
《Python 原始碼剖析》一些理解以及勘誤筆記(3)
以下是本人閱讀此書時理解的一些筆記,包含一些影響文義的筆誤修正,當然不一定正確,貼出來一起討論。
注:此書剖析的原始碼是2.5版本,在python.org 可以找到原始碼。紙質書閱讀,pdf 貼圖。
文章篇幅太長,故切分成3部分,這是第三部分。
p316: 初始化執行緒環境
Python 虛擬機器執行期間某個時刻整個的執行環境如下圖:
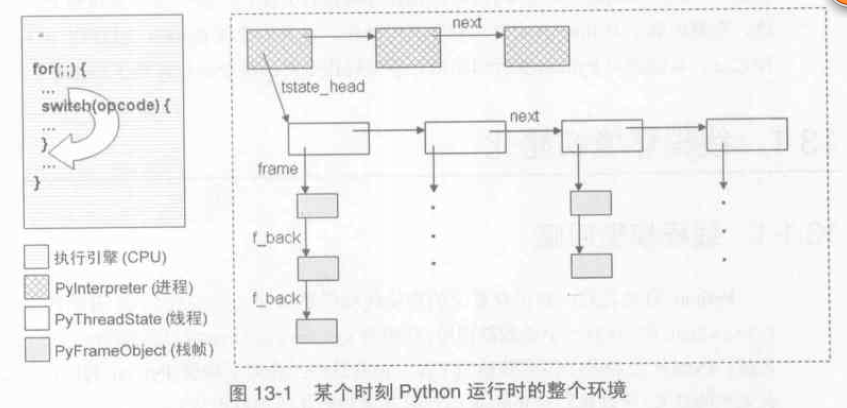
建立聯絡之後的PyThreadState 物件和 PyInterpreterState 物件的關係如下圖:
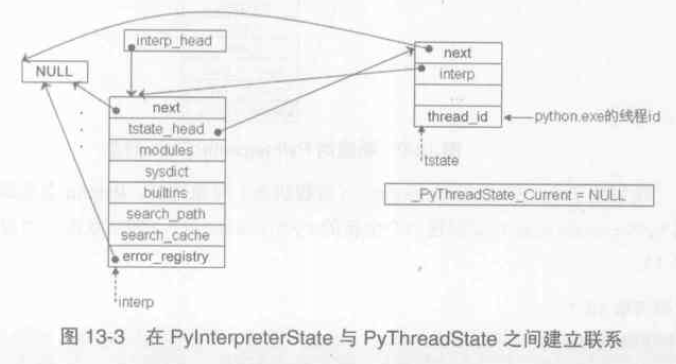
_PyThreadState_Current 是個全域性變數,是當前活動執行緒對應的 PyThreadState 物件;
interp->modules 指向一個 PyDictObject 物件(module_name, module_object),維護系統所有的module,可能動態新增,為所有PyThreadState 物件所共享;import sys sys.modules or sys.__dict__['modules'] 可以訪問到module 集合。同理 interp->builtins 指向 __builtins__.__dict__; interp->sysdict 指向 sys.__dict__;
p320: 系統module 的初始化
在 Python 中,module 通過 PyModuleObject 物件來實現。
C++ Code|
1 2 3 4 |
typedef struct { PyObject_HEAD PyObject *md_dict; } PyModuleObject; |
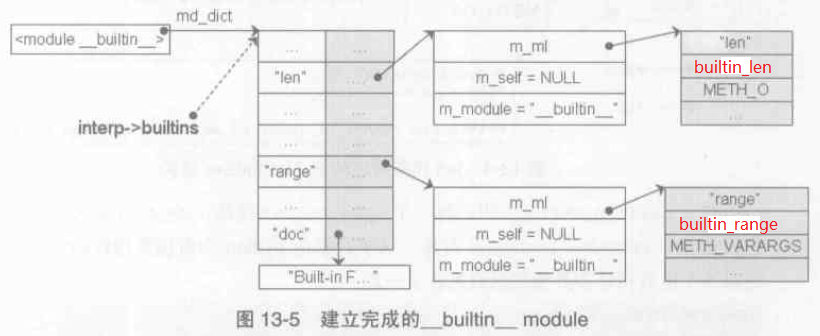
在初始化 __builtin__ 模組時,需要將Python 的內建型別物件塞到 md_dict 中,此外內建函式也需要新增。
如 __builtins__.__dict__['int'] 顯示為 <type 'int'>; __builtins__.__dict__['dir] 顯示為<built-in function dir>;
系統的 __builtin__ 模組的 name為 '__builtin__ ', 即 __builtins__.__dict__['__name__'] 顯示為 '__builtin__ ';
__builtins__.__dict__['__doc__'] 顯示為 "Built-in functions, exceptions, .... ";
也可直接 __builtins__.__name__ , __builtins__.__doc__;
這裡解釋下為什麼會出現 '__builtins__'。我們經常做單元測試使用的機制 if __name__ == '__main__' ,表明作為主程式執行的Python 原始檔可以被視為名為 __main__ 的 module,當然以 import py 方式載入,則__name__ 不會為 __main__。在初始化 __main__ module 時會將('__builtins__', __builtin__ module)插入到其 dict 中。也就是說
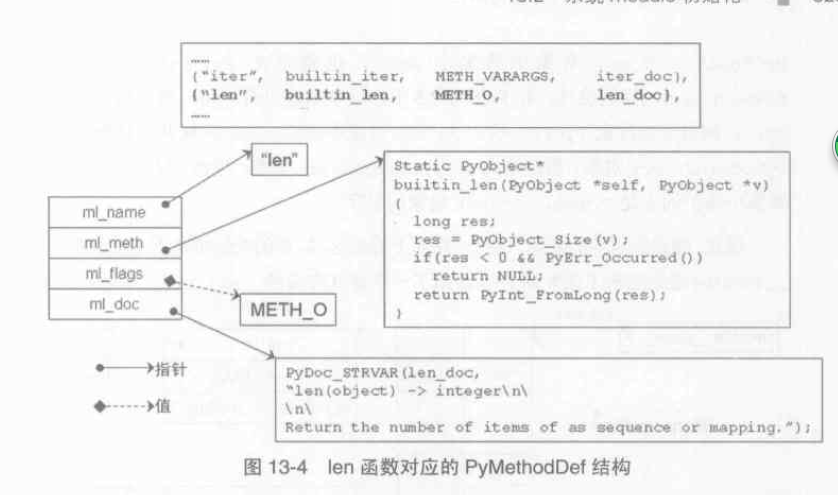
builtin_methods 中每一個函式對應一個 PyMethodDef 結構,會基於它建立一個 PyCFunctionObject 物件,這個物件是Python 對函式指標的包裝。
C++ Code|
1 2 3 4 5 6 7 |
struct PyMethodDef { const char *ml_name; /* The name of the built-in function/method */ PyCFunction ml_meth; /* The C function that implements it */ int ml_flags; /* Combination of METH_xxx flags, which mostly describe the args expected by the C func */ const char *ml_doc; /* The __doc__ attribute, or NULL */ }; |
|
1 2 3 4 5 6 |
typedef struct { PyObject_HEAD PyMethodDef *m_ml; /* Description of the C function to call */ PyObject *m_self; /* Passed as 'self' arg to the C func, can be NULL */ PyObject *m_module; /* The __module__ attribute, can be anything */ } PyCFunctionObject; |
__builtin__ module 初始化完成後如下圖:
在完成了__builtin__ 和 sys 兩個模組的設定之後,記憶體佈局如下圖:
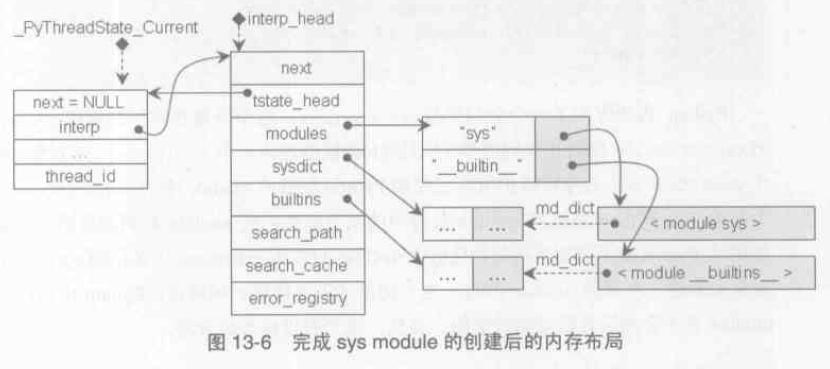
Python 內部維護了一個全部變數extensions,這個PyDictObject 物件將維護所有已經被Python 載入的module 中的
PyDictObject 的一個備份。當Python 系統的 module 集合中的某個標準擴充套件module 被刪除後不久又被重新載入時,Python 就不需要再次初始化這些module,只需要用extensions 中備份的 PyDictObject 物件來建立一個新的module 即可。這一切基於假設:Python 中的標準擴充套件module 是不會在執行時動態改變的。實際上Python 內部提供的module 可以分成兩類,一類是C 實現的builtin module 如thread,一類是用python 實現的標準庫module。
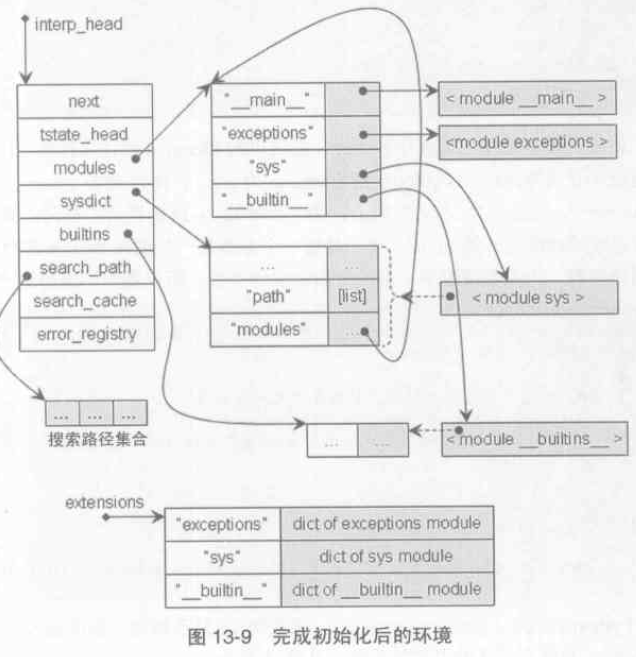
p328:設定搜尋路徑、site-specific 的 module 搜尋路徑
sys.path 即 sys.__dict__['path'] 是一個 PyListObject 物件,包含了一組PyStringObject 物件,每一個物件是一個module 的搜尋路徑。
第三方庫路徑的新增是 lib/site.py 完成的,在site.py 中完成兩個動作:
1. 將 site-packages 路徑加入到 sys.path 中。
2. 處理 site-packages 目錄下所有.pth 檔案中儲存的所有路徑加入到 sys.path。
完成初始化後的環境如下圖所示:
p347: import 機制的黑盒探測
Python Code|
1 2 3 |
# hello.py a = 1 b = 2 |


也就是說,hello module 中的 __builtins__ 符號對應的 dict 正是當前名字空間中 __builtins__ 符號對應的module物件所維護的那個dict 物件。
注意 from hello import a 的情況有所不同:

注意 from hello import * ,如果 hello.py 定義了__all__ = [ ... ],那麼只加載列表裡面的符號;當然如果在 __init__.py 定義了 __all__,那麼只加載列表中的 module。類似地,import A.tank as Tank 在locals() 中出現的名字是 'Tank',但還是需要通過 sys.modules['A.tank'] 才能正確訪問。
注意:不要從其他模組 import 初始值為None, 而後值一直被修改的符號,此時應該使用函式等方式來傳遞此符號。因為當前模組中此符號所引用的值可能一直都是None,這取決於初始化順序。
如果出現了巢狀import 的情況呢?
Python Code|
1 2 3 4 5 |
# usermodule1.py import usermodule2 # usermodule2.py import sys |

也就是說在每個py 中進行的import 動作並不會影響上一層的名字空間,只是影響各個module 自身的名字空間;但所有import 動作,無論發生在什麼時間、什麼地點,都會影響到全域性module 集合即 sys.modules。圖中的 __file__ 是檔案路徑名。
注意:儘量避免相互引用,這是模組化開發的一條準則。
實際上“動態載入”真實含義是將這個module 以某個符號的形式引入到某個名字空間,del xxx 只是刪除了符號,而sys.modules 中仍然維護了xxx 對應的module 物件。如果我們更新了module A 的某個功能實現,可以使用 reload 來更新 sys.modules 中維護的module A 物件,注意:Python 虛擬機器在呼叫reload() 操作更新module 時,只是將新的符號加入到module 中,而不管module 中的先前符號是否已經在原始檔中被刪除了。
只有在資料夾中有一個特殊的 __init__.py 檔案,Python 虛擬機器才會認為這是一個合法的package,當Python 虛擬機器執行 import A 時,會動態載入目錄A 的 __init__.py,除非 __init__.py 中有顯式的import 語句,否則只會將package 自身載入到Python,並不會對package 中的module 進行任何動作。
在載入package 下的module 時,比如 A.B.C(多層路徑),Python 內部將這個module 的表示視為一個樹狀的結構。如果 A 在import A.D 時被載入了,那麼在 A 對應的PyModuleObject 物件中的dict 中維護著一個 __path__,表示這個 package 的搜尋路徑,那麼接下來對B 的搜尋將只在 A.__path__ 中進行,而不在所有Python 搜尋路徑中執行了(直接 import module 時)。
p362: import 機制的實現
Python Code|
1 2 3 4 5 6 7 |
import sys import xml.sax # xml/sax.py from xml import sax from xml.sax import xmlreader from sys import path from sys import path as mypath import usermodule |
如上舉例說明 " from A import mod",儘管 mod 並不在 A 對應的module 物件的名字空間中,但是import 機制能夠根據 A 發現 mod,也是合法的。
Python import 機制的起點是builtin module 的 __import__ 操作,也就是 builtin__import__ 函式。
Python 將尋找一切可以作為module的檔案,比如subname 來說,Python 將尋找 subname.py、subname.pyc、subname.pyd、subname.pyo、subname.dll(Python 2.5 已不再執行dll 字尾名的檔案)。
對於py 檔案,Python 虛擬機器會先對py 檔案進行編譯產生PyCodeObject 物件,然後執行了co_code 位元組碼,即通過執行def、class 等語句建立PyFunctionObject、PyClassObject 等物件,最後得到一個從符號對映到物件的dict,自然也就是所建立的module 物件中維護的那個dict。
import 建立的module 都會被放到全域性module 集合 sys.module 中。
p386: 與 module 有關的名字空間問題
Python Code|
1 2 3 4 5 6 7 8 9 10 11 |
# module1.py import module2 owner = "module1" module2.show_owner() # "module2" # module2.py owner = "module2" def show_owner(): print owner |
在執行 import module2 時,Python 會建立一個新的PyFrameObject 物件,剛開始這個物件中的global 名字空間可能只有 '__builtins__'
、'__doc__'、'__name__' 等符號,隨著程式碼的執行,global名字空間會增加 'owner' 和'show_owner',並且'show_owner' 對應的PyFunctionObject 對
象中的 func_globals 儲存了當前 global名字空間的所有符號。在 module1.py 中執行完 owner = "module1" 後, module1的global 名字空間大概是
{..., 'owner' : 'module1', 'module2': <module 'module2...'>},在執行 module2.show_owner() 時,首先要獲得符號'show_owner' :
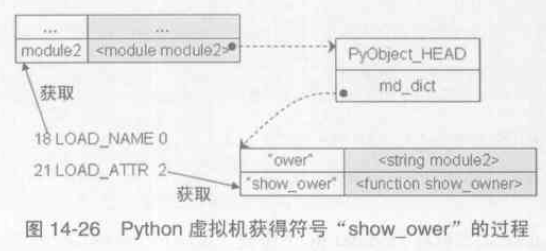
執行函式需要建立一個PyFrameObject 物件,根據筆記(1)的條目p226所說,PyFrame_New(tstate, co, globals, NULL) 中的
global 引數是來自 PyFunctionObject.func_globals,故根據LEGB原則,print owner 輸出的是'module2' 。
p392: Python 的執行緒在GIL(global interpreter lock) 的控制之下,執行緒之間,對整個Python 直譯器(虛擬機器),對Python 提供的 C API 的訪問,都是互斥的,這可以看作是 Python 核心級的互斥機制。Python 內部維護一個數值N(sys.getcheckinterval() ),模擬內部的“軟體中斷”,當執行了某個執行緒的N 條指令之後應該立刻啟動執行緒排程機制,因為 Python 中的執行緒實際上就是作業系統所支援的原生執行緒,故下一個被排程執行的執行緒由作業系統來選擇。
p394: Python 執行緒的建立
threadmodule.c 提供的函式介面很少,定義在 static PyMethodDef thread_methods[] = { ...};
Python 虛擬機器通過三個主要的動作,完成一個執行緒的建立:
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//threadmodule.c // thread.start_new_thread 對應的 c 實現函式 static PyObject * thread_PyThread_start_new_thread(PyObject *self, PyObject *fargs) { ... boot = PyMem_NEW(struct bootstate, 1); // 1) ... PyEval_InitThreads(); /* Start the interpreter's thread-awareness */ // 2) ... ident = PyThread_start_new_thread(t_bootstrap, (void *) boot); // 3) ... return indent; } |
1). 建立並初始化bootstate 結構,儲存執行緒的函式、函式引數等。
C++ Code|
1 2 3 4 5 6 7 |
struct bootstate { PyInterpreterState *interp; PyObject *func; PyObject *args; PyObject *keyw; }; |
2). 初始化Python 的多執行緒環境。
當Python 啟動時是不支援多執行緒的(執行緒的排程需要代價),一旦使用者呼叫 thread.start_new_thread,Python 意識到使用者需要多執行緒的支援,自動建立多執行緒機制需要的資料結構、環境以及重要的GIL 等。
C++ Code|
1 2 3 4 5 6 |
// pythread.h typedef void *PyThread_type_lock; // ceval.c static PyThread_type_lock interpreter_lock = 0; /* This is the GIL */ static long main_thread = 0; |
如上定義可以看到實際上 GIL 就是一個 void* 指標,無論建立多少個執行緒,初始化只進行一次。
Python 多執行緒機制具有平臺相關性,在Python/Python 目錄下有一批 thread_***.h 的標頭檔案,包裝了不同作業系統的原生執行緒,並通過統一的介面暴露給 Python,比如thread_nt.h 包裝的是win32 平臺的原生 thread,interpreter_lock 就是指向瞭如下的 NRMUTEX 結構。
C++ Code|
1 2 3 4 5 6 7 |
//thread_nt.h typedef struct NRMUTEX { LONG owned ; DWORD thread_id ; HANDLE hevent ; } NRMUTEX, *PNRMUTEX ; |
當初始化環境完畢之後主執行緒(執行python.exe 時作業系統建立的執行緒)首先獲得 GIL 控制權。
3). 以bootstate 為引數建立作業系統的原生執行緒。
在 PyThread_start_new_thread 中首先將t_bootstrap 和 boot 打包到一個型別為 callobj 的結構體obj 中,如下所示:
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 |
long PyThread_start_new_thread(void (*func)(void *), void *arg) { callobj obj; obj.done = CreateSemaphore(NULL, 0, 1, NULL); ... rv = _beginthread(bootstrap, _pythread_stacksize, &obj); /* wait for thread to initialize, so we can get its id */ WaitForSingleObject(obj.done, INFINITE); // 掛起 return obj.id; } |
|
1 2 3 4 5 6 |
typedef struct { void (*func)(void*); void *arg; long id; HANDLE done; } callobj; |

當完成打包之後,呼叫 win32 下建立thread的api:_beginthread 來完成執行緒的建立,函式返回後主執行緒會掛起等待obj.done 這個Semaphore核心物件,子執行緒開始執行bootstrap ,在其中完成3個動作:1). 獲取執行緒id; 2). 通知obj.done 核心物件; 3). 呼叫 t_bootstrap;
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 |
static int bootstrap(void *call) { callobj *obj = (callobj*)call; /* copy callobj since other thread might free it before we're done */ void (*func)(void*) = obj->func; void *arg = obj->arg; obj->id = PyThread_get_thread_ident(); ReleaseSemaphore(obj->done, 1, NULL); func(arg); return 0; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
static void t_bootstrap(void *boot_raw) { struct bootstate *boot = (struct bootstate *) boot_raw; PyThreadState *tstate; PyObject *res; tstate = PyThreadState_New(boot->interp); PyEval_AcquireThread(tstate); // 申請GIL res = PyEval_CallObjectWithKeywords( boot->func, boot->args, boot->keyw); // 最終呼叫 PyEval_EvalFrameEx ... PyMem_DEL(boot_raw); PyThreadState_Clear(tstate); PyThreadState_DeleteCurrent(); // 釋放 GIL PyThread_exit_thread(); } |
可以認為到此時子執行緒的初始化才算真正完成,子執行緒和主執行緒一樣,都完全被Python 執行緒排程機制所控制了。需要注意的是:當所有執行緒都完成了初始化之後,作業系統的執行緒排程是與Python 的執行緒排程統一的(Python 執行緒排程--> GIL --> Event 核心物件 --> 作業系統排程),但在初始化完成之前,它們之間並沒有因果關係。
我們知道作業系統在進行程序切換時需要儲存or 恢復上下文環境,Python 在進行執行緒切換時也需要將執行緒狀態儲存在 PyThreadState 物件,前面說過,_PyThreadState_Current 這個全域性變數一直指向當前被啟用的執行緒對應的 PyThreadState 物件。Python 內部維護了一個單向連結串列來管理所有Python 執行緒的狀態物件,對於這個連結串列的訪問有一個獨立的鎖而不必在GIL 保護下進行,此鎖的建立在Python 進行初始化時完成。
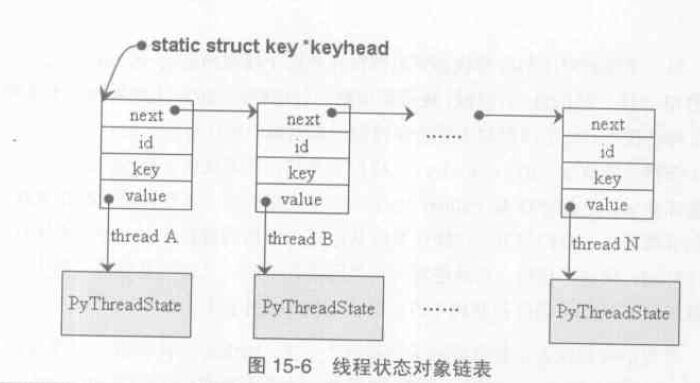
其中 id 是指執行緒id,如果value 都是指向 PyThreadState 物件,那麼它們的 key 值都一致。
p413: Python 執行緒的排程
Python 的執行緒排程機制是內建在 Python 的直譯器核心 PyEval_EvalFrameEx 中的。除了標準的計數排程外,還存在另一種阻塞排程,即線上程 A通過某種操作比如等待輸入或者睡眠等,將自身阻塞後,Python 應該將等待GIL 的執行緒B 喚醒,當然 A 在掛起前肯定需要釋放 GIL。
比如 time.sleep(1) 大概是這樣實現的: { Py_BEGIN_ALLOW_THREADS(釋放GIL) sleep(1); Py_END_ALLOW_THREADS(申請GIL) }
即通過兩個巨集來實現阻塞排程,注意阻塞排程則不會重置 PyEval_EvalFrameEx 內的 _Py_Ticker 為 初始值 _Py_CheckInterval。
注:python中 thread 的一些機制和C/C++不同:在C/C++中,主執行緒結束後,其子執行緒會預設被主執行緒kill 掉。而在python中,主執行緒結束後,預設會等待子執行緒結束後,主執行緒才退出。The entire Python program exits when no alive non-daemon threads are left.
python 對於 thread 的管理中有兩個函式:join 和 setDaemon
join:如在一個執行緒B中呼叫threadA.join(),則 threadA 結束後,執行緒B才會接著 threadA.join() 往後執行。
setDaemon:主執行緒A 啟動了子執行緒B,呼叫B.setDaemaon(True),則主執行緒結束時,會把子執行緒B也殺死,與C/C++ 中的預設效果是一樣的。
p420: Python 執行緒的使用者級互斥與同步
核心級通過 GIL 實現的互斥保護了核心的共享資源,同樣使用者級互斥保護了使用者程式中的共享資源。
使用者級的鎖是用 lockobject 實現的,與GIL 一樣, lock_lock 也指向一個win32 下的 Event 核心物件。
C++ Code|
1 2 3 4 |
typedef struct { PyObject_HEAD PyThread_type_lock lock_lock; } lockobject; |
lockobject 物件提供的屬性操作定義在 static PyMethodDef lock_methods[] = { ... }; 需要注意的是當鎖不可用時 lockobject.acquire 操作也是一個阻塞操作,故大概是這樣實現的: { Py_BEGIN_ALLOW_THREADS(釋放GIL) PyThread_acquire_lock(); Py_END_ALLOW_THREADS(申請GIL) }
這是由於執行緒需要等待一個 lock 資源,為了避免死鎖,需要將 GIL 轉交給 其他的等待 GIL 的執行緒,然後呼叫 PyThread_acquire_lock 開始嘗試獲得
使用者級鎖,在獲得使用者級鎖之後,再嘗試獲得核心級lock--GIL。
p430:Python 的記憶體管理機制

layer 0 即作業系統提供的malloc or free 等介面;layer 1 是Python 基於第0 層包裝而成,沒有加入太多動作,只是為了處理與平臺相關的記憶體分配行為而提供統一的介面; layer 2 主要提供建立Python 物件的介面,這一套函式族又被稱為 Pymalloc 機制;layer 3 主要是常用物件如整數、字串等的緩衝池機制。真正需要分析的是 layer 2 的實現,也是 GC(garbage collector) 的藏身之處。
p432: 小塊空間的記憶體池
在Python 2.5 中,整個小塊記憶體的記憶體池可以視為一個層次結構,在這個層次結構中,一共分為4層,從上至下為:block、pool、arena 和 記憶體池。
前三個都是可以在原始碼中找到的實體,而 “記憶體池” 只是一個概念上的東西,表示Python 對整個小塊記憶體分配和釋放行為的記憶體管理機制。
在最底層,block 是一個確定大小的記憶體塊(8, 16, 24, ...., 256),大小超過256位元組的記憶體申請轉交給layer 1 PyMem 函式族處理。
一個pool 管理一堆具有固定大小的記憶體塊,一個pool 大小通常為一個系統記憶體頁4KB。
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/* When you say memory, my mind reasons in terms of (pointers to) blocks */ typedef uchar block; /* Pool for small blocks. */ struct pool_header { union { block *_padding; uint count; } ref; /* number of allocated blocks */ block *freeblock; /* pool's free list head */ struct pool_header *nextpool; /* next pool of this size class */ struct pool_header *prevpool; /* previous pool "" */ uint arenaindex; /* index into arenas of base adr */ uint szidx; /* block size class index */ uint nextoffset; /* bytes to virgin block */ uint maxnextoffset; /* largest valid nextoffset */ }; |
一塊經過改造的 4KB 記憶體如下圖:
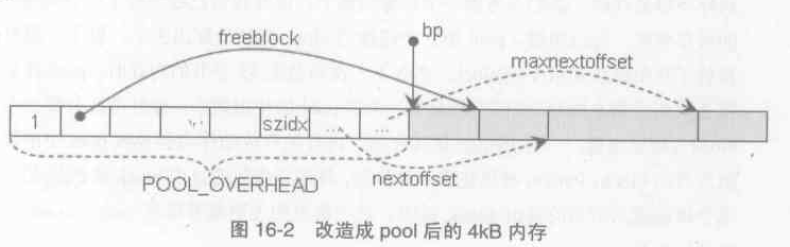
其中實線箭頭是指標,但虛線箭頭只是偏移位置的形象表示。
ref.count 表示已經被分配的block 數量,此時為1。bp 返回的是一個可用地址,實際後面的記憶體都是可用的,但可以肯定申請記憶體的函式只會使用[bp, bp+size] 區間的記憶體,比如申請 25~32 位元組大小的記憶體,會返回一個 32位元組 block 的地址。
szidx 表示 size class index,比如 szidx=3 表示pool 管理的是 32位元組的block 集合。在 pool header 中,nextoffset 和 maxoffset 是兩個用於對pool 中的block 集合進行迭代的變數,如初始化時:
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* * Initialize the pool header, set up the free list to * contain just the second block, and return the first * block. */ pool->szidx = size; size = INDEX2SIZE(size); // 由szidx 轉換成 size bp = (block *)pool + POOL_OVERHEAD; pool->nextoffset = POOL_OVERHEAD + (size << 1); // POOL_OVERHEAD + 2*size pool->maxnextoffset = POOL_SIZE - size; pool->freeblock = bp + size; *(block **)(pool->freeblock) = NULL; return (void *)bp; |
freeblock 指向下一個可用 的block 地址,而nextoffset 是下下可用block 距離頭部的偏移,故再次分配block 時,只需將freeblock 返回,並將其移動 nextoffset 的距離,同樣地 nextoffset 值加上2個size 距離,即如下程式碼 2)處所示。
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* * There is a used pool for this size class. * Pick up the head block of its free list. */ ++pool->ref.count; bp = pool->freeblock; assert(bp != NULL); if ((pool->freeblock = *(block **)bp) != NULL) // 1) { return (void *)bp; } /* * Reached the end of the free list, try to extend it. */ if (pool->nextoffset <= pool->maxnextoffset) // 2) { /* There is room for another block. */ pool->freeblock = (block *)pool + pool->nextoffset; pool->nextoffset += INDEX2SIZE(size); *(block **)(pool->freeblock) = NULL; return (void *)bp; } |
現在考慮一種情況,假設pool 中5個連續的block 都被分配出去了,過一段時間釋放了塊2 和塊4,那麼下一次申請32位元組記憶體,pool 返回的是第2塊還是第6塊呢?出於使用效率顯然是第2塊,具體實現是在 free block 時做的手腳,將一些離散的資源block 組織起來成為自由block 連結串列,而freeblock 則是這個連結串列的表頭,如下程式碼所示:
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
pool = POOL_ADDR(p); // p 是 PyObject_Free 的引數 if (Py_ADDRESS_IN_RANGE(p, pool)) { /* We allocated this address. */ /* Link p to the start of the pool's freeblock list. Since * the pool had at least the p block outstanding, the pool * wasn't empty (so it's already in a usedpools[] list, or * was full and is in no list -- it's not in the freeblocks * list in any case). */ assert(pool->ref.count > 0); /* else it was empty */ *(block **)p = lastfree = pool->freeblock; pool->freeblock = (block *)p; ... } |
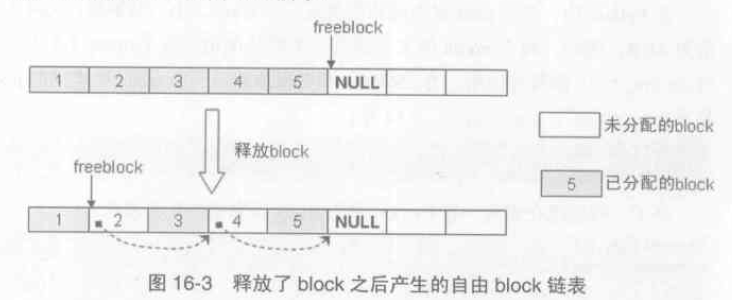
回到前面分析的block 分配行為,可以知道如果有先前釋放的block 則直接返回如1)處程式碼所示,沒有再進行2)處程式碼判斷,在2)處還需指出一點即 maxoffset 是該pool 最後一個可用block 距離pool header 的偏移,故如果
nextoffset > maxnextoffset 則此pool 已經無block 可用了,可以考慮再申請一個pool 了。
一個area 大小是256KB,可以容納 64個pool,這些pools 可能並不屬於同一個 class size index 。pool_header 管理的記憶體與pool_header 自身是一塊連續的記憶體,而 arena_object 與其管理的記憶體是分離的,也就是說當arena_object 被申請時,它所管理的pool 集合的記憶體還沒被申請,下面是 arena_object 的定義,每個條目註釋都寫得非常清楚,我就不狗尾續貂解釋了。
C++ Code|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// obmalloc.c #define ARENA_SIZE (256 << 10) /* 256KB */ /* Record keeping for arenas. */ struct arena_object { /* The address of the arena, as returned by malloc. Note that 0 * will never be returned by a successful malloc, and is used * here to mark an arena_object that doesn't correspond to an * allocated arena. */ uptr address; /* Pool-aligned pointer to the next pool to be carved off. */ block *pool_address; /* The number of available pools in the arena: free pools + never- * allocated pools. */ uint nfreepools; /* The total number of pools in the arena, whether or not available. */ uint ntotalpools; /* Singly-linked list of available pools. */ struct pool_header *freepools; /* Whenever this arena_object is not associated with an allocated * arena, the nextarena member is used to link all |