
一個對前端模板技術的全面總結
此文緣由
其實從釋出regularjs之後,我發現在google搜尋regularjs 不是給我這個畫面
就是給我這個畫面
突然發現取名字真是個大學問,當時就基本預計到了會有不明真相的朋友認為它只是一個照搬angularjs的傢伙,對於這點,有興趣的朋友可以看下【為什麼要造Regularjs這個輪子】。
而在這個文章,我不會直截了當去與angular做直接的對比,而是從最基本原理開始對現有的模板解決方案進行一個全面的分類,同時會給出它們的一些或優或劣的特性,這些特性基本都是本質性的,即它不為維護者的水平高低和勤勉與否所限制,所以是具有客觀性的。
什麼是模板解決方案?
你可以先簡單的理解為模板引擎。
事實上前端的模板解決方案已經從 “選出一個好用的模板好難” 發展到了 “從這麼多模板中選一個好難的”的階段,Template-Engine-Chooser!似乎也開始無法跟上節奏了。再加上目前Dom-based的模板技術的崛起(angularjs, knockout等),漸漸讓這個領域有亂花漸欲迷人眼的感覺。
這篇文章會對當今前端界的三種截然不同的模板方案做一個全面的對比,它們分別是
- String-based 模板技術 (基於字串的parse和compile過程)
- Dom-based 模板技術 (基於Dom的link或compile過程)
- 雜交的Living templating 技術 (基於字串的parse 和 基於dom的compile過程)
同種型別的模板技術的可能性都是相同的,即同樣身為dom-based的vuejs如果願意可以發展為angularjs的相同功能層級。
(注: 其實這麼說作者後續思考後覺得並不是很妥當,因為決定這類框架的還有重要一環就是它們的資料管理層:,比如是基於髒檢查還是基於setter和getter,就會有截然不同的定位)
另外需要注意的是任何一種型別的模板技術都是不可被替代的,它們甚至可以結合使用,並且很長一段時間內還會繼續共存下去。
除此之外另外一種奇葩模板技術本文也會提到即react,瞭解後你會發現它的特性更接近於Living templating。
在進入介紹之前,我們需要先過一下不得不說的 InnerHTML,它是本文的關鍵因素。
innerHTML
我不認為還需要從innerHTML的細節講起,我們對它太熟悉了,那就直接從優劣開始講吧!
innerHTML 毫無疑問是好的
在innerHTML正是成為 web
標準 前,它當之無愧的已經是大家公認的事實標準,這是因為:
1 . 它便於書寫並且直觀
想象下你必須新增如下的html到你的文件裡
<h2 title="header">title</h2>
<p>content</p>
直接使用 innerHTML
node.innerHTML = "<h2 title="header">title</h2><p>content</p>"
在對比使用Dom
API
var header = document.createElement('h2');
var content = document.createElement('p');
h2.setAttribute('title', 'header');
h2.textContent = 'title';
p.textContent = 'content';
node.appendChild(header);
node.appendChild(content);
innerHTML 毫無疑問贏得了這張比賽.
儘管部分框架例如mootools:Element 提供了高效的API來幫助你建立dom結構,innerHTML仍然會是大多數人的最佳選擇
2 . 它很快,特別在old IE
隨著瀏覽器的發展,這個測試可能越來越不符合實際,
innerHTML和Dom Level 1建立dom結構的差距正變得原來越小
3. 它完成進行了String -> Dom的轉換
這個論點有點拗口,事實上後續要提到的兩類模板技術都是因為這個特點而與其有了強依賴
然而我們又清楚的被告知:
The recommended way to modify the DOM is to use the DOM Level 1 API. ——Chapter 15 of "Javascript: The Definitive Guide_"
為什麼?
innerHTML 有時候又是不聽話的
1. 安全問題
innerHTML 具有安全隱患.,例如:
document.body.innerHTML = "<img src=x onerror='alert(xss)'/>"我知道像你這樣優秀的程式設計師不會寫出這樣的程式碼,但當html片段不完全由你來控制時(比如從遠端伺服器中),這會成為一個可能引爆的炸彈。
2. 它很慢
等等,你剛才說了它很快! 是的,但是如果你僅僅為了替換一個屬性而用innerHTML替換了所有的Dom節點,這顯然不是一個明智的決定,因為你深知這是低效的。所以說:
Context is everything
所有離開背景談的效能、功能、性功能都是偽科學
3. 它很笨
它會完全移除所有現有的Dom,並重新渲染一遍,包括事件和狀態都以不復存在,這點利用innerHTML來進行render的框架(例如Backbone)的開發者應該深有體會,為了減少損失,不能不把View拆的越來越細,從而抱著看似“解耦完美”的架構體系進入了維護的深淵。
注: 其實react的最大貢獻就是它差不多是提供了一個更smart的innerHTML解決方案。
4. 有可能會創建出意料之外的節點.
由於html的parser非常的“友好”, 以至於它接受並不規範的寫法,從而創建出意料之外的結構,而開發者得不到錯誤提示。
好了,到現在為止,我們大概瞭解了innerHTML這個朝夕相處的小夥伴,接下來我們正式聊一聊模板技術,首先我們從最常見的“String-based
templating”開始
String-based templating
基於字串的模板引擎最大的功勞就是把你從大量的夾帶邏輯的字串拼接中解放出來了,由於它的完全基於字串的特性,它擁有一些無可替代的優勢。
It is essentially a way to address the need to populate an HTML view with data in a better way than having to write a big, ugly string concatenation expression. --- cited from http://www.dehats.com/drupal/?q=node/107
示例
基本原理
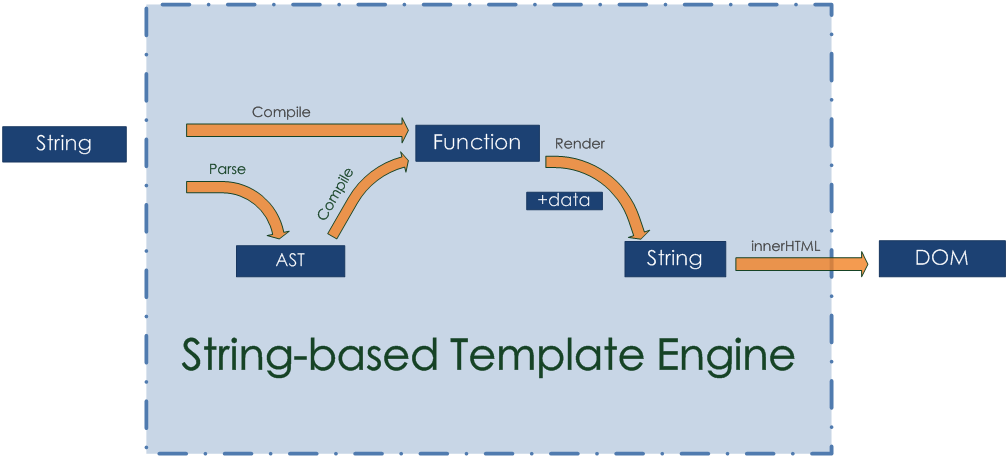
如上圖所示,我們發現字串模板強依賴於innerHTML(渲染),
因為它的輸出物就是字串。由於這篇文章的重點不在這裡,我們不會再對它們如何使用作深究。
優點
- 快速的初始化時間: 很多angular的簇擁者在奚落String-based templating似乎遺漏了這一點。
- 同構性: 完全的dom-independent,即可作為用伺服器端和瀏覽器端(客官先不要急著搬phantomjs哈).
- 更強大的語法支援:因為它們都是不是自建DSL就是基於JavaScript語法,Parser的靈活性與受限於HTML的Dom-based模板技術不可同日而語
缺點
- 安全隱患: 見
innerHTML - 效能問題:見
innerHTML. - 不夠聰明: 見
innerHTML(呵呵),除此之外render之後資料即與view完全分離。
儘管在這幾年的發展之下,由於異常激烈的競爭,基於字串的前端模板技術變得越來越快,但是它們顯然大部分都遺漏了一些問題
- 大俠們你們沒有考慮進把輸出字串載入到Dom的時間,這才是真正瓶頸之一
- 不在相同功能前提下的對比有意義麼?
Dom-based Template Engine
近幾年,藉著Angularjs的東風,Dom-based的模板技術開始大行其道,與此同時也出現了一些優秀的替代者,就我們國人而言,近的就有@尤小右的Vuejs 和 司徒大大的avalonjs。看倉庫就可以發現風格也是完全不同:1) 一個簡潔優雅 2)一個奔放不羈
示例
- Angularjs: 都28000star了還需多說麼
- Knockout: 在此領域內,對Web前端而言是鼻祖級的
大致流程
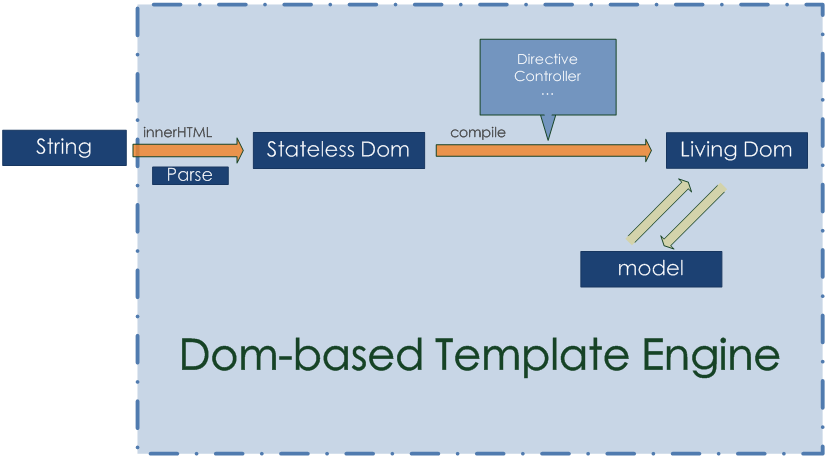
Dom-based的模板技術事實上並沒有完整的parse的過程(先拋開表示式不說),如果你需要從一段字串創建出一個view,你必然通過innerHTML來獲得初始Dom結構.
然後引擎會利用Dom
API(attributes, getAttribute, firstChild…
etc)層級的從這個原始Dom的屬性中提取指令、事件等資訊,繼而完成資料與View的繫結,使其”活動化”。
所以Dom-based的模板技術更像是一個數據與dom之間的“連結”和*“改寫”*過程。
注意,dom-based的模板技術不一定要使用innerHTML,比如所有模板都是寫在入口頁面中時,
但是此時parse過程仍然是瀏覽器所為。
優點
- 是活動的: 完成compile之後,data與View仍然保持聯絡,即你可以不依賴與手動操作
Dom API來更新View - 是執行時高效的: 可以實現區域性更新
- 指令等強大的附屬物幫助我們用宣告式的方式開發APP
缺點
- 部分請見innerHTML
- 沒有獨立的Parser,必須通過innerHTML(或首屏)獲取初始節點,即它的語法是強依賴與HTML,這也導致它有潛在的安全問題
- 資訊承載於屬性中,這個其實是不必要和冗餘的。 部分框架在讀取屬性後會通過諸如
removeAttribute的方式移除它們,其實這個不一定必要,而且其實並無解決它們Dom強依賴的特性,比如如果你檢視[angular的todomvc]的節點,你會發現它的輸出是這樣的: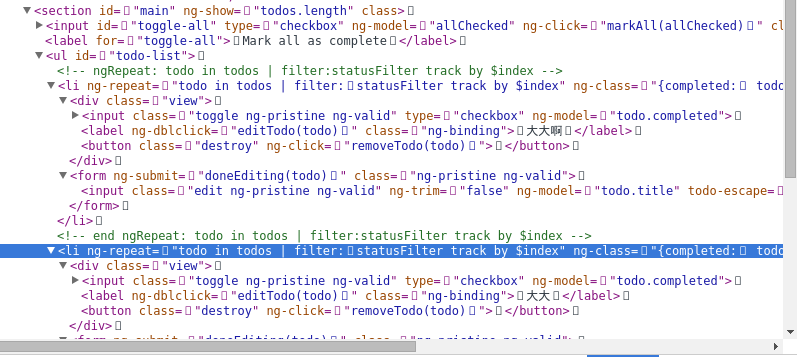
- FOUC(Flash of unstyled content):即內容閃動,這個無需多說了,只怪它初次進入dom的內容並不是最終想要的內容。
Living Template Engine
String-based 和 Dom-based的模板技術都或多或少的依賴與innerHTML,
它們的區別是一個是主要是為了Rendering 一個是為了 Parsing 提取資訊
所以為什麼不結合它們兩者來完全移除對
innerHTML的依賴呢?
事實上,值得慶幸的是,已經有幾個現例項子在這麼做了。
例子
基本原理
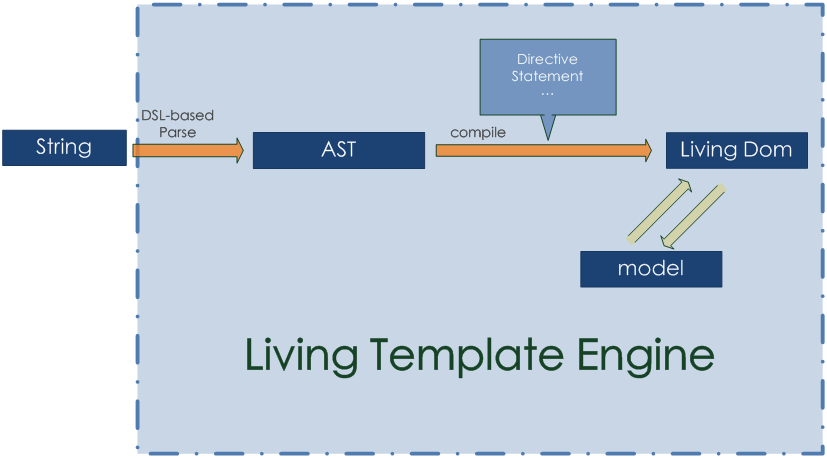
就如圖中所示,parse和compile的過程分別類似於String-based 模板技術 和 Dom-based模板技術。
下面來完整講述下這兩個過程
1 . Parsing
首先我們使用一個內建DSL來解析模板字串並輸出AST。
例如,在regularjs中,下面這段簡單的模板字串
<button {{#if !isLogin}} on-click={{this.login()}} {{/if}}>
{{isLogin? 'Login': 'Wellcome'}}
</button>'會被解析為以下這段資料結構
[
{
"type": "element",
"tag": "button",
"attrs": [
{
"type": "if",
"test": {
"type": "expression",
"body": "(!_d_['isLogin'])",
"constant": false,
"setbody": false
},
"consequent": [
[
{
"type": "attribute",
"name": "on-click",
"value": {
"type": "expression",
"body": "_c_['login']()",
"constant": false,
"setbody": false
}
}
]
],
"alternate": []
}
],
"children": [
{
"type": "expression",
"body": "_d_['isLogin']?'Login':'Wellcome'",
"constant": false,
"setbody": false
}
]
}
]
這個過程有以下特點
- 靈活強大的語法,因為它與基於字串的模板一般,DSL是自治的,完全不依賴與html,你可以想像下dom-based的模板的那些語法相關的指令,事實上它們甚至無法表達上述那段簡單的模板的邏輯。
- Living模板技術需要同時處理
dsl元素與xml元素來實現最終檢視層的活動性,即它們是dom-aware的,而在字串模板中其實xml元素完全可以無需關心,它們被統一視為文字元素。
2 Compiler
結合特定的資料模型(在regularjs中,是一個裸資料), 模板引擎層級遊歷AST並遞迴生成Dom節點(不會涉及到innerHTML).
與此同時,指令、事件和插值等binder也同時完成了繫結,使得最終產生的Dom是與Model相維繫的,即是活動的.
事實上,Living template的compile過程相對與Dom-based的模板技術更加純粹, 因為它完全的依照AST生成,而不是在原Dom上的改寫。
以上面的模板程式碼的一個插值為例:{{isLogin?
'Login':
'Wellcome'}}。一旦regularjs的引擎遇到這段模板與代表的語法元素節點,會進入如下函式處理