
Java訊息中介軟體學習九 -- ActiveMQ與HA架構(master/slave)
HA(高可用性)幾乎在所有的架構中都需要有一定的保證 ,在生產環境中,我們也需要面對broker失效、網路故障等各種問題,ActiveMQ也不例外。activeMQ作為消費分發和儲存系統,它的HA模型只有master-slave,我們通過broker節點“訊息互備”來達成設計要求。M-S架構中,只有master開啟transportConnector,slave不開啟,所以客戶端只能與master通訊,客戶端無法與slave建立連線。
Client端與master互動並生產和訊息訊息,並且有一個或者多個slave與其保持同步,如果master失效,我們希望slave能夠自動角色轉換並接管服務,並且故障轉移的過程不能影響Client對訊息服務的使用(failover)。ActiveMQ Broker不僅僅負責訊息的分發,還需要儲存訊息,根據儲存機制的不同,master-slave模式分為兩種:“Shared nothing”和“Shared storage”。其中“Shared nothing”表明每個broker有各自的儲存機制,各個broker之間無任何資料共享,這是最簡單的部署方案,當然也是資料可靠性最低的,如果一個broker儲存裝置故障將會導致此broker中的資料需要重建,master與slave之間的狀態感知,是通過TCP通訊來實現。“Shared storage”是推薦的架構方案,master與slave之間共享遠端儲存系統(比如JDBC Storage,SAN分散式檔案系統等),master與slave通過獲取Storage的排他鎖狀態來感知狀態,獲取鎖的broker作為master並負責與Client資料互動,當鎖失效後slave之間通過鎖競爭來產生新的master,在最新的架構中,zookeeper也可以很方便的整合到ActiveMQ中。
master-slave並不是大規模訊息系統的擴充套件方案,它只是解決broker節點的HA問題,稍後我們會介紹“Forward Brige”模式在activeMQ分散式系統中的應用。
一. Share nothing storage master/slave
最簡單最典型的master-slave模式,master與slave有各自的儲存系統,不共享任何資料。master接收到的所有指令(訊息生產,消費,確認,事務,訂閱等)都會同步傳送給slave。在slave啟動之前,首先啟動master,在master有效時,salve將不會建立任何transportConnector,即Client不能與slave建立連結;如果master失效,slave是否接管服務是可選擇的(參見下文配置)。在master與slave之間將會建立TCP連結用來資料同步,如果連結失效,那麼master認為slave離線。
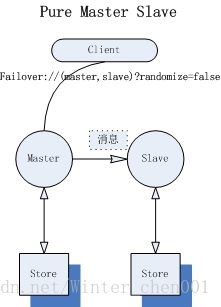
對於持久化訊息,將會採用同步的方式(sync)在master與slave之間備份,master接受到訊息之後,首先發給slave,slave儲存成功後,master才會儲存訊息並向producer傳送ACK。
當master失效後,slave有兩種選擇:
1) 關閉: 如果slave檢測到master失效,slave例項關閉自己。此後管理員需要手動依次啟動master、slave來恢復服務。
2) 角色轉換: slave將自己提升為master,並初始化transportConnector,此後Client可以通過failover協議切換到Slave上,並與slave互動。
//Client使用failover協議來與有效的master互動
//master地址在前,slave在後,randomize為false讓Client優先與master通訊
//如果master失效,failover協議將會嘗試與slave建立連結,並依此重試
failover://(tcp://master:61616,tcp://slave:61616)?randomize=false “Shared nothing”模式下,有很多侷限性。master只能有一個slave,而且slave不能繼續掛載slave。如果slave較晚的接入master,那麼master上已有的訊息不會同步給slave,只會同步那些slave接入之後的新訊息,那也意味著slave並沒有完全持有全域性的所有訊息;所以如果此時master失效,slave接入之前的訊息有丟失的風險。如果一個新的slave接入master,或者一個失效時間較長的舊master接入新master,通常會首先關閉master,然後把master上所有的資料Copy給slave(或舊master),然後依次啟動它們。事實上,ActiveMQ沒有提供任何有效的手段,能夠讓master與slave在故障恢復期間,自動進行資料同步。
Master配置:
<broker brokerName="master" waitForSlave="true" shutdownOnSlaveFailure="false" waitForSlaveTimeout="600000" useJmx="false" >
...
<transportConnectors>
<transportConnector uri="tcp://localhost:61616"/>
</transportConnectors>
</broker>
其中shutdownOnSlaveFailure預設為false,即當slave失效時,master將繼續服務,否則master也將關閉。waitForSlave表示當master啟動之後,是否等待slave接入,如果為true,那麼master將會等待waitForSlaveTimeout毫秒數,直到有slave接入之後master才會初始化transportConnector,此間Client無法與master互動;如果等待超時,則有shutdownOnSlaveFailure決定master是否關閉。
Slave配置:
<broker brokerName="slave" shutdownOnMasterFailure="false">
<services>
<masterConnector remoteURI= "tcp://master:61616"/>
</services>
....
<transportConnectors>
<transportConnector uri="tcp://localhost:61616"/>
</transportConnectors>
</broker> shutdownOnMasterFailure表示當master失效後,slave是否自動關閉,預設為false,表示slave將提升為master。
不過我們需要注意,master與slave之間通過Tcp連結感知對方的狀態,基於連結感知狀態的“三節點網路”(Client,Master,slave),結果總是不可靠的;如果master與slave例項都有效,只是master與slave之間的網路“阻斷”,此時slave也會認為master失效,如果slave提升為master,對於Client而言將會出現2個master的“幻覺”。更壞的情況是,部分Client與舊master之間也處於網路阻斷情況,那麼就會出現部分Client連結在新master上,其他的Client連結在舊master上,資料的一致性將處於失控狀態。(split-brain)為了避免出現“腦裂”現象,我們通常將“shutdownOnMasterFailure”(slave上)、“shutdownOnSlaveFailure”(master上)兩個引數不能同時設定為false。
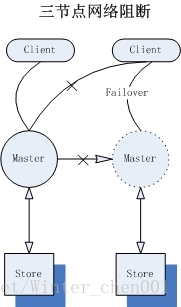
因為這種模式下各種侷限性,“Shared nothing”模式已經被active所拋棄,將在5.8+之後版本中移除。不過對於小型應用而言,這種模式帶來的便捷性也是顯而易見的。
二. Shared storage master/slave
在上文中,我們已經瞭解了“Shared nothing”模式下的侷限性,在企業級架構中它將不能作為一種可靠的方案而實施。ActiveMQ官方推薦“Shared storage”模式作為首選方案,並提供了多個優秀的儲存策略,其中kahadb、levedbDB、JDBC Store等都可以便捷的接入。
“Shared storage”允許叢集中有多個slave共存,因為儲存資料在salve與master之間共享(物理共享),所以當master失效後,slave自動接管服務,而無需手動進行資料的Copy與同步,也無需master與slave之間進行任何額外的資料互動,因為master儲存資料之後,它們在任何時候對slave都是可見的。master與slave之間,通過共享檔案的“排他鎖”或者分散式排他鎖(zookeeper)來決定broker的狀態與角色,獲取鎖許可權的broker作為master,如果master失效,它必將失去鎖許可權,那麼slaves將通過鎖競爭來選舉新master,沒有獲取鎖許可權的broker作為slave,並等待鎖的釋放(間歇性嘗試獲取鎖)。當然slaves仍然不能為Client服務, 它只為故障轉移做準備。
在此需要明確一個問題,“Shared storage”模式只會共享“持久化”型別的訊息;對於非持久化訊息將不能從從中收益,它們不會在slaves中備份,這也意味著如果master失效,即使slave接管了服務,此前儲存在master上的非持久化訊息也將丟失。通常,我們在“Shared storage”模式中,額外的配置一個外掛,強制將所有訊息轉換成持久化型別,這樣所有的訊息都可以在故障恢復之後不會丟失。
<broker>
<plugins>
<!-- 將所有訊息的傳輸模式,修改為"PERSISTENT" -->
<forcePersistencyModeBrokerPlugin persistenceFlag="true"/>
</plugins>
</broker> 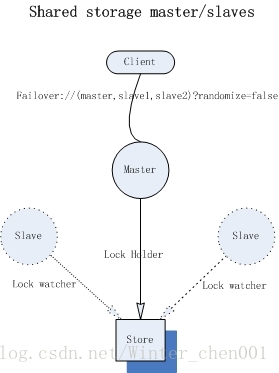
1. Shared File System master/slaves
基於共享檔案系統的master/slaves模式,此處所謂的“共享檔案系統”目前只能是基於POSIX介面可以訪問的檔案系統,比如本地檔案系統或者SAN分散式共享檔案系統(比如:glusterFS);對於broker而言,啟動時將會首先獲取儲存引擎的檔案鎖,如果獲取成功才能繼續初始化transportConnector,否則它將一直嘗試獲取鎖(tryLock),那麼對於共享檔案系統而言,需要嚴格確保任何時候只能有一個程序獲取排他鎖,如果你選擇的SAN檔案系統不能保證此條件,那麼將不能作為master/slavers的共享儲存引擎。
“Shared File System”這種方式是最常用的模式,架構簡單,可靠實用。我們只需要一個SAN檔案系統即可。
在這種模式下,master與slave的配置幾乎可以完全一樣。如下示例中,我們使用一個master和一個slave,它們部署在一個物理機器上,使用本地檔案系統作為“共享檔案系統”。(僅作示例,不可用於生產環境)
Master/Slave配置
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="broker-locahost-0" useJmx="false">
<persistenceAdapter>
<levelDB directory="/data/leveldb"/>
</persistenceAdapter>
<tempDataStore>
<levelDB directory="/data/leveldb/tmp"/>
</tempDataStore>
<!--
<persistenceAdapter>
<kahaDB directory="/data/kahadb"/>
</persistenceAdapter>
<tempDataStore>
<pListStoreImpl directory="/data/kahadb/tmp"/>
</tempDataStore>
-->
<transportConnectors>
<!-- slave -->
<!--
<transportConnector name="openwire" uri="tcp://0.0.0.0:51616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
-->
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
</transportConnectors>
</broker>對於Client端而言,可以使用failover協議來訪問broker:
failover://(tcp://localhost:61616,tcp://localhost:51616)?randomize=false 2. JDBC Store master/slaves
顯而易見,資料儲存引擎為database,activeMQ通過JDBC的方式與database互動,排他鎖使用database的表級排他鎖,其他原理基本上和1)一致。JDBC Store相對於日誌檔案而言,通常認為是低效的,儘管資料的可見性較好,但是database的擴容能力非常的弱,無法良好的適應在高併發、大資料情況下(嚴格來說,單組M-S架構是無法支援大資料的),況且ActiveMQ的訊息通常儲存時間較短,頻繁的寫入,頻繁的刪除,都是效能的影響點。我們通常在研究activeMQ的儲存原理時使用JDBC Store,或者在中小型應用中對資料一致性(可靠性,可見性)要求較高的環境中使用:比如訂單系統中交易流程支撐系統等。但是因為JDBC架構的實施簡便,易於管理,我們仍然傾向於首選這種方式。
在使用JDBC Store之前,必須有一個穩定的database,且指定授權給acitvemq中的連結使用者具有“建立表”和普通CRUD的許可權。master與slave中的配置檔案基本一樣,開發者需要注意brokerName和brokerId全域性不可重複。此外還需要把相應的jdbc-connector的jar包copy到${acitvemq}/lib/optional目錄下。
Master/Slave配置:
<broker brokerName="broker-locahost-0">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
<transportConnectors>
<!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
</transportConnectors>
</broker>
<bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/activemq?relaxAutoCommit=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
<property name="poolPreparedStatements" value="true"/>
</bean> JDBC Store有個小小的問題,就是臨時檔案無法儲存在database中,我們不能在使用JDBC Store;所以臨時檔案還是隻能儲存在broker本地。(即非持久訊息不會儲存在database中,只會儲存在master上)
三. Replicated LevelDB Store
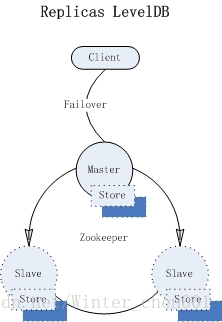
基於複製的LevelDB Store,這是ActiveMQ全力打造的HA儲存引擎,也是目前比較符合“Master-slave”架構模型的儲存方案,此特性在5.9+版本中支援。我們從1)/2)兩個方案中可見,“Shared Storage”模式只是利用了“一些小伎倆”,並不符合廣泛意義上的“master-slave”模型(在儲存上,和通訊機制上)。不過,“Replicated LevelDB Store”做到了!!
“Replicated LevelDB”也同樣允許有多個Slaves,而且Slaves的個數有了約束性的限制,這歸結於其使用zookeeper作為Broker master選舉。每個Broker例項將訊息資料儲存本地(類似於“Shared nothing”),它們之間並不共享任何資料,所以把“Replicated LevelDB”歸類為“Shared storage”並不妥當。
當Broker啟動時,它首先向zookeeper註冊自己的資訊(brokerName,訊息日誌的版本戳等),如果此時group中沒有其他broker例項,並阻塞初始化過程,等到足夠多的broker加入group;當brokers的數量達到“replicas的多數派”時,開始選舉,選舉將會根據“訊息日誌的版本戳”、“權重”的大小決定,即“版本戳”越大(資料最新)、權重越高的broker優先成為master,其他broker作為slave並跟隨master。當一個broker成為master時,它會向zookeer註冊自己的sync地址資訊;此後slaves首先根據sync地址與master建立連結,並同步訊息檔案(download)。當足夠多的slave資料同步結束後,master將初始化transportConnector,此後Client將可以與master進行資料互動。
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="mq-group" brokerId="mq-group-0" dataDirectory="${activemq.data}">
<persistenceAdapter>
<replicatedLevelDB directory="${activemq.data}"
replicas="2"
bind="tcp://127.0.0.1:0"
zkAddress="127.0.0.1:2181"
zkSessionTmeout="30s"
zkPath="/activemq/leveldb-stores"
hostname="broker0" />
</persistenceAdapter>
</broker> Master-slaves叢集中,所有的broker必須具有相同的brokerName,它作為group域來限定叢集的成員,brokerId可以不同,它僅作為描述資訊。“replicas”引數非常重要,預設為3,表示訊息最多可以備份在幾個broker例項上,同是只有當“replicas/2 + 1”個broker存活時(包含master),叢集才有效,才會選舉master和備份訊息,此值必須>=2。Client傳送給Master的持久化訊息(包括ACK和事務),master首先在本地儲存,然後立即同步(sync)給選定的(replicas/2)個slaves,只有當這些節點也同步成功後,此訊息的互動才算結束;對於剩下的replicas個節點,master採用非同步的方式(async)轉發。這種設計要求,可以保證叢集中訊息的可靠性,只有當(replicas/2 + 1)個節點物理故障,才會有丟失訊息的風險。通常replicas為3,這要求開發者需要至少部署3個broker例項。如果replicas過大,會嚴重影響master的吞吐能力,因為它在sync訊息的過程中會消耗太多的時間。
如果叢集故障,在重啟broker例項時,建議首先檢視每個broker中檢視LevelDB日誌檔案的版本戳(檔名為16進位制數字),並優先啟動版本戳較大的例項。(因為replicas多數派的約束,隨機重啟也不會有太大的問題)。但是不得隨意調小replicas的值,如果你確實需要修改,那就首先關閉叢集,一定優先啟動版本戳最大的broker。
儘管叢集對zookeeper的操作並不是很多,但是我們還是希望不要接入負載過高的zookeeper叢集,以免給訊息服務引入不穩定因素。通常zookeeper叢集至少需要3個例項,才能保證zookeeper本身的高可用性。
其中bind屬性表示當此broker例項成為master時,開啟一個socket地址,此後slave可以通過此地址與其同步資料。
我們還需要為Replicated LevelDB配置zookeeper的地址和path,其中path下用來儲存group中所有broker的註冊資訊,此值在group中所有的broker上都要一樣。“hostname”用來描述當前機器的核心資訊,通常為機器IP。如果你在本機構建偽分散式,那麼需要在系統hosts檔案中使用轉義。
127.0.0.1 broker0
127.0.0.1 broker1
127.0.0.1 broker2 對於Client端而言,仍然需要使用failover協議,而且協議中需要包含group中所有broker的連結地址。
failover://(tcp://localhost:61616,tcp://localhost:51616,tcp://localhost:41616)?randomize=false 和其他模式一樣,對於非持久化訊息仍然只會儲存在master上,當master失效後,訊息將會丟失。
特別注意
本人基於JDBC共享資料庫儲存模式實現HA架構,但是出現了一個比較嚴重的問題。此處把問題描述一下,以及該如何解決。
故障發生時:
1、我們的HA,基於“Journal + JDBC”方式共享儲存。基於Journal的原因是,希望能夠提供更高的IO效能。
2、某日,JDBC對應的資料庫出現問題,觸發ActiveMQ HA叢集Failover,即原slave切換為master。
3、切換之後,發現數據庫中突增大量歷史舊資料;這些舊資料導致業務系統資料異常。
故障發生的原因
1、Journal + JDBC方式:訊息首先寫入Journal日誌檔案(對於非事務性,將會立即轉發給消費者(可以為非同步)),內部通過定時排程執行緒每個一段時間(預設為5分鐘)對日誌檔案進行checkpoint,並將日誌中的訊息批量 + 事務的方式寫入MySql,checkpoint時間點之前的日誌檔案即可被刪除。(Journal日誌檔案中, 儲存有Message、也包括ACK的資訊,當然對於ActiveMQ而言,ACK也是一種Message,所以在checkpoint期間,如果是ACK型別的訊息,也將會從資料庫中刪除訊息)
這意味著,如果Master異常退出,那麼在Journal日誌中、且處於最近一次checkpoint之後的訊息,將“丟失”;因為在Slave上是沒有這些Journal日誌資料的。
<persistenceFactory>
<journalPersistenceAdapterFactory journalLogFiles="5" dataDirectory="${activemq.home}/data" dataSource="#mysql-ds"/>
</persistenceFactory> 2、在ActiveMQ例項啟動之後,正常對外服務之前,broker所做的第一件事,就是recovery,即將Journal日誌進行一次全量的checkpoint。這意味著,無論它是master還是slave,如果本地Journal日誌檔案中有歷史資料,都將會會被recovery。
當在Failover發生時,如果原slave(它曾經是master)本地的journal日誌檔案中有歷史訊息,那麼slave在提升為master之後,將會進行資料恢復,這些“歷史訊息”將會重新“復現”。
3、Broker在正常關閉時,即通過“activemq stop”指令關閉時,關閉之前,將會對journal日誌進行全量checkpoint,不會發生上述情況。
參見原始碼:
1)JournalPersistenceAdapter,Journal,JournalMessageStore;
2)JDBCPersistenceAdapter,JDBCMessageStore,Broker,BrokerService
故障解決方案
1、如果繼續基於Journal + JDBC,或者基於Journal(比如kahaDB),我們原則上,不能支援Failover。在HA架構中,Master、slave角色將不能轉換,如果master失效,我們所做的就是重啟;如果master物理失效而無法恢復,此時才能將slave提升為master。不過為了Client程式碼的透明度,Client端的連結協議中仍然使用“failover”。
2、如果拋棄Journal,直接使用JDBC,那麼HA + failover都將可以支援,因為master和slave的資料檢視只有DB一個,本地不會再儲存資料。它的問題就是:訊息的product效率將會大大降低。因為JDBC儲存,是ActiveMQ中“效能最低”、“資料可靠性最高”的模式。
<persistenceAdapter>
<jdbcPersistenceAdapter dataDirectory="${activemq.base}/data" dataSource="#mysql-ds"/>
</persistenceAdapter>3、可以使用ActiveMQ官方提供的kahaDB + SAN(共享檔案系統),由SAN提供檔案排它鎖決定M-S角色;同時M-S的資料檢視均在SAN的共享檔案中。這也可以幫助我們解決問題,而且效能較高;可維護性較高,支援Failover,也不會帶來資料恢復的問題。
4、ActiveMQ高階版本,已經移除了“原生的M-S”架構模式,也移除了“Replication LevelDB”架構模式。所以我們能選擇的空間已經不大了。
5、我們要求Producer端,在傳送的訊息中,都應該設定TTL引數,即表示訊息的有效期;此值應該合理,無論如何,Consumer都不應該接收到過期的訊息。(對於Broker而言,過期的訊息將會傳送給Consumer)