
資料倉庫分層設計
為什麼要對資料倉庫分層:
a)用空間換時間,通過大量的預處理來提升應用系統的使用者體驗(效率),因此資料倉庫會存在大量冗餘的資料;
b)如果不分層的話,如果源業務系統的業務規則發生變化將會影響整個資料清洗過程,工作量巨大
c)通過資料分層管理可以簡化資料清洗的過程,因為把原來一步的工作分到了多個步驟去完成,相當於把一個複雜的工作拆成了多個簡單的工作,把一個大的黑盒變成了一個白盒,每一層的處理邏輯都相對簡單和容易理解,這樣我們比較容易保證每一個步驟的正確性,當資料發生錯誤的時候,往往我們只需要區域性調整某個步驟即可。
大資料資料倉庫是基於HIVE構建的資料倉庫,分佈檔案系統為HDFS,資源管理為Yarn,計算引擎主要包括MapReduce/Tez/Spark等,分層架構如下:
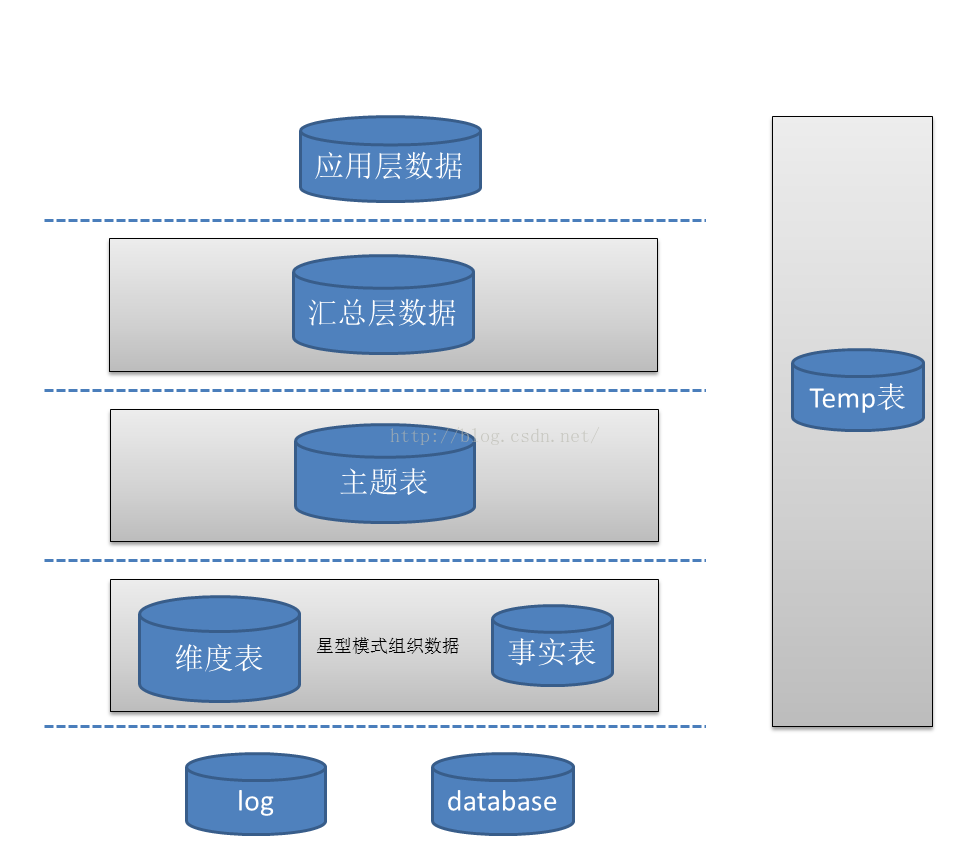
資料倉庫標準上可以分為四層:ODS(臨時儲存層)、PDW(資料倉庫層)、MID(資料集市層)、APP(應用層)
1、ODS層:
為臨時儲存層,是介面資料的臨時儲存區域,為後一步的資料處理做準備。一般來說ODS層的資料和源系統的資料是同構的,主要目的是簡化後續資料加工處理的工作。從資料粒度上來說ODS層的資料粒度是最細的。ODS層的表通常包括兩類,一個用於儲存當前需要載入的資料,一個用於儲存處理完後的歷史資料。歷史資料一般儲存3-6個月後需要清除,以節省空間。但不同的專案要區別對待,如果源系統的資料量不大,可以保留更長的時間,甚至全量儲存;
也可稱為資料來源層:日誌或者關係型資料庫,並通過Flume、Sqoop、Kettle等etl工具匯入到HDFS,並對映到HIVE的資料倉庫表中。
2、PDW層:
為資料倉庫層,PDW層的資料應該是一致的、準確的、乾淨的資料,即對源系統資料進行了清洗(去除了雜質)後的資料。這一層的資料一般是遵循資料庫第三正規化的,其資料粒度通常和ODS的粒度相同。在PDW層會儲存BI系統中所有的歷史資料,例如儲存10年的資料。
2.1、事實表是資料倉庫結構中的中央表,它包含聯絡事實與維度表的數字度量值和鍵。事實資料表包含描述業務(例如產品銷售)內特定事件的資料。
2.2、維度表是維度屬性的集合。是分析問題的一個視窗。是人們觀察資料的特定角度,是考慮問題時的一類屬性,屬性的集合構成一個維。資料庫結構中的星型結構,該結構在位於結構中心的單個事實資料表中維護資料,其它維度資料儲存在維度表中。每個維度表與事實資料表直接相關,且通常通過一個鍵聯接到事實資料表中。星型架構是資料倉庫比較流向的一種架構。
星型模式的基本思想就是保持立方體的多維功能,同時也增加了小規模資料儲存的靈活性。
說明:
1)、事實表就是你要關注的內容;
2)、維度表就是你觀察該事務的角度,是從哪個角度去觀察這個內容的。
例如,某地區商品的銷量,是從地區這個角度觀察商品銷量的。事實表就是銷量表,維度表就是地區表
3、MID層:
為資料集市層,這層資料是面向主題來組織資料的,通常是星形或雪花結構的資料。從資料粒度來說,這層的資料是輕度彙總級的資料,已經不存在明細資料了。從資料的時間跨度來說,通常是PDW層的一部分,主要的目的是為了滿足使用者分析的需求,而從分析的角度來說,使用者通常只需要分析近幾年(如近三年的資料)的即可。從資料的廣度來說,仍然覆蓋了所有業務資料。
主題表:主題(Subject)是在較高層次上將企業資訊系統中的資料進行綜合、歸類和分析利用的一個抽象概念,每一個主題基本對應一個巨集觀的分析領域。在邏輯意義上,它是對應企業中某一巨集觀分析領域所涉及的分析物件。例如“銷售分析”就是一個分析領域,因此這個資料倉庫應用的主題就是“銷售分析”。
面向主題的資料組織方式,就是在較高層次上對分析物件資料的一個完整並且一致的描述,能刻畫各個分析物件所涉及的企業各項資料,以及資料之間的聯絡。所謂較高層次是相對面嚮應用的資料組織方式而言的,是指按照主題進行資料組織的方式具有更高的資料抽象級別。與傳統資料庫面向應用進行資料組織的特點相對應,資料倉庫中的資料是面向主題進行組織的。例如,一個生產企業的資料倉庫所組織的主題可能有產品訂貨分析和貨物發運分析等。而按應用來組織則可能為財務子系統、銷售子系統、供應子系統、人力資源子系統和生產排程子系統。
4、APP層:
為應用層,這層資料是完全為了滿足具體的分析需求而構建的資料,也是星形或雪花結構的資料。從資料粒度來說是高度彙總的資料。從資料的廣度來說,則並不一定會覆蓋所有業務資料,而是MID層資料的一個真子集,從某種意義上來說是MID層資料的一個重複。從極端情況來說,可以為每一張報表在APP層構建一個模型來支援,達到以空間換時間的目的資料倉庫的標準分層只是一個建議性質的標準,實際實施時需要根據實際情況確定資料倉庫的分層,不同型別的資料也可能採取不同的分層方法。
4.1、彙總資料層:聚合原子粒度事實表及維度表,為滿足固定分析需求,以提高查詢效能為目的,形成的高粒度表,如週報、月報、季報、年報等。
4.2、應用層:
為應用層,這層資料是完全為了滿足具體的分析需求而構建的資料,也是星形結構的資料。應用層為前端應用的展現提現資料,可以為關係型資料庫組成。
—【補充】
資料快取層:
用於存放介面方提供的原始資料的資料庫層,此層的表結構與源資料保持基本一致,資料存放時間根據資料量大小和專案情況而定,如果資料量較大,可以只存近期資料,將歷史資料進行備份。此層的目的在於資料的中轉和備份。
核心資料層:
此層的資料在資料快取層的基礎上做了一定程度的整合,稱之為資料集市,儲存上仍是關係模型。此層的目的在於進行必要的資料整合為下一步多維模型做準備。
分析應用層:
此層的資料為根據業務分析需要構造的多維模型資料。資料可以直接用於分析展現。
說明:資料層次的劃分可以根據實際專案需要進行裁剪,如果業務相對簡單和獨立,可以將核心資料層與分析應用層進行合併。另外,分析應用的資料可以來自多維模型的資料,也可以來自關係模型資料甚至原始資料
微信公眾號:程式國度
