
《Hadoop進階》利用Hadoop構建豆瓣圖書推薦系統
轉載請註明出處: 轉載自 Thinkgamer的CSDN部落格:blog.csdn.net/gamer_gyt
程式碼下載地址:點選檢視
1:推薦系統概述
2:需求分析:推薦系統的指標設計
3:演算法模型:基於物品的協同過濾並行演算法設計
4:架構設計:推薦系統架構
5:程式實現:MR2V程式實現
6:推薦系統評估
一、推薦系統概述
推薦系統廣泛存在與各大網站上,比如說亞馬遜,淘寶等電商類網站上,而且在社交網路上也應用的十分廣泛,比如說facebook的你可能認識,微博的好友推薦,也比如說csdn部落格的你可能喜歡等等。
這是我目前在做的一個豆瓣圖書推薦系統,採用的演算法主要是協同過濾演算法,使用Python+Django+Mysql進行部署
github地址:點選檢視
推薦演算法的分類主要包括:
按資料使用劃分:
- 協同過濾演算法:UserCF, ItemCF, ModelCF
- 基於內容的推薦: 使用者內容屬性和物品內容屬性
- 社會化過濾:基於使用者的社會網路關係
按模型劃分:
- 最近鄰模型:基於距離的協同過濾演算法
- Latent Factor Mode(SVD):基於矩陣分解的模型
- Graph:圖模型,社會網路圖模型
裡邊詳細介紹了基於使用者的協同過濾演算法和基於Item的協同過濾演算法,以及他們的python實現版本,在這裡就不過多進行論述
二、需求分析:豆瓣圖書推薦系統指標設計
推薦系統是為了更精準的為使用者推薦他們想要的內容,如果一個使用者在瀏覽圖書資訊的時候,通過對使用者資料的記錄,和已經存在的其他的使用者記錄進行分析,從而為使用者推薦相應的資料
資料集來源為,豆瓣圖書,採用python爬蟲指令碼爬取相應的資訊如下(以下資訊為我預處理之後存入Mysql資料庫的規整資訊)
user對book的打分表:
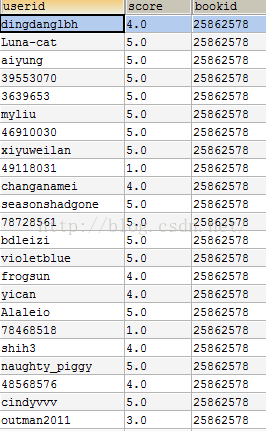
這裡我採用的是基於Item的協同過濾演算法,通過評分來計算使用者可能對書本的評分,過濾掉使用者已經看過的,選擇剩餘的TopK推薦給使用者。
三、演算法模型:基於物品的協同過濾並行演算法設計
現在我們以user對book的打分表為計算的資料集,首先匯出生成score.txt檔案
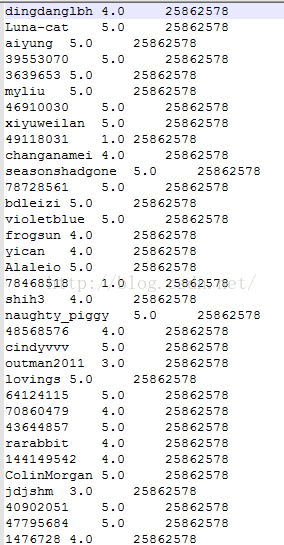
每行三個欄位,分別是userid,socre,bookid(每個欄位之間以\t分割)
並行演算法的實現思想
(1):建立物品的同現矩陣
(2):建立使用者對物品的評分矩陣
(3):矩陣計演算法推薦結果
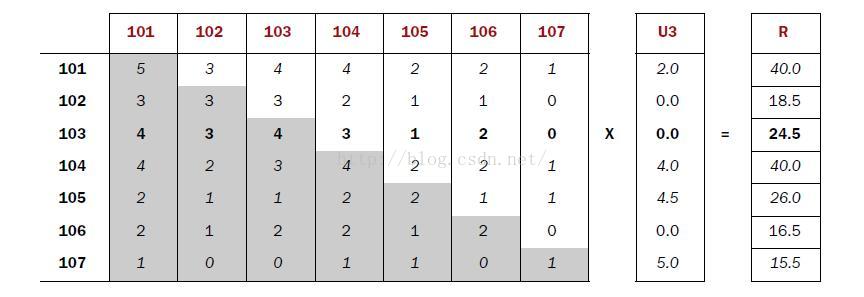
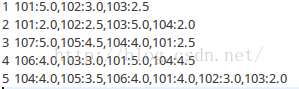
為了方便,我們拿一個小的資料集進行說明,資料樣例如下:
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0(1):建立物品的同現矩陣
按使用者分組,找到每個使用者所選的物品,單獨出現計數及兩兩一組計數。
[101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1(2):建立使用者對物品的評分矩陣
U3
[101] 2.0
[102] 0.0
[103] 0.0
[104] 4.0
[105] 4.5
[106] 0.0
[107] 5.0(3):矩陣計演算法推薦結果
同現矩陣*評分矩陣=推薦結果
四、架構設計:推薦系統架構
系統架構設計如下:
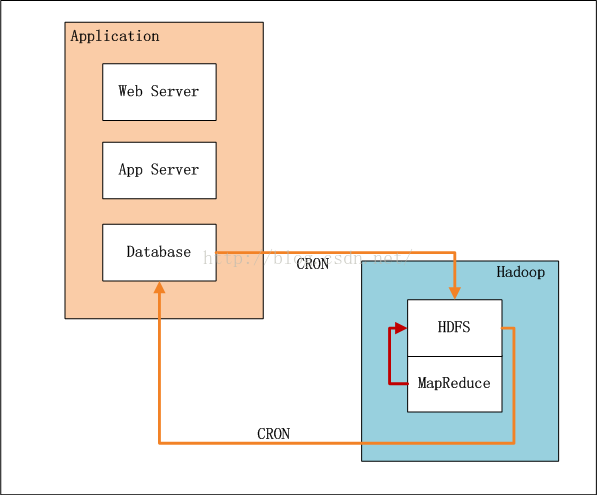
App Service,Applicate業務系統,HDFS為分散式檔案系統,Mapreduce為執行MRV2程式
- 業務系統記錄了使用者的行為和對物品的打分
- 設定系統定時器CRON,定時,增量向HDFS匯入資料(userid,itemid,value,time)。
- 完成匯入後,設定系統定時器,啟動MapReduce程式,執行推薦演算法。
- 完成計算後,設定系統定時器,從HDFS匯出推薦結果資料到資料庫,方便以後的及時查詢。
五、程式實現:MR2V程式實現
新建Java類:
bookRecommend.java,主任務啟動程式
Step1.java,按使用者分組,計算所有物品出現的組合列表,得到使用者對物品的評分矩陣
Step2.java,對物品組合列表進行計數,建立物品的同現矩陣
Step3.java,對同現矩陣和評分矩陣轉型
Step4.java,合併矩陣,並計算推薦結果列表
HdfsGYT.java,HDFS操作工具類
我們拿上邊的資料集為例
bookRecommend.java
package bookTuijian;
import java.io.IOException;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class bookRecommend {
/**
* @param args
* 驅動程式,控制所有的計算結果
*/
public static final String HDFS = "hdfs://127.0.0.1:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Map<String,String> path = new HashMap<String,String>();
path.put("local_file", "MyItems/bookTuijian/uid_to_bid.csv"); //本地檔案所在的目錄
path.put("hdfs_root_file", HDFS+"/mr/bookRecommend/uid_to_bid"); //上傳本地檔案到HDFS上的存放路徑
path.put("hdfs_step1_input", path.get("hdfs_root_file")); //step1的輸入檔案存放目錄
path.put("hdfs_step1_output", HDFS+"/mr/bookRecommend/step1"); //hdfs上第一步執行的結果存放檔案目錄
path.put("hdfs_step2_input", path.get("hdfs_step1_output")); //step2的輸入檔案目錄
path.put("hdfs_step2_output", HDFS+"/mr/bookRecommend/step2"); //step2的輸出檔案目錄
path.put("hdfs_step3_1_input", path.get("hdfs_step1_output")); //構建評分矩陣
path.put("hdfs_step3_1_output", HDFS+"/mr/bookRecommend/Step3_1");
path.put("hdfs_step3_2_input", path.get("hdfs_step2_output")); //構建同現矩陣
path.put("hdfs_step3_2_output", HDFS+"/mr/bookRecommend/Step3_2");
path.put("hdfs_step4_input_1", path.get("hdfs_step3_1_output")); //計算乘積
path.put("hdfs_step4_input_2", path.get("hdfs_step3_2_output"));
path.put("hdfs_step4_output", HDFS+"/mr/bookRecommend/result");
Step1.run(path); //
Step2.run(path);
Step3_1.run(path); //構造評分矩陣
Step3_2.run(path); //構造同現矩陣
Step4.run(path); //計算乘積
System.exit(0);
}
}
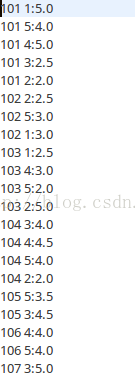
Step1.java
執行結果:
Step2.java
執行結果:

Step3_1.java
執行結果:
Step3_2.java
執行結果:
Step4.java
最終結果為(第一列是userid,第二列是itemid,第三列是喜歡程式):
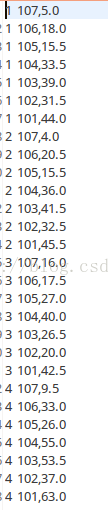
最終需要從中過濾掉使用者已經看過的書籍,從而將餘下的排序取Top K進行推薦
eg:使用者 3,他對101,102,103,104,105,106,107的興趣程度為,42.5,20.0,26.5,40.0,27.0,17.5,16.0,排序後item的id順序為 101,104,105,103,102,106,107,他已經打過分的有101,104,105,107,則餘下的按順序為103,102,106
加入這裡要給使用者3推薦2個的話,那麼就會推薦103和102
最終執行結果hdfs截圖如下:
接下來就是修改部分實驗程式碼為我所用了,因為資料集的不同和資料型別的不一致,所以我們要靈活的運用程式碼,說一下我在這裡遇到的問題吧:
因為執行上邊的樣例檔案時,並沒有報錯,是因為,在矩陣乘法階段,也就是Step4.java,Map類中需要先構造同現矩陣coocurenceMatrix,如果不構造同現矩陣,那麼在進行乘法時將會報錯,這就是我執行score.txt檔案時,所遇到的問題,因為hadoop從hdfs上讀取小檔案時,會先讀佔用空間大的檔案,這樣就不難保證先生成coocurenceMatrix了,so在這裡我們需要進行將程式碼進行改善(Step4.java 進行修改,這裡把矩陣乘法進行分開計算,先進行對於位置相乘Step4_Updata.java,最後進行加法Step4_Updata2.java)
Step4_Updata.java:
package bookTuijian;
import java.io.IOException;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/*
* 是對Step4的優化,分為矩陣相乘和相加,這一步是相乘
*/
public class Step4_Updata {
public static class Step4_Updata_Map extends Mapper< LongWritable, Text, Text, Text>{
String filename;
@Override
protected void setup(Context context) throws IOException,InterruptedException {
// TODO Auto-generated method stub
InputSplit input = context.getInputSplit();
filename = ((FileSplit) input).getPath().getParent().getName();
System.out.println("FileName:" +filename);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
String[] tokens = bookRecommend.DELIMITER.split(value.toString()); //切分
if(filename.equals("Step3_2") ){ //同現矩陣
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
Text key1 = new Text(itemID1);
Text value1 = new Text("A:" + itemID2 +"," +num);
context.write(key1,value1);
// System.out.println(key1.toString() + "\t" + value1.toString());
}else{ //評分矩陣
String[] v2 = tokens[1].split(":");
String itemID = tokens[0];
String userID = v2[0];
String score = v2[1];
Text key1 = new Text(itemID);
Text value1 = new Text("B:" + userID + "," + score);
context.write(key1,value1);
// System.out.println(key1.toString() + "\t" + value1.toString());
}
}
}
public static class Step4_Updata_Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
// System.out.println(key.toString()+ ":");
Map mapA = new HashMap();
Map mapB = new HashMap();
for(Text line : values){
String val = line.toString();
// System.out.println(val);
if(val.startsWith("A")){
String[] kv = bookRecommend.DELIMITER.split(val.substring(2));
mapA.put(kv[0], kv[1]); //ItemID, num
// System.out.println(kv[0] + "\t" + kv[1] + "--------------1");
}else if(val.startsWith("B")){
String[] kv = bookRecommend.DELIMITER.split(val.substring(2));
mapB.put(kv[0], kv[1]); //userID, score
// System.out.println(kv[0] + "\t" + kv[1] + "--------------2");
}
}
double result = 0;
Iterator iterA = mapA.keySet().iterator();
while(iterA.hasNext()){
String mapkA = (String) iterA.next(); //itemID
int num = Integer.parseInt((String) mapA.get(mapkA)); // num
Iterator iterB = mapB.keySet().iterator();
while(iterB.hasNext()){
String mapkB = (String)iterB.next(); //UserID
double score = Double.parseDouble((String) mapB.get(mapkB)); //score
result = num * score; //矩陣乘法結果
Text key2 = new Text(mapkB);
Text value2 = new Text(mapkA + "," +result);
context.write(key2,value2); //userID \t itemID,result
// System.out.println(key2.toString() + "\t" + value2.toString());
}
}
}
}
public static void run(Map<String, String> path) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
String input_1 = path.get("hdfs_step4_updata_input");
String input_2 = path.get("hdfs_step4_updata2_input");
String output = path.get("hdfs_step4_updata_output");
hdfsGYT hdfs = new hdfsGYT();
hdfs.rmr(output);
Job job = new Job(new Configuration(), "Step4_updata");
job.setJarByClass(Step4_Updata.class);
//設定檔案輸入輸出路徑
FileInputFormat.setInputPaths(job, new Path(input_1),new Path(input_2));
FileOutputFormat.setOutputPath(job, new Path(output));
//設定map和reduce類
job.setMapperClass(Step4_Updata_Map.class);
job.setReducerClass(Step4_Updata_Reduce.class);
//設定Map輸出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//設定Reduce輸出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定檔案輸入輸出
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.waitForCompletion(true);
}
}
package bookTuijian;
import java.io.IOException;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Step4_Updata2 {
public static class Step4_Updata2_Map extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
// TODO Auto-generated method stub
String[] tokens = bookRecommend.DELIMITER.split(value.toString());
Text key1 = new Text(tokens[0]);//userID
Text value1 = new Text(tokens[1] + "," + tokens[2]);
context.write(key1, value1); //itemID,result
}
}
public static class Step4_Updata_Reduce extends Reducer< Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {
// TODO Auto-generated method stub
Map map = new HashMap();
for(Text line: values){
System.out.println(line.toString());
String[] tokens = bookRecommend.DELIMITER.split(line.toString());
String itemID = tokens[0];
Double result = Double.parseDouble(tokens[1]);
if(map.containsKey(itemID)){
map.put(itemID, Double.parseDouble(map.get(itemID).toString()) + result);//矩陣乘法求和計算
}else{
map.put(itemID, result);
}
}
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
String itemID = (String) iter.next();
double score = (double) map.get(itemID);
Text v = new Text(itemID + "," + score);
context.write(key, v);
}
}
}
public static void run(Map<String, String> path) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
String input = path.get("hdfs_step4_updata2_input");
String output = path.get("hdfs_step4_updata2_output");
hdfsGYT hdfs = new hdfsGYT();
hdfs.rmr(output);
Job job = new Job(new Configuration(), "Step4_Updata2");
job.setJarByClass(Step4_Updata2.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
//設定map和reduce類
job.setMapperClass(Step4_Updata2_Map.class);
job.setReducerClass(Step4_Updata_Reduce.class);
//設定Map輸出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//設定Reduce輸出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//設定檔案輸入輸出
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.waitForCompletion(true);
}
}
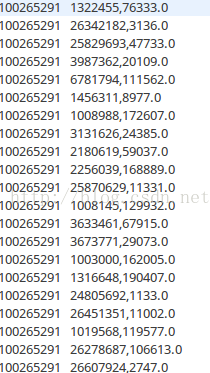
第一列為使用者id,第二列為bookid,第三列為喜歡程度,由於資料集的關係,這裡計算結果較大,在實際環境中,往往需要量化處理
六、推薦系統評估
1:使用者滿意度
使用者滿意度是無法通過離線實驗得到的,只能通過使用者調查或者線上實驗得到。
使用者調查獲得使用者滿意度主要是通過調查問卷的形式,使用者對推薦系統的滿意度分為不同的層次,GroupLens曾經做過一個論文推薦系統的調查問卷,該問卷的調查問題是請問下面哪句話最能描述你看到推薦結果後的感受
(1)推薦的論文都是我想看的
(2)推薦的論文很多我都看過了,確實是符合我興趣的不錯的論文
(3)推薦的論文和我的研究興趣是相關的,但是我並不喜歡
(4)不知道為什麼會推薦這些論文,它們和我的興趣沒有關係
由此可以看出,這個問卷不是簡單的詢問使用者對結果的滿意度,而是從不同的側面詢問使用者對結果的不同感受。
線上實驗,主要是記錄一些使用者的行為得到,比如說電子商務網站,使用者買了推薦的商品,就表示它們在一定程度上喜歡。
2:預測準確度
評分預測:針對使用者給物品打分的推薦系統,比如豆瓣的評分

TopN推薦:網站在提供推薦服務時,一般是給使用者一個個性化的推薦列表,這種推薦叫做 TopN 推薦,TopN 推薦的預測準確率一般通過準確率( precision ) / 召回率( recall )度量。

3:覆蓋率
覆蓋率( coverage )描述一個推薦系統對物品長尾的發掘能力。覆蓋率有不同的定義方法,最簡單的定義為推薦系統能夠推薦出來的物品佔總物品集合的比例。假設系統的使用者集合為 U ,推薦系統給每個使用者推薦一個長度為 N 的物品列表 R(u) 。那麼推薦系統的覆蓋率可以通過下面的公式計算:
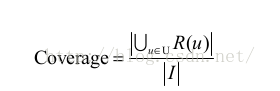
從上面的定義可以看到,覆蓋率是一個內容提供商會關心的指標。以圖書推薦為例,出版社可能會很關心他們的書有沒有被推薦給使用者。覆蓋率為 100% 的推薦系統可以將每個物品都推薦給至少一個使用者。此外,從上面的定義也可以看到,熱門排行榜的推薦覆蓋率是很低的,它只會推薦那些熱門的物品,這些物品在總物品中佔的比例很小。一個好的推薦系統不僅需要有比較高的使用者滿意度,也要有較高的覆蓋率。
在資訊理論和經濟學中有兩個著名的指標可以用來定義覆蓋率。第一個是資訊熵:

第二個指標是基尼係數( Gini Index ):
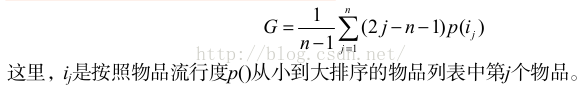
4:多樣性
為了滿足使用者廣泛的興趣,推薦列表需要能夠覆蓋使用者不同的興趣領域,即推薦結果需要具有多樣性。
多樣性描述了推薦列表中物品兩兩之間的不相似性。因此,多樣性和相似性是對應的。假設s ( i , j )屬於 [0,1] 定義了物品 i 和 j 之間的相似度,那麼使用者 u 的推薦列表 R(u) 的多樣性定義如下:
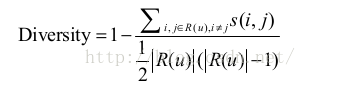
而推薦系統的整體多樣性可以定義為所有使用者推薦列表多樣性的平均值:
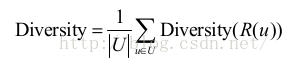
從上面的定義可以看到,不同的物品相似度度量函式 s(i, j) 可以定義不同的多樣性。如果用內容相似度描述物品間的相似度,我們就可以得到內容多樣性函式,如果用協同過濾的相似度函式描述物品間的相似度,就可以得到協同過濾的多樣性函式。
5:新穎性
新穎的推薦是指給使用者推薦那些他們以前沒有聽說過的物品。在一個網站中實現新穎性的最簡單辦法是,把那些使用者之前在網站中對其有過行為的物品從推薦列表中過濾掉。