
Kylin三大引擎和Cube構建原始碼解析
阿新 • • 發佈:2019-02-05
最近在工作中用到了kylin,相關資料還不是很多,關於原始碼的更是少之又少,於是結合《kylin權威指南》、《基於Apache Kylin構建大資料分析平臺》、相關技術部落格和自己對部分原始碼的理解進行了整理。
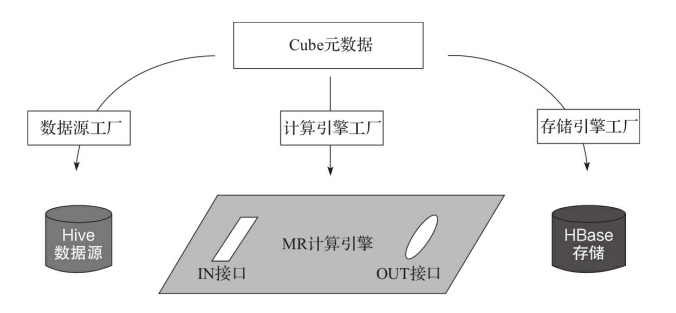
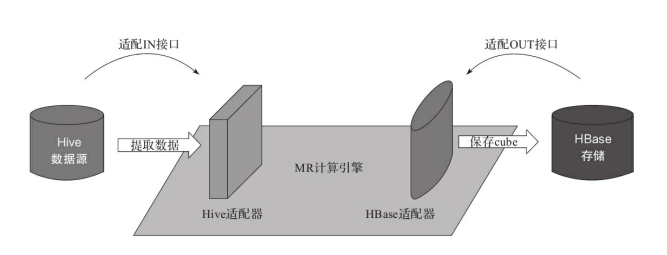 計算引擎只提出介面需求,每個介面都可以有多種實現,也就是能接入多種不同的資料來源和儲存。類似的,每個資料來源和儲存也可以實現多個介面,適配到多種不同的計算引擎上。三者之間是多對多的關係,可以任意組合,十分靈活。二、三大主要介面(一)資料來源介面ISource
計算引擎只提出介面需求,每個介面都可以有多種實現,也就是能接入多種不同的資料來源和儲存。類似的,每個資料來源和儲存也可以實現多個介面,適配到多種不同的計算引擎上。三者之間是多對多的關係,可以任意組合,十分靈活。二、三大主要介面(一)資料來源介面ISource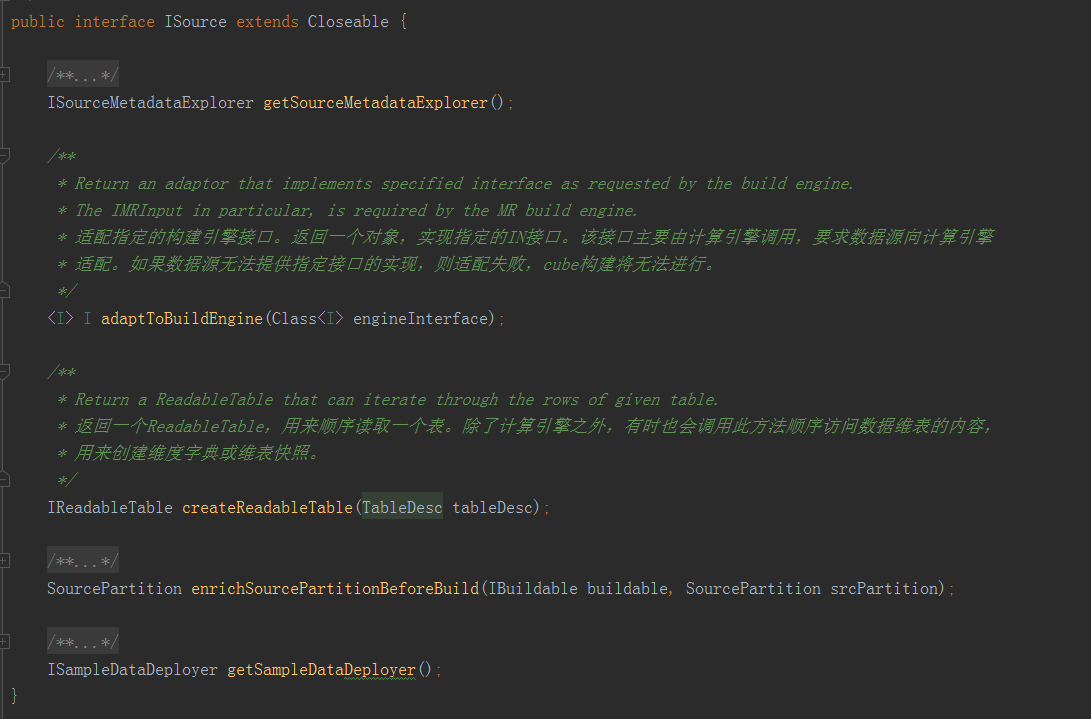
·adaptToBuildEngine:適配指定的構建引擎介面。返回一個物件,實現指定的IN介面。該介面主要由計算引擎呼叫,要求資料來源向計算引擎適配。如果資料來源無法提供指定介面的實現,則適配失敗,Cube構建將無法進行。·createReadableTable:返回一個ReadableTable,用來順序讀取一個表。除了計算引擎之外,有時也會呼叫此方法順序訪問資料維表的內容,用來建立維度字典或維錶快照。
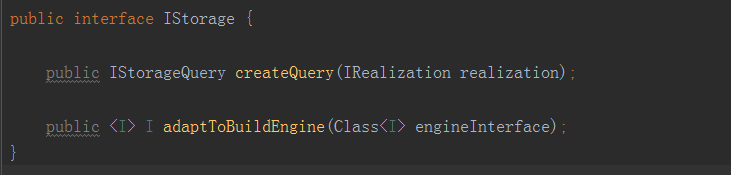
·adaptToBuildEngine:適配指定的構建引擎介面。返回一個物件,實現指定的OUT介面。該介面主要由計算引擎呼叫,要求儲存引擎向計算引擎適配。如果儲存引擎無法提供指定介面的實現,則適配失敗,Cube構建無法進行。·createQuery:建立一個查詢物件IStorageQuery,用來查詢給定的IRealization。簡單來說,就是返回一個能夠查詢指定Cube的物件。IRealization是在Cube之上的一個抽象。其主要的實現就是Cube,此外還有被稱為Hybrid的聯合Cube。(三)計算引擎介面IBatchCubingEngine
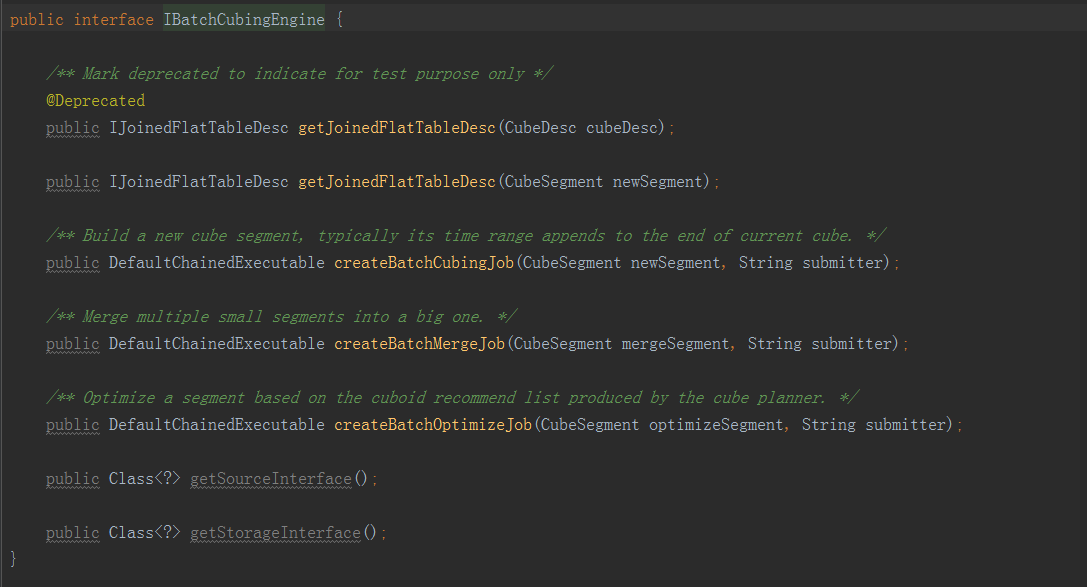
·createBatchCubingJob

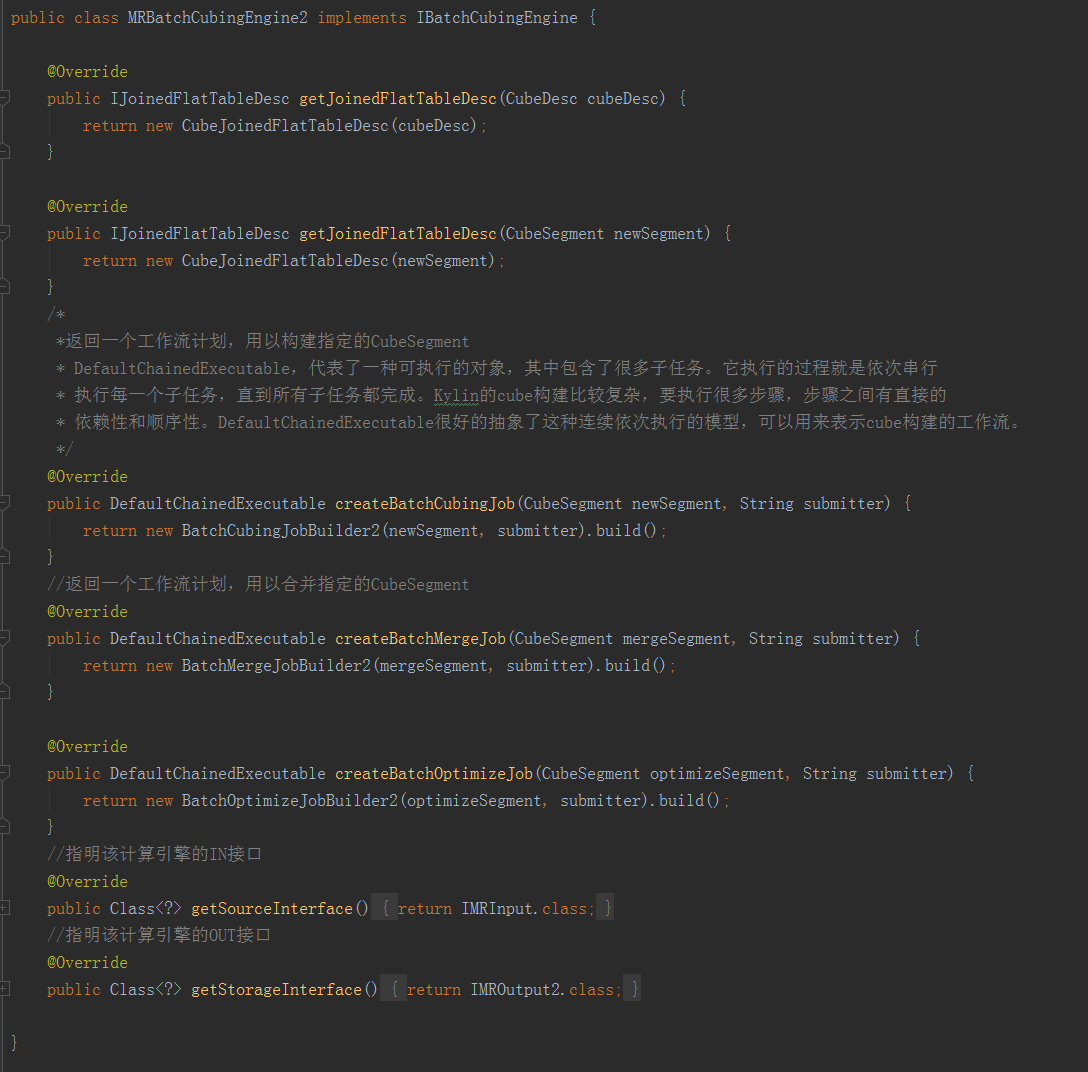
這是一個入口類,構建Cube的主要邏輯都封裝在BatchCubingJobBuilder2和BatchMergeJobBuilder2中。其中的DefaultChainedExecutable,代表了一種可執行的物件,其中包含了很多子任務。它執行的過程就是一次序列執行每一個子任務,直到所有子任務都完成。kylin的構建比較複雜,要執行很多步驟,步驟之間有直接的依賴性和順序性。DefaultChainedExecutable很好地抽象了這種連續依次執行的模型,可以用來表示Cube的構建的工作流。另外,重要的輸入輸出介面也在這裡進行宣告。IMRInput是IN介面,由資料來源適配實現;IMROutput2是OUT介面,由儲存引擎適配實現。2.BatchCubingJobBuilder2BatchCubingJobBuilder2和BatchMergeJobBuilder2大同小異,這裡以BatchCubingJobBuilder2為例。

 ·getTableInputFormat方法返回一個IMRTableInputFormat物件,用以幫助MR任務從資料來源中讀取指定的關係表,為了適應MR程式設計介面,其中又有兩個方法,configureJob在啟動MR任務前被呼叫,負責配置所需的InputFormat,連線資料來源中的關係表。由於不同的InputFormat所讀入的物件型別各不相同,為了使得構建引擎能夠統一處理,因此又引入了parseMapperInput方法,對Mapper的每一行輸入都會呼叫該方法一次,該方法的輸入是Mapper的輸入,具體型別取決於InputFormat,輸出為統一的字串陣列,每列為一個元素。整體表示關係表中的一行。這樣Mapper救能遍歷資料來源中的表了。·getBatchCubingInputSide方法返回一個IMRBatchCubingInputSide物件,參與建立一個CubeSegment的構建工作流,它內部包含三個方法,addStepPhase1_CreateFlatTable()方法由構建引擎呼叫,要求資料來源在工作流中新增步驟完成平表的建立;getFlatTableInputFormat()方法幫助MR任務讀取之前建立的平表;addStepPhase4_Cleanup()是進行清理收尾,清除已經沒用的平表和其它臨時物件,這三個方法將由構建引擎依次呼叫。4.IMROutput2
·getTableInputFormat方法返回一個IMRTableInputFormat物件,用以幫助MR任務從資料來源中讀取指定的關係表,為了適應MR程式設計介面,其中又有兩個方法,configureJob在啟動MR任務前被呼叫,負責配置所需的InputFormat,連線資料來源中的關係表。由於不同的InputFormat所讀入的物件型別各不相同,為了使得構建引擎能夠統一處理,因此又引入了parseMapperInput方法,對Mapper的每一行輸入都會呼叫該方法一次,該方法的輸入是Mapper的輸入,具體型別取決於InputFormat,輸出為統一的字串陣列,每列為一個元素。整體表示關係表中的一行。這樣Mapper救能遍歷資料來源中的表了。·getBatchCubingInputSide方法返回一個IMRBatchCubingInputSide物件,參與建立一個CubeSegment的構建工作流,它內部包含三個方法,addStepPhase1_CreateFlatTable()方法由構建引擎呼叫,要求資料來源在工作流中新增步驟完成平表的建立;getFlatTableInputFormat()方法幫助MR任務讀取之前建立的平表;addStepPhase4_Cleanup()是進行清理收尾,清除已經沒用的平表和其它臨時物件,這三個方法將由構建引擎依次呼叫。4.IMROutput2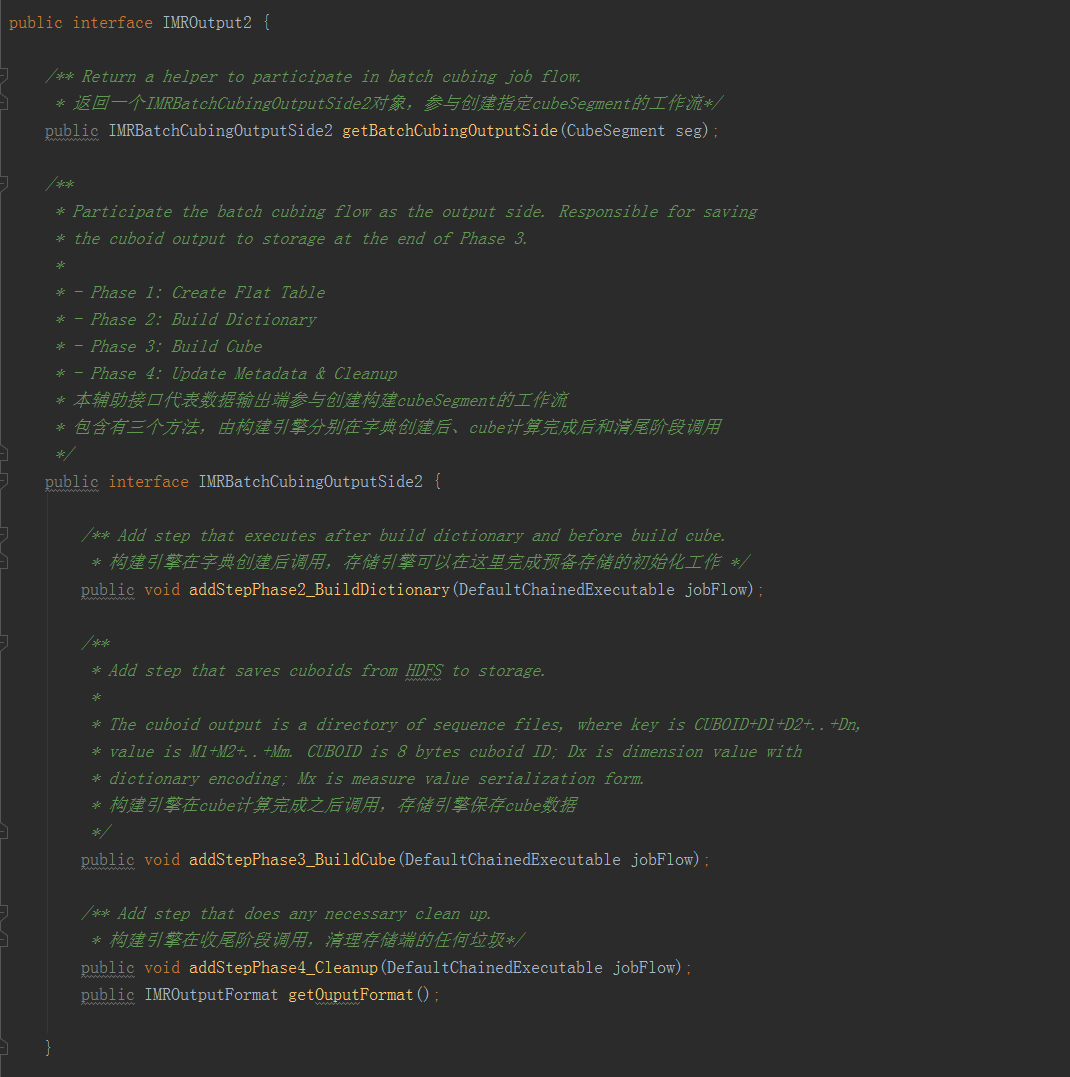
這是BatchCubingJobBuilder2對儲存引擎的要求,所有希望接入BatchCubingJobBuilder2的儲存都必須實現該介面。IMRBatchCubingOutputSide2代表儲存引擎配合構建引擎建立工作流計劃,該介面的內容如下:·addStepPhase2_BuildDictionary:由構建引擎在字典建立後呼叫。儲存引擎可以藉此機會在工作流中新增步驟完成儲存端的初始化或準備工作。·addStepPhase3_BuildCube:由構建引擎在Cube計算完畢之後呼叫,通知儲存引擎儲存CubeSegment的內容。每個構建引擎計算Cube的方法和結果的儲存格式可能都會有所不同。儲存引擎必須依照資料介面的協議讀取CubeSegment的內容,並加以儲存。·addStepPhase4_Cleanup:由構建引擎在最後清理階段呼叫,給儲存引擎清理臨時垃圾和回收資源的機會。(二)資料來源HiveHive是kylin的預設資料來源,由於資料來源的實現依賴構建引擎對輸入介面的定義,因此本節的具體內容只適用於MR引擎。資料來源HiveSource首先要實現ISource介面。
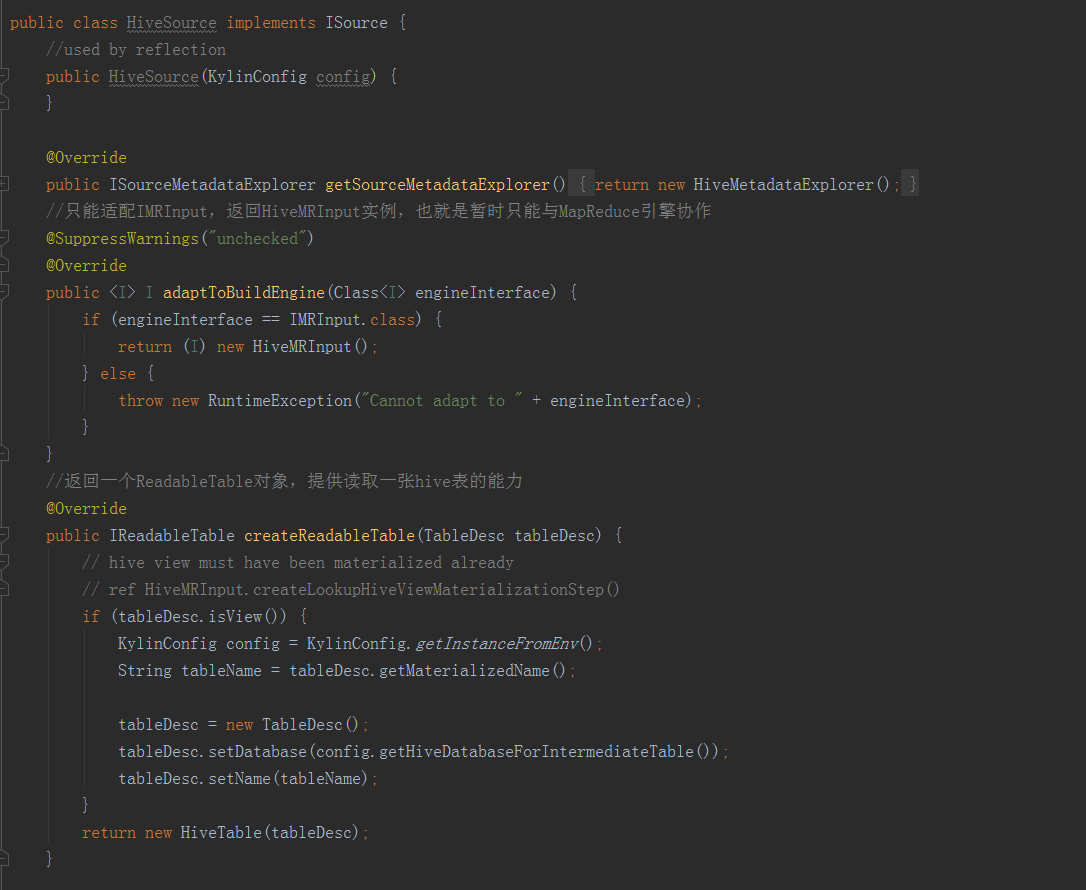 HiveSource實現了ISource介面中的方法。adaptToBuildEngine()只能適配IMRInput,返回HiveMRInput例項。另一個方法createReadableTable()返回一個ReadableTable物件,提供讀取一張hive表的能力。HiveMRInput
HiveSource實現了ISource介面中的方法。adaptToBuildEngine()只能適配IMRInput,返回HiveMRInput例項。另一個方法createReadableTable()返回一個ReadableTable物件,提供讀取一張hive表的能力。HiveMRInput

HiveMRInput實現了IMRInput介面,實現了它的兩個方法。一是HiveTableInputFormat實現了IMRTableInputFormat介面,它主要使用了HCatInputFormat作為MapReduce的輸入格式,用通用的方式讀取所有型別的Hive表。Mapper輸入物件為DefaultHCatRecord,統一轉換為String[]後交由構建引擎處理。

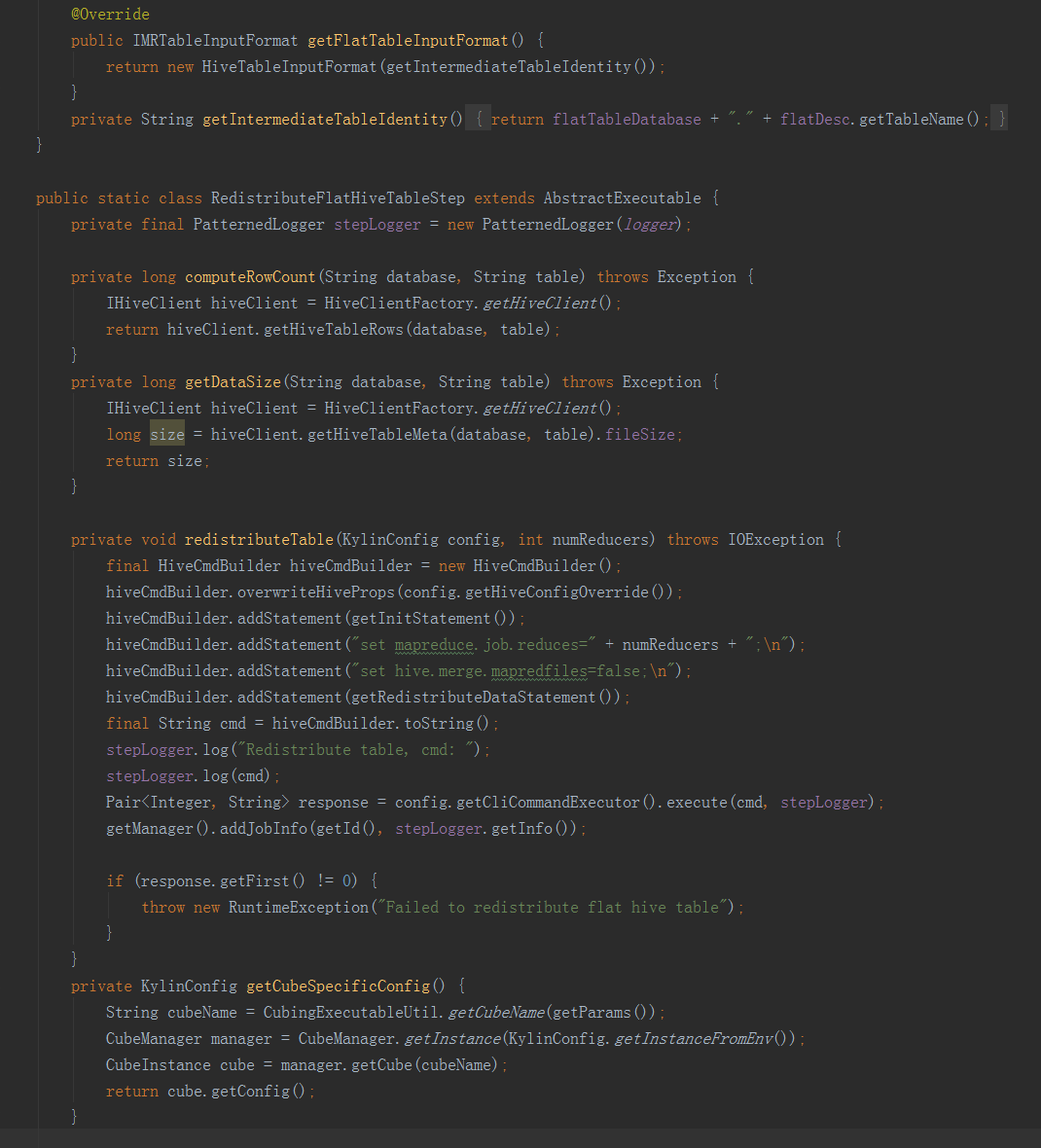
二是BatchCubingInputSide實現了IMRBatchCubingInputSide介面。主要實現了在構建的第一階段建立平表的步驟。首先用count(*)查詢獲取Hive平表的總行數,然後用第二句HQL建立Hive平表,同時新增引數根據總行數分配Reducer數目。
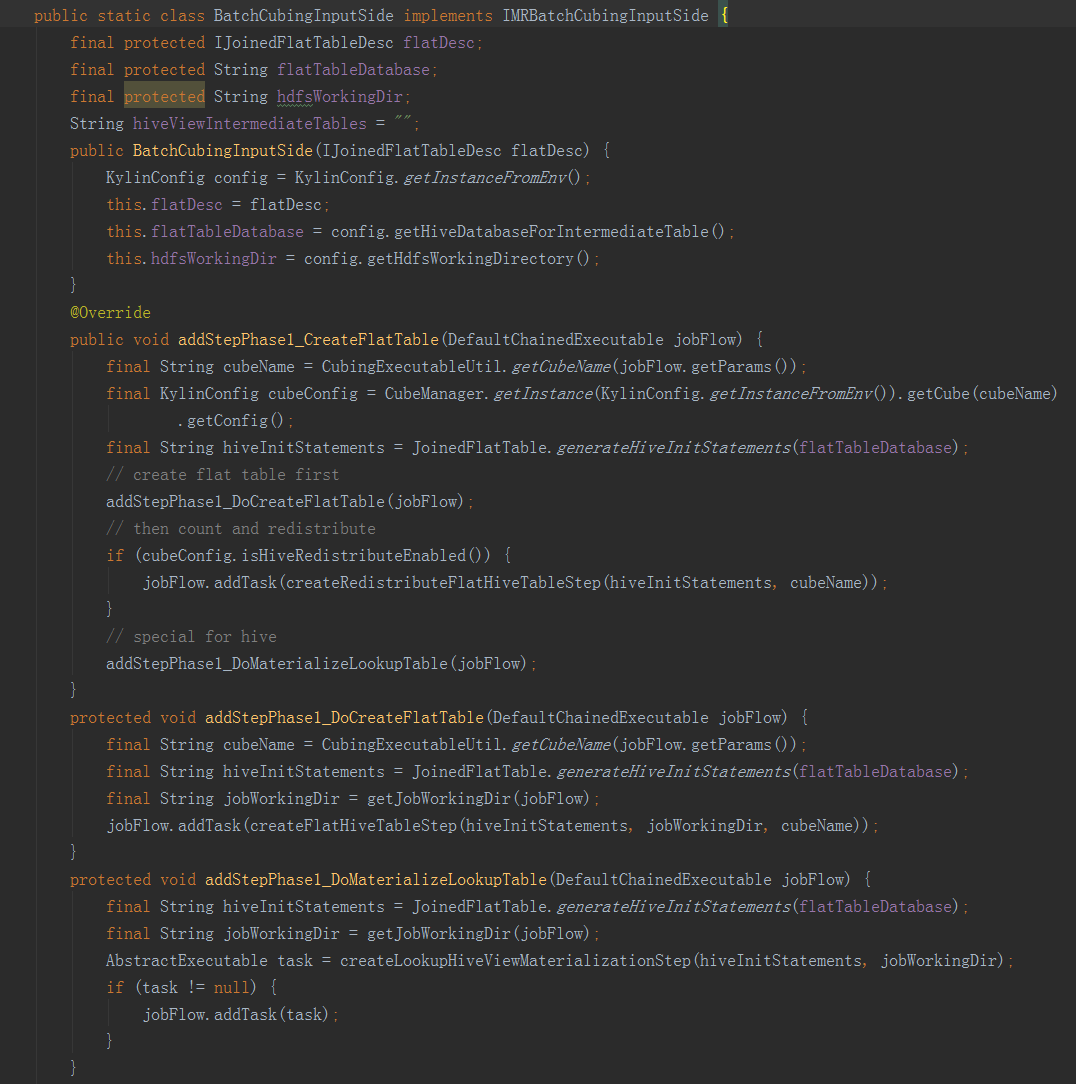


 (三)儲存引擎HBase儲存引擎HBaseStorage實現了IStorage介面。
(三)儲存引擎HBase儲存引擎HBaseStorage實現了IStorage介面。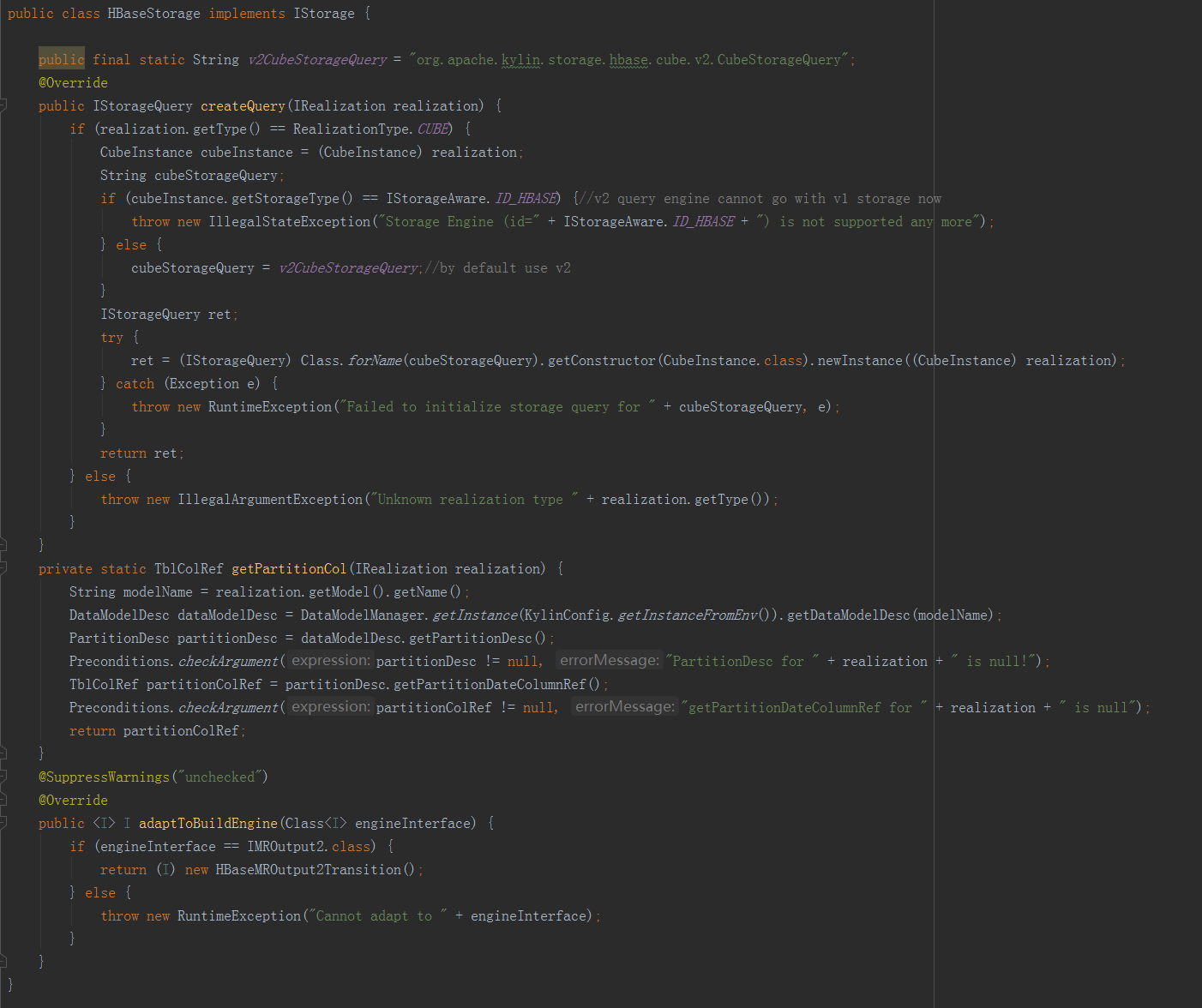
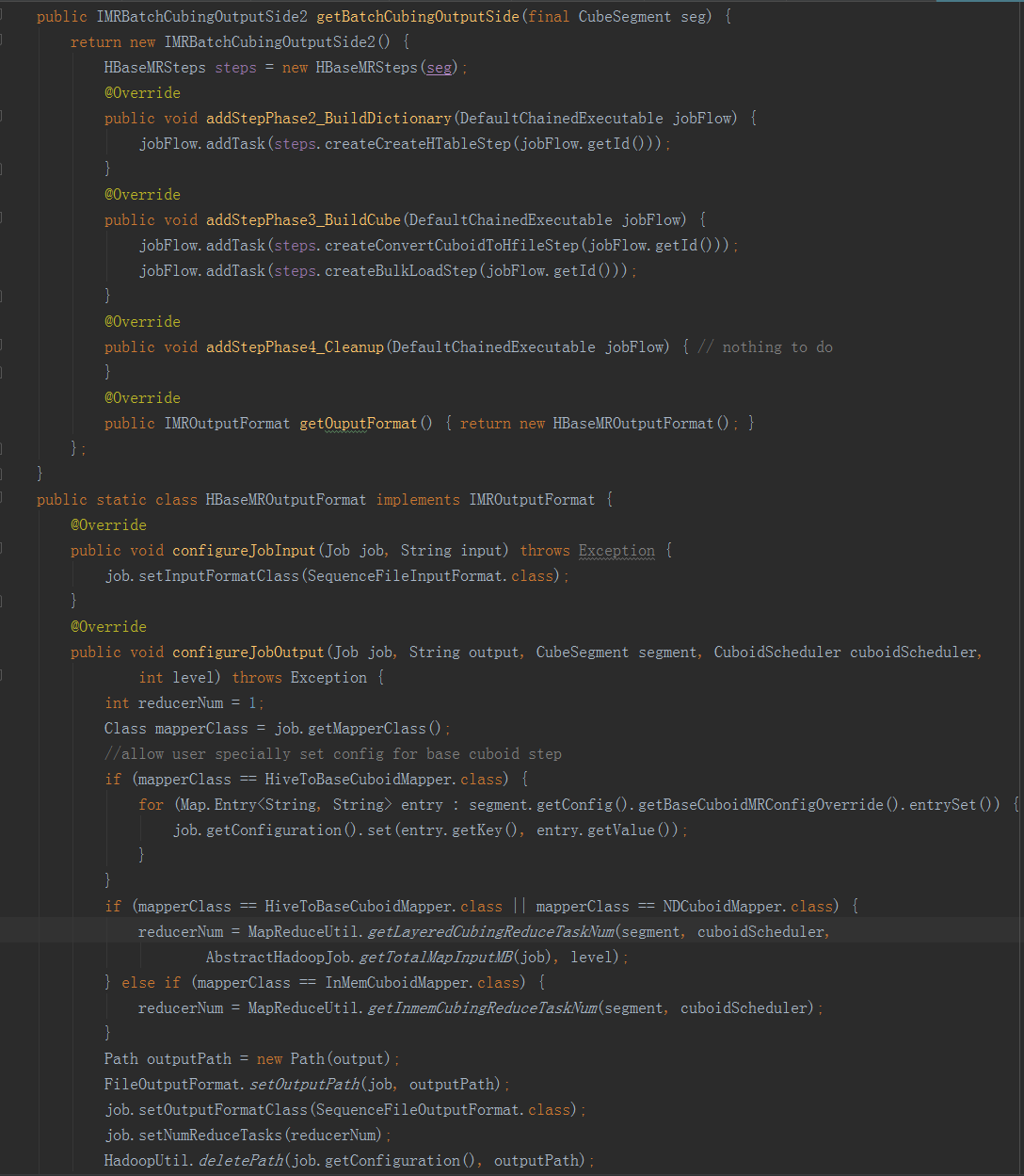 五、CubingJob的構建過程在Kylin構建CubeSegment的過程中,計算引擎居於主導地位,通過它來協調資料來源和儲存引擎。在網頁上向Kylin服務端傳送構建新的CubeSegment的請求後,通過controller層來到service層,進入JobService類中的submitJob方法,方法內部再呼叫submitJobInternal方法,在build、merge和refresh的時候,通過EngineFactory.createBatchCubingJob(newSeg, submitter)返回一個job例項,從這裡可以看出,CubingJob的構建入口是由計算引擎提供的,即預設的計算引擎MRBatchCubingEngine2。
五、CubingJob的構建過程在Kylin構建CubeSegment的過程中,計算引擎居於主導地位,通過它來協調資料來源和儲存引擎。在網頁上向Kylin服務端傳送構建新的CubeSegment的請求後,通過controller層來到service層,進入JobService類中的submitJob方法,方法內部再呼叫submitJobInternal方法,在build、merge和refresh的時候,通過EngineFactory.createBatchCubingJob(newSeg, submitter)返回一個job例項,從這裡可以看出,CubingJob的構建入口是由計算引擎提供的,即預設的計算引擎MRBatchCubingEngine2。


 MRBatchCubingEngine2實現了createBatchCubingJob方法,方法內呼叫了BatchCubingJobBuild2的build方法。
MRBatchCubingEngine2實現了createBatchCubingJob方法,方法內呼叫了BatchCubingJobBuild2的build方法。 在new的初始化過程中,super(newSegment,submitter)就是執行父類的構造方法,進行了一些屬性的初始化賦值,其中的inputSide和outputSide就上上文提到的資料來源和儲存引擎例項,通過計算引擎的協調來進行CubingJob的構建。
在new的初始化過程中,super(newSegment,submitter)就是執行父類的構造方法,進行了一些屬性的初始化賦值,其中的inputSide和outputSide就上上文提到的資料來源和儲存引擎例項,通過計算引擎的協調來進行CubingJob的構建。 資料來源inputSide例項獲取:
資料來源inputSide例項獲取:


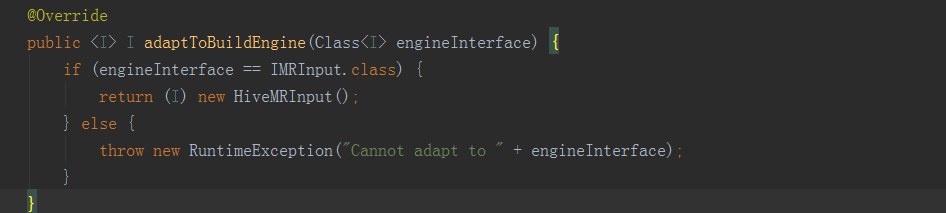 以上即為資料來源例項獲取過程的程式碼展現,BatchCubingJobBuilder2初始化的時候,呼叫MRUtil的getBatchCubingInputSide方法,它最終呼叫的其實還是MRBatchCubingEngine2這個計算引擎的getJoinedFlatTableDesc方法,它返回了一個IJoinedFlatTableDesc例項,這個物件就是對資料來源表資訊的封裝。獲得了這個flatDesc例項之後,就要來獲取inputSide例項,與獲取計算引擎程式碼類似,目前kylin中支援的資料來源有:
以上即為資料來源例項獲取過程的程式碼展現,BatchCubingJobBuilder2初始化的時候,呼叫MRUtil的getBatchCubingInputSide方法,它最終呼叫的其實還是MRBatchCubingEngine2這個計算引擎的getJoinedFlatTableDesc方法,它返回了一個IJoinedFlatTableDesc例項,這個物件就是對資料來源表資訊的封裝。獲得了這個flatDesc例項之後,就要來獲取inputSide例項,與獲取計算引擎程式碼類似,目前kylin中支援的資料來源有: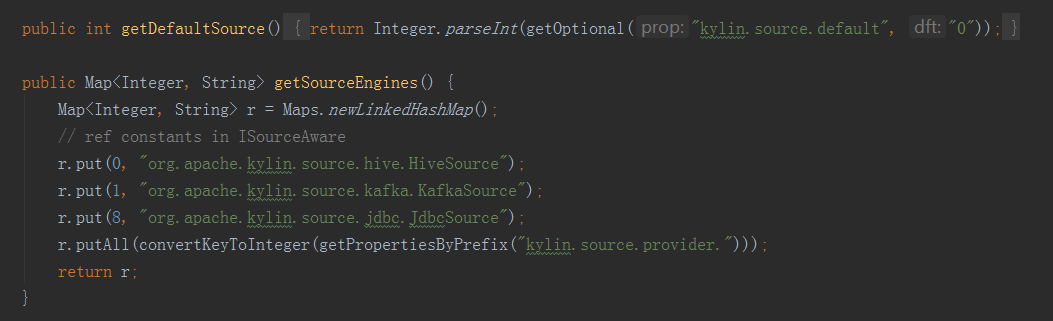




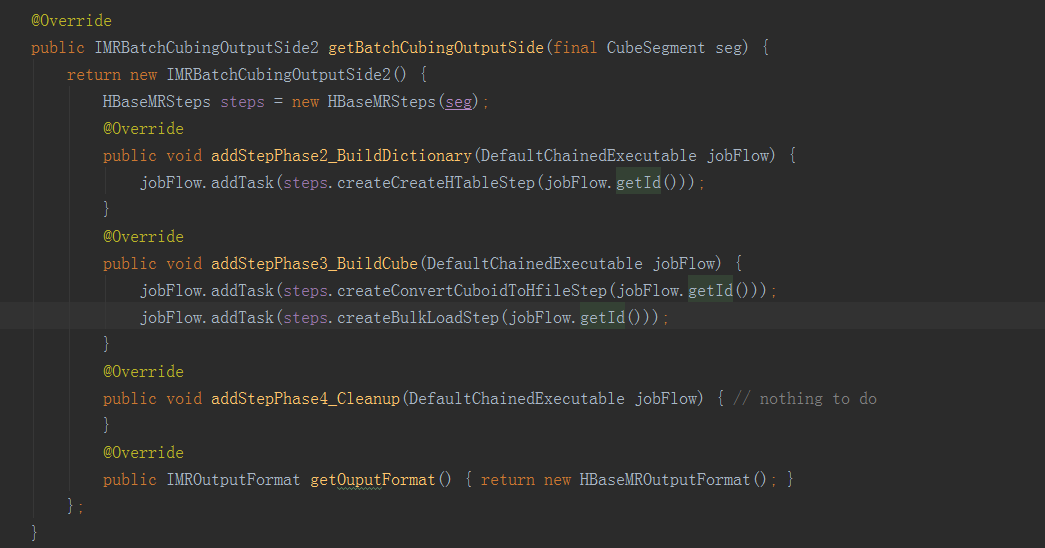

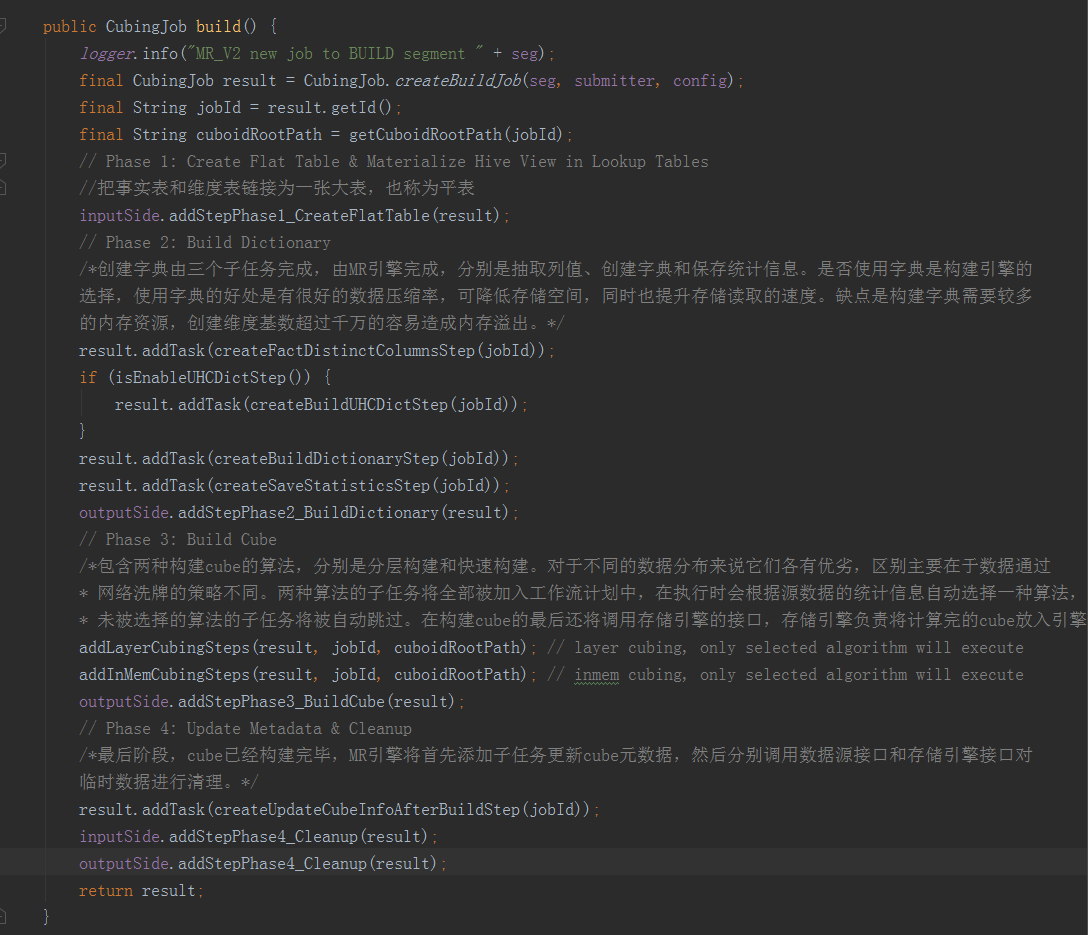
 方法的內容就是構建一個CubeSegment的步驟,依次順序的加入到CubingJob的任務list中。從第一行開始,呼叫了CubingJob的createBuildJob方法,裡面又呼叫了initCubingJob方法。
方法的內容就是構建一個CubeSegment的步驟,依次順序的加入到CubingJob的任務list中。從第一行開始,呼叫了CubingJob的createBuildJob方法,裡面又呼叫了initCubingJob方法。
 initCubingJob方法就是獲取到cube相關的一些配置資訊進行初始化,它是根據cube的名字去查詢所在的project,如果不同的project下建立了相同名字的cube,那返回的就會是一個List,然後看配置檔案中是否開啟了允許cube重名,如不允許則直接丟擲異常,如果允許就在設定projectName時取返回List中的第一個元素,那麼這裡就可能導致projectName設定錯誤,所以最好保證cube的name是全域性唯一的。在CubingJob初始化之後,會獲取cuboidRootPath,獲取邏輯如下:
initCubingJob方法就是獲取到cube相關的一些配置資訊進行初始化,它是根據cube的名字去查詢所在的project,如果不同的project下建立了相同名字的cube,那返回的就會是一個List,然後看配置檔案中是否開啟了允許cube重名,如不允許則直接丟擲異常,如果允許就在設定projectName時取返回List中的第一個元素,那麼這裡就可能導致projectName設定錯誤,所以最好保證cube的name是全域性唯一的。在CubingJob初始化之後,會獲取cuboidRootPath,獲取邏輯如下:




經過一連串的呼叫拼裝,最終獲取的路徑格式如下:hdfs:///kylin/kylin_metadata/kylin-jobId/cubeName/cuboid接下來就是三大引擎相互協作,構建CubeSegment的過程,整個過程大致分為建立hive平表、建立字典、構建Cube和更新元資料和清理這四個步驟。第一步和第四步是由資料來源來實現的,具體是在HiveMRInput類實現了IMRInput介面的getBatchCubingInputSide方法中,它返回了一個BatchCubingInputSide例項,在這個類中完成了具體工作;第二步是由計算引擎實現的,依靠JobBuilderSupport類中的方法完成;第三步是由計算引擎和儲存引擎共同完成的,包括構建cube和儲存到HBase;第四步是由資料來源和儲存引擎分別完成的;我們按步驟對程式碼進行分析。
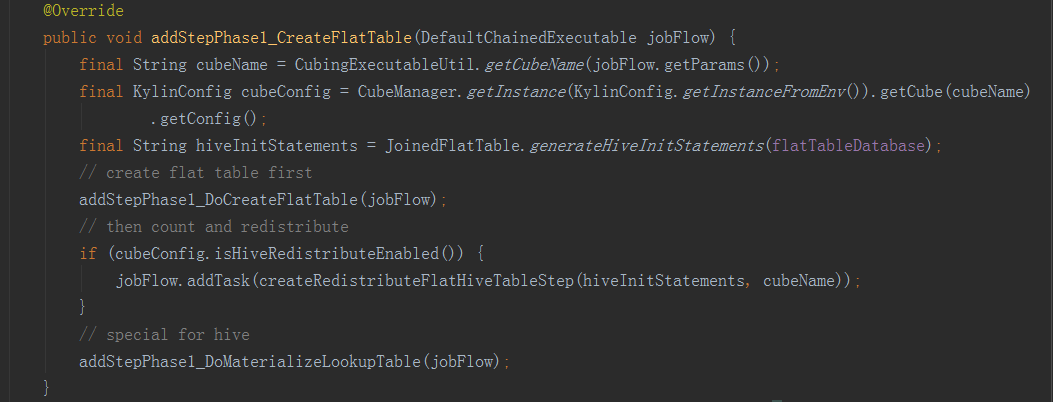
 先獲取cubeName、cubeConfig、hive命令(USE faltTableDatabase)三個變數。
先獲取cubeName、cubeConfig、hive命令(USE faltTableDatabase)三個變數。
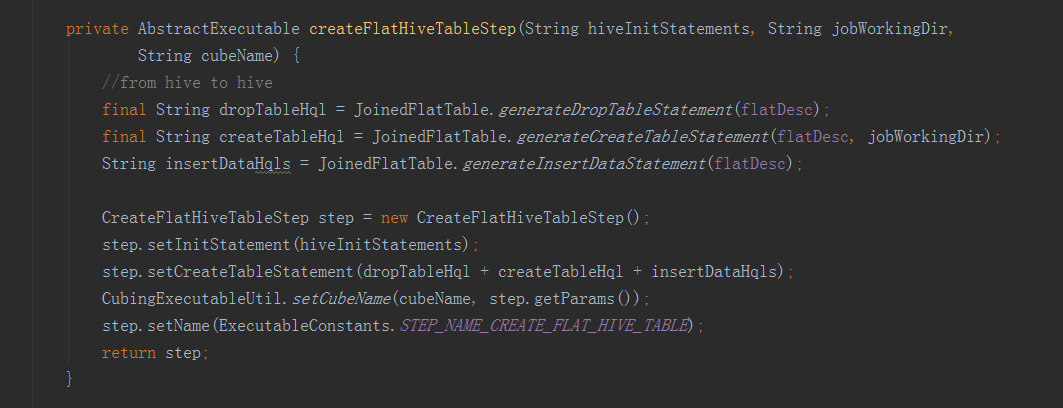

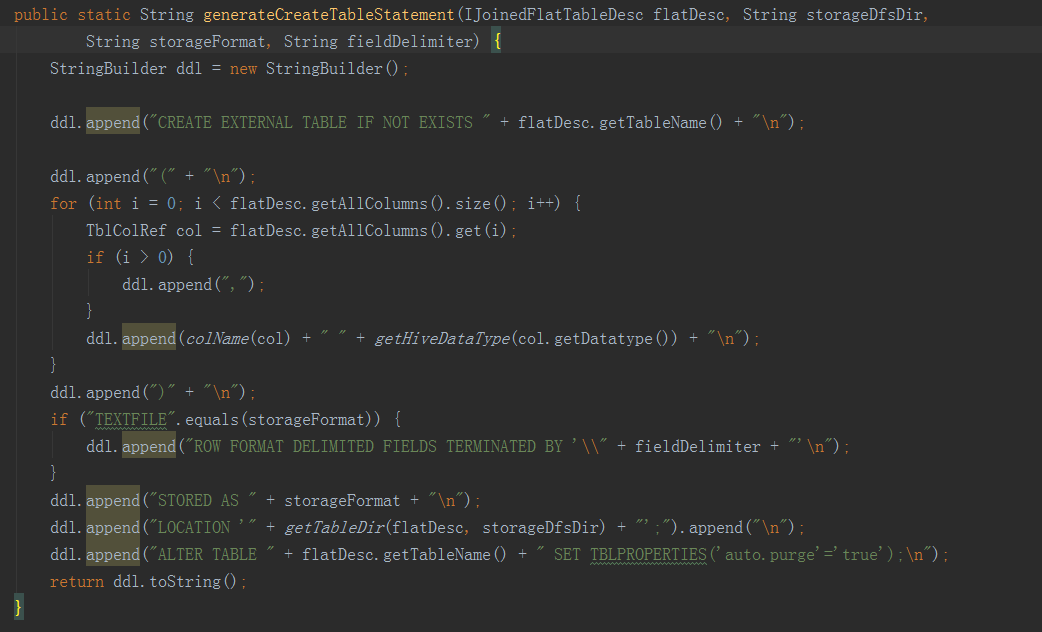
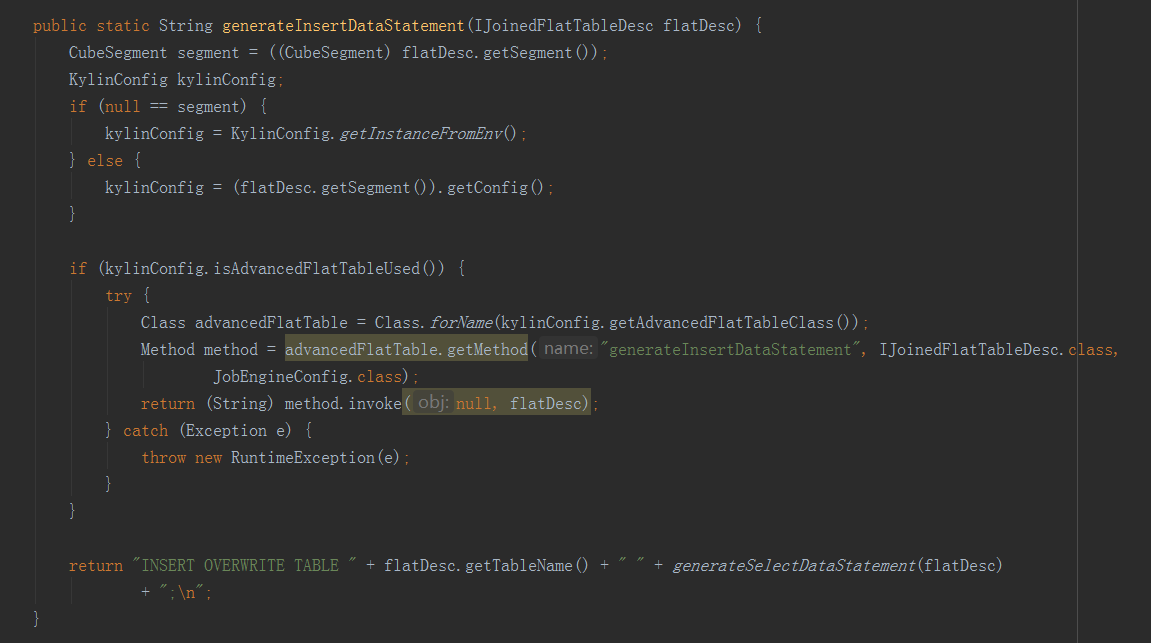
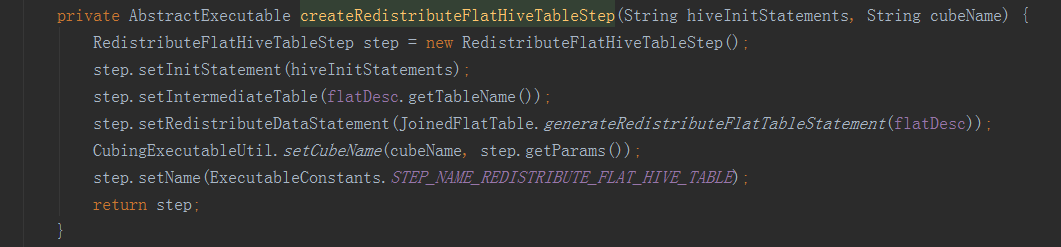


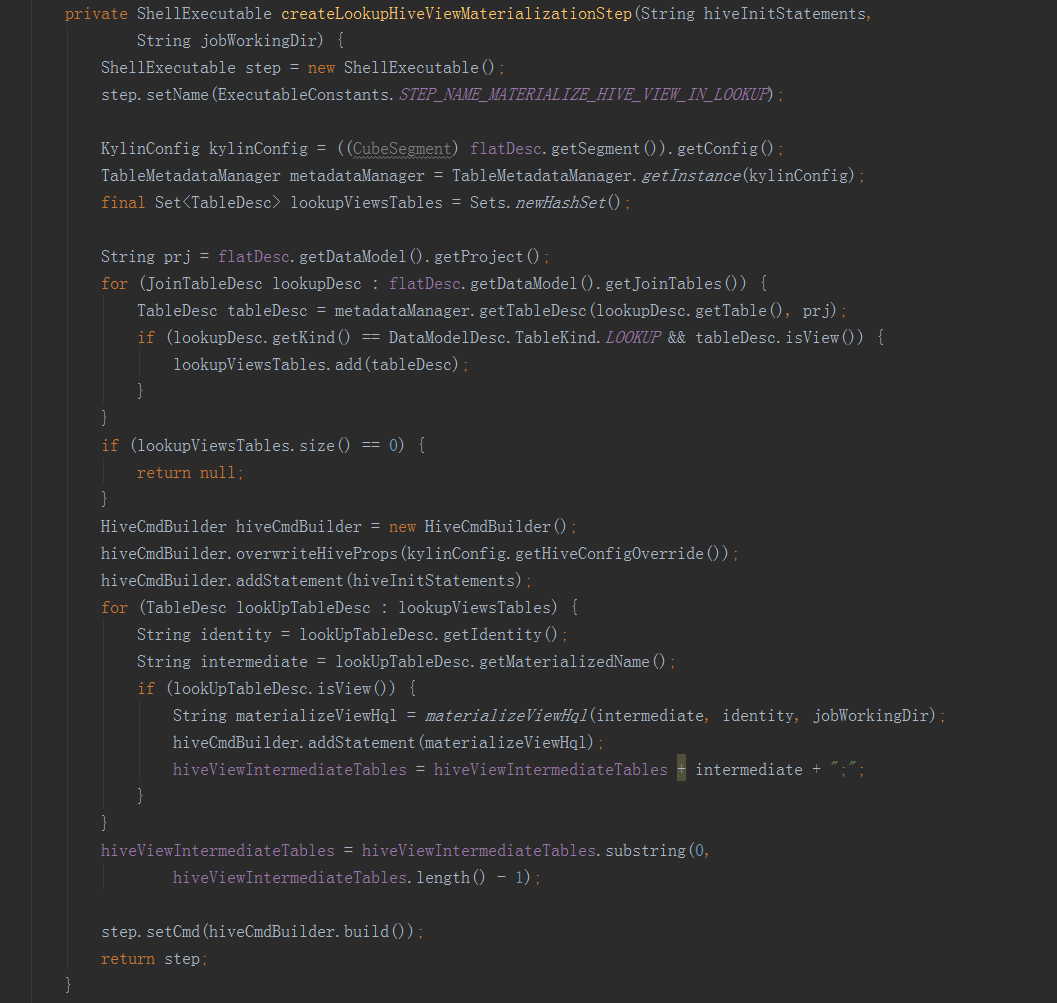
接下來的方法就是抽取變數,進行hive命令的拼接,完成以下步驟:一是從hive表中,將所需欄位從事實表和維表中提取出來,構建一個寬表;二是將上一步得到的寬表,按照某個欄位進行重新分配,如果沒有指定欄位,則隨機,目的是產生多個差不多大小的檔案,作為後續構建任務的輸入,防止資料傾斜。三是將hive中的檢視物化。——————————————————————————————————建立平表命令例子:hive -e "USE default;DROP TABLE IF EXISTS kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d;CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d(TACONFIRM_BUSINESSCODE string,TACONFIRM_FUNDCODE string,TACONFIRM_SHARETYPE string,TACONFIRM_NETCODE string,TACONFIRM_CURRENCYTYPE string,TACONFIRM_CODEOFTARGETFUND string,TACONFIRM_TARGETSHARETYPE string,TACONFIRM_TARGETBRANCHCODE string,TACONFIRM_RETURNCODE string,TACONFIRM_DEFDIVIDENDMETHOD string,TACONFIRM_FROZENCAUSE string,TACONFIRM_TAINTERNALCODE string,TACONFIRM_C_PROVICE string,TAPROVINCE_PROVINCENAME string,TASHARETYPE_SHARETYPENAME string)STORED AS SEQUENCEFILELOCATION 'hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d';ALTER TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SET TBLPROPERTIES('auto.purge'='true');INSERT OVERWRITE TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SELECTTACONFIRM.BUSINESSCODE as TACONFIRM_BUSINESSCODE,TACONFIRM.FUNDCODE as TACONFIRM_FUNDCODE,TACONFIRM.SHARETYPE as TACONFIRM_SHARETYPE,TACONFIRM.NETCODE as TACONFIRM_NETCODE,TACONFIRM.CURRENCYTYPE as TACONFIRM_CURRENCYTYPE,TACONFIRM.CODEOFTARGETFUND as TACONFIRM_CODEOFTARGETFUND,TACONFIRM.TARGETSHARETYPE as TACONFIRM_TARGETSHARETYPE,TACONFIRM.TARGETBRANCHCODE as TACONFIRM_TARGETBRANCHCODE,TACONFIRM.RETURNCODE as TACONFIRM_RETURNCODE,TACONFIRM.DEFDIVIDENDMETHOD as TACONFIRM_DEFDIVIDENDMETHOD,TACONFIRM.FROZENCAUSE as TACONFIRM_FROZENCAUSE,TACONFIRM.TAINTERNALCODE as TACONFIRM_TAINTERNALCODE,TACONFIRM.C_PROVICE as TACONFIRM_C_PROVICE,TAPROVINCE.PROVINCENAME as TAPROVINCE_PROVINCENAME,TASHARETYPE.SHARETYPENAME as TASHARETYPE_SHARETYPENAMEFROM DEFAULT.TACONFIRM as TACONFIRM INNER JOIN DEFAULT.TAPROVINCE as TAPROVINCEON TACONFIRM.C_PROVICE = TAPROVINCE.C_PROVICEINNER JOIN DEFAULT.TASHARETYPE as TASHARETYPEON TACONFIRM.SHARETYPE = TASHARETYPE.SHARETYPEWHERE 1=1;" --hiveconf hive.merge.mapredfiles=false --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.exec.compress.output=true --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf hive.merge.mapfiles=false --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true——————————————————————————————————檔案再分配和檢視物化命令例子:hive -e "USE default;set mapreduce.job.reduces=3;set hive.merge.mapredfiles=false;INSERT OVERWRITE TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SELECT * FROM kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d DISTRIBUTE BY RAND();" --hiveconf hive.merge.mapredfiles=false --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.exec.compress.output=true --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf hive.merge.mapfiles=false --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true——————————————————————————————————
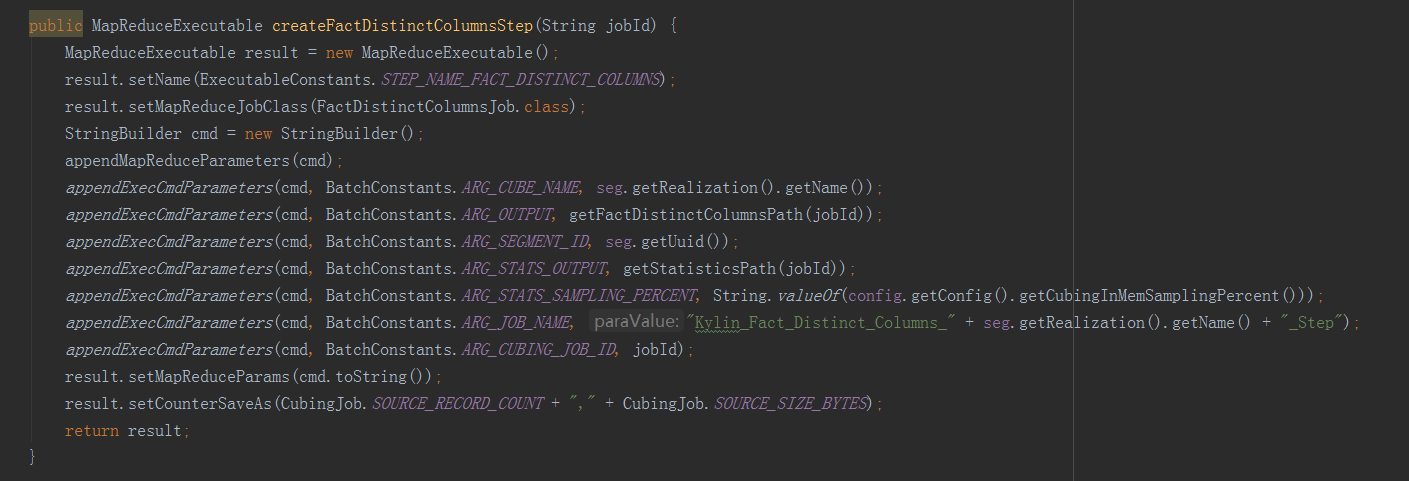








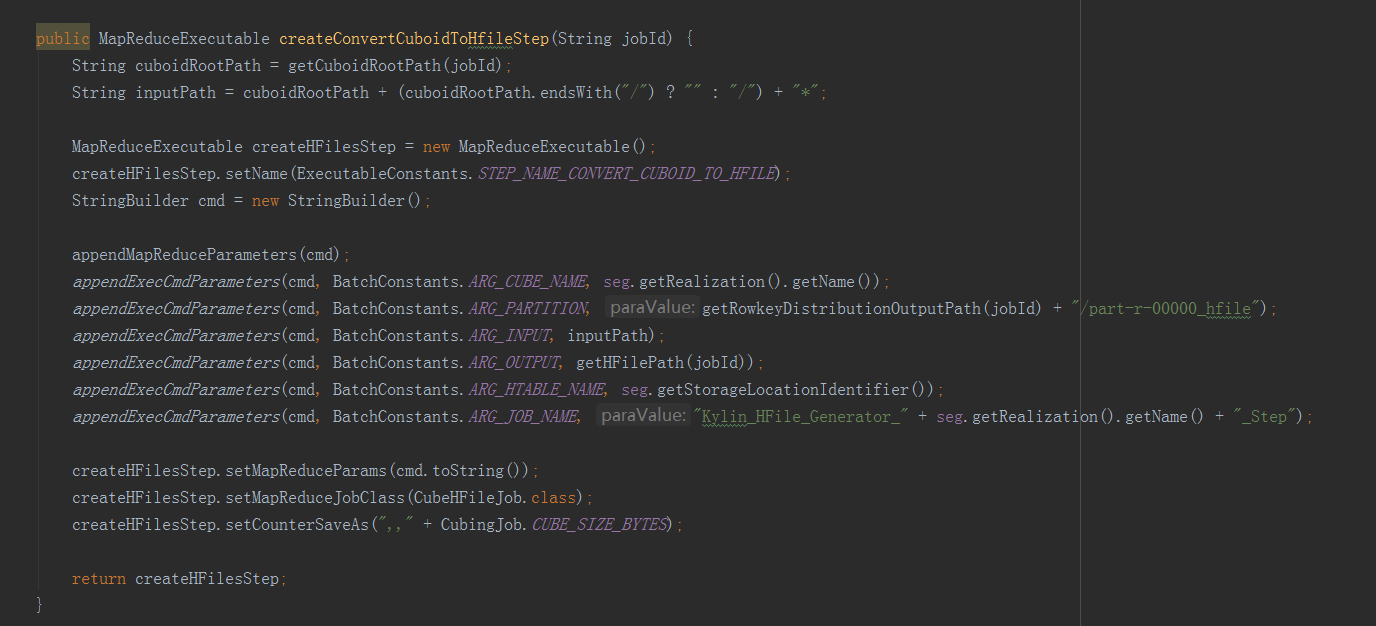
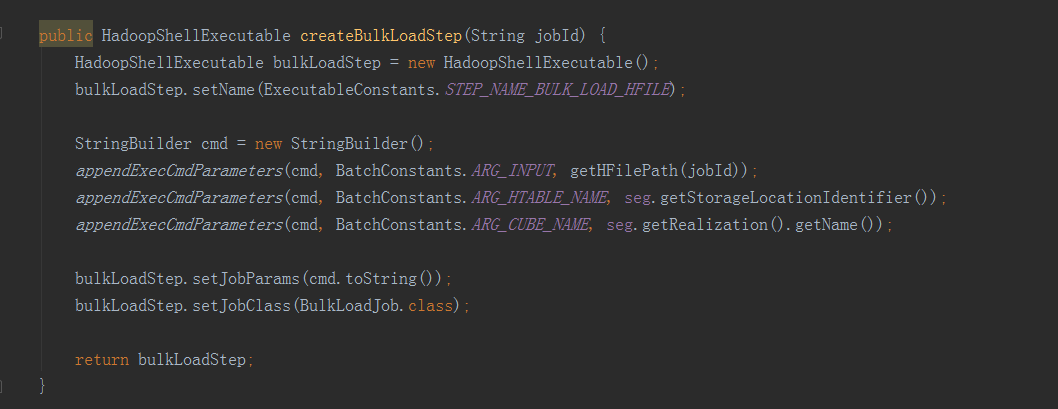 構建Cube屬於計算引擎的任務,就是根據準備好的資料,依次產生cuboid的資料,在這裡呼叫了兩種構建方法,分別是分層構建和快速構建,但最終只會選擇一種構建方法,分層構建首先呼叫createBaseCuboidStep方法,生成Base Cuboid資料檔案,然後進入for迴圈,呼叫createNDimensionCuboidStep方法,根據Base Cuboid計算N層Cuboid資料。在Cuboid的資料都產生好之後,還需要放到儲存層中,所以接下來呼叫outputSide例項的addStepPhase3_BuildCube方法,HBaseMROutput2Transition類中的addStepPhase3_BuildCube方法主要有兩步,一是createConvertCuboidToHfileStep方法,將計算引擎產生的cuboid資料轉換成HBase要求的HFile格式,二是createBulkLoadStep方法,即把HFIle資料載入到HBase中。——————————————————————————————————構建Base Cuboid步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input FLAT_TABLE -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_base_cuboid -jobname Kylin_Base_Cuboid_Builder_kylin_sales_cube -level 0 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811——————————————————————————————————構建N層Cuboid步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_1_cuboid -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_2_cuboid -jobname Kylin_ND-Cuboid_Builder_kylin_sales_cube_Step -level 2 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811——————————————————————————————————轉換HFile格式步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -partitions hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/rowkey_stats/part-r-00000_hfile -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/* -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -jobname Kylin_HFile_Generator_kylin_sales_cube_Step——————————————————————————————————載入HFile到HBase步驟引數例子: -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -cubename kylin_sales_cube——————————————————————————————————
構建Cube屬於計算引擎的任務,就是根據準備好的資料,依次產生cuboid的資料,在這裡呼叫了兩種構建方法,分別是分層構建和快速構建,但最終只會選擇一種構建方法,分層構建首先呼叫createBaseCuboidStep方法,生成Base Cuboid資料檔案,然後進入for迴圈,呼叫createNDimensionCuboidStep方法,根據Base Cuboid計算N層Cuboid資料。在Cuboid的資料都產生好之後,還需要放到儲存層中,所以接下來呼叫outputSide例項的addStepPhase3_BuildCube方法,HBaseMROutput2Transition類中的addStepPhase3_BuildCube方法主要有兩步,一是createConvertCuboidToHfileStep方法,將計算引擎產生的cuboid資料轉換成HBase要求的HFile格式,二是createBulkLoadStep方法,即把HFIle資料載入到HBase中。——————————————————————————————————構建Base Cuboid步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input FLAT_TABLE -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_base_cuboid -jobname Kylin_Base_Cuboid_Builder_kylin_sales_cube -level 0 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811——————————————————————————————————構建N層Cuboid步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_1_cuboid -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_2_cuboid -jobname Kylin_ND-Cuboid_Builder_kylin_sales_cube_Step -level 2 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811——————————————————————————————————轉換HFile格式步驟引數例子: -conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -partitions hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/rowkey_stats/part-r-00000_hfile -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/* -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -jobname Kylin_HFile_Generator_kylin_sales_cube_Step——————————————————————————————————載入HFile到HBase步驟引數例子: -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -cubename kylin_sales_cube——————————————————————————————————
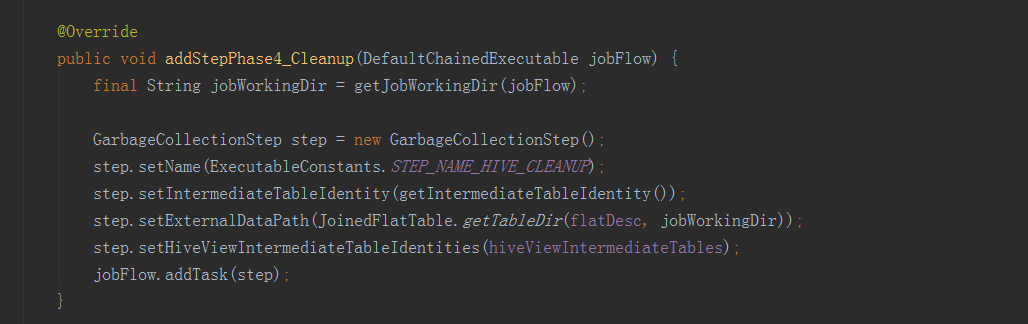
 最後一步就是一些收尾工作,包括更新Cube元資料資訊,呼叫inputSide和outputSide例項進行中間臨時資料的清理工作。
最後一步就是一些收尾工作,包括更新Cube元資料資訊,呼叫inputSide和outputSide例項進行中間臨時資料的清理工作。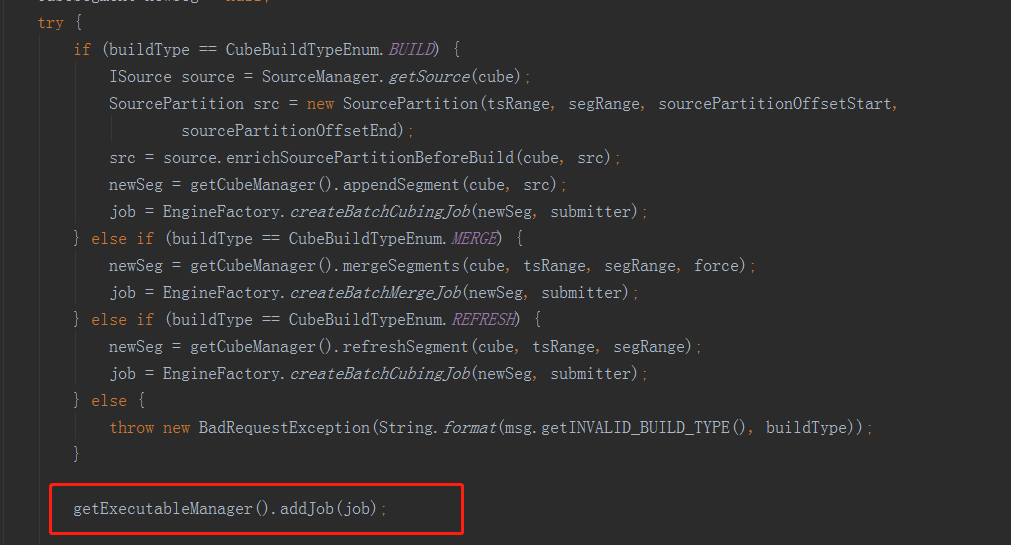 完成所有步驟之後,就回到了JobService的submitJob方法中,在得到CubingJob的例項後,會執行以上程式碼。這裡做的是將CubingJob的資訊物化到HBase的kylin_metadata表中,並沒有真正的提交執行。真正執行CubingJob的地方是在DefaultScheduler,它裡面有一個執行緒會每隔一分鐘,就去HBase的kylin_metadata表中掃一遍所有的CubingJob,然後將需要執行的job,提交到執行緒池執行。kylin中任務的構建和執行是非同步的。單個kylin節點有query、job和all三種角色,query只提供查詢服務,job只提供真正的構建服務,all則兼具前兩者功能。實際操作中kylin的三種角色節點都可以進行CubingJob的構建,但只有all和job模式的節點可以通過DefaultScheduler進行排程執行。
完成所有步驟之後,就回到了JobService的submitJob方法中,在得到CubingJob的例項後,會執行以上程式碼。這裡做的是將CubingJob的資訊物化到HBase的kylin_metadata表中,並沒有真正的提交執行。真正執行CubingJob的地方是在DefaultScheduler,它裡面有一個執行緒會每隔一分鐘,就去HBase的kylin_metadata表中掃一遍所有的CubingJob,然後將需要執行的job,提交到執行緒池執行。kylin中任務的構建和執行是非同步的。單個kylin節點有query、job和all三種角色,query只提供查詢服務,job只提供真正的構建服務,all則兼具前兩者功能。實際操作中kylin的三種角色節點都可以進行CubingJob的構建,但只有all和job模式的節點可以通過DefaultScheduler進行排程執行。相關部落格:https://blog.csdn.net/qq_21653785/article/details/73611423