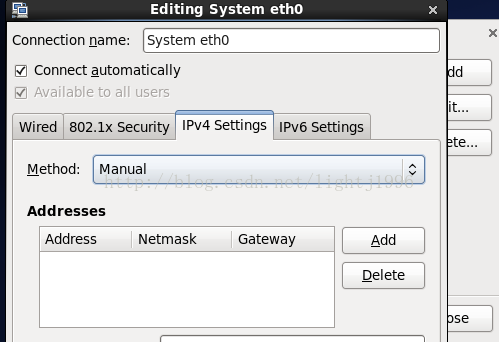
選擇IPV4 Settings後選擇Method為Manual。 點選add,將address設為192.168.117.41,netmask設為255.255.255.0,gateway設為192.168.117.2,DNSserver設為192.168.117.2。然後關機。 關機後,點選hadoop _01這臺虛擬機器的網路介面卡,選擇自定義(U):特定虛擬網路:VMnet8(Net模式) 再次開機
3安裝jdk和hadoop
2 在hadoop _01桌面右擊然後左擊open in terminal
3 在終端輸入ll,會看見剛剛拖進來的jdk安裝包
4 輸入cd /root,到達根目錄,輸入mkdir apps
5 輸入cd desktop,到達桌面,輸入tar -zxvf jdk-7u71-linux-i586.tar.gz -C /root/apps 解壓安裝包到/roor/apps
6 輸入cd /root/app,輸入ll,你會看到解壓後的jdk目錄,輸入mv (現在的jdk目錄名) jdk,將目錄名重新命名為jdk
7 配置環境變數 :輸入vi /etc/profile,進入vim編輯器,按下鍵盤上的 “i”就可以在這個檔案中插入資料,按 鍵盤上的向下方向鍵到達檔案最低部
輸入
export JAVA_HOME=/root/apps/jdk
export HADOOP_HOME=/root/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
按下鍵盤上的esc鍵,輸入 :wq就可以儲存並退出編輯(如果想了解vim編輯,可以百度一下)
(為了方便已經將hadoop的環境變數提前配置好) 8輸入source /etc/profile 使配置生效, 輸入java -version檢視是否配置成功。 2)安裝hadoop 1 同樣的方法將hadoop安裝包拖到hadoop_01的桌面。 2 輸入cd /root/desktop 到桌面目錄,輸入tar -zxvf hadoop-2.7.2.tar.gz -C /root/apps 解壓安裝包到/roor/apps 3 輸入 cd /root/apps ,輸入ll會看到hadoop目錄 輸入 mv hadoop-2.7.2 hadoop 重新命名這個目錄 4 cd hadoop/etc/hadoop, 這裡是hadoop的配置檔案目錄,ll 會看見很多配置檔案 5接下來修改配置檔案即可: a : vi hadoop-env.sh 將export JAVA_HOME={$JAVA_HOME}改為export JAVA_HOME=/root/apps/jdk (如果這一行前面有"#",將 “#”去掉,因為"#"代表註釋 ) b :vi core-site.xml 在<configuration> </configuration> 中間插入 <property><name>fs.defaultFS</name>
<value>hdfs://hadoop_01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoop/tmp/</value>
</property>
b :vi hdfs-site.xml 同上面一樣,配置後如下 <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
c :mv mapred-site.xml.template mapred-site.xml 然後vi mapred-site.xml <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> </configuration>
d: vi yarn-site.xml <configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop_01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> vi slaves 將localhost 改為: hadoop _01 hadoop _02
hadoop _03
到目前為止,hadoop就已經配置好了。
4搭建hadoop叢集
1 修改主機名: vi /etc/sysconfig/network將HOSTNAME=localhost.localdomain改為 HOSTNAME=hadoop_01 2修改網路對映:
vi /etc/hosts
在末尾插入: 192.168.117.41 hdp-ha-01
192.168.117.42 hdp-ha-02
192.168.117.43 hdp-ha-03
192.168.117.44 hdp-ha-04
192.168.117.45 hdp-ha-05
192.168.117.46 hdp-ha-06
192.168.117.47 hdp-ha-07
3關閉圖形介面:
vi /etc/inittab 將 id:5:initdefault:改為 id:3:initdefault:
4關閉防火牆
service iptables stop
5關機: halt 7克隆虛擬出hadoop_02和hadoop_03 在Vmware軟體上右擊hadoop _01 選擇 管理- >克隆->下一步->下一步->選擇建立完整克隆,下一步->將虛擬機器名稱改為hadoop_02->完成 同理克隆出一個hadoop _03 8 因為hadoop _02和hadoop_03克隆來的,所以 ,還要修改他們的主機名,和ip: 克隆完成後開啟三臺虛擬機器 9在hadoop_02開機後輸入:setup->Network configuration->Device configuration->eth0(eth0)... 將name和Device都改為eth1,將Ip改為192.168.117.42 然後->OK->Save->Save&Quit->quit 10:重啟網路 service network restart 11:vi /etc/sysconfig/network 將HOSTNAME=hadoop_01改為HOSTNAME=hadoop_02 12:重啟虛擬機器: reboot 13:同9到12將hadoop_03的,ip改為192.168.117.43主機名改為hadoop_03。 14:等hadoop_02和hadoop_03重啟完成後,在hadoop _01上配置到三臺主機的免密登入 在hadoop_01上輸入ssh-keygen後一直預設回車,結束選擇後,輸入 ssh-copy-id hadoop_01->輸入Y->輸入密碼hadoop ssh-copy-id hadoop_02->輸入Y->輸入密碼hadoop
ssh-copy-id hadoop_03->輸入Y->輸入密碼hadoop