
spark 大型專案實戰(四十三):運算元調優之reduceByKey本地聚合介紹
下面給出一個圖解:
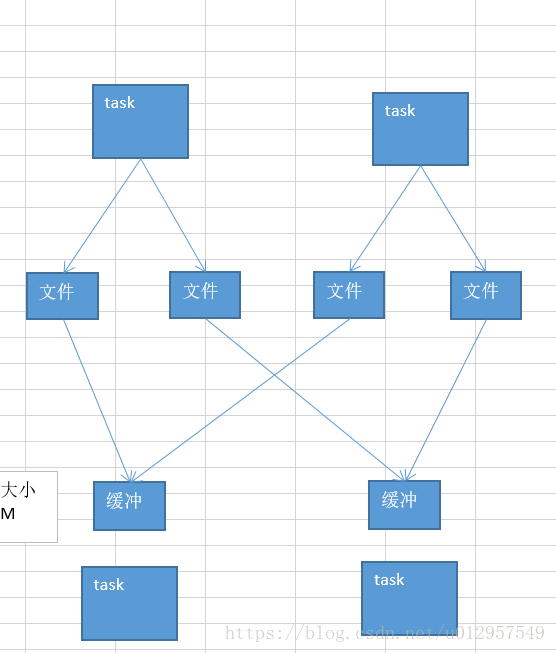
map端的task是不斷的輸出資料的,資料量可能是很大的。
但是,其實reduce端的task,並不是等到map端task將屬於自己的那份資料全部寫入磁碟檔案之後,再去拉取的。map端寫一點資料,reduce端task就會拉取一小部分資料,立即進行後面的聚合、運算元函式的應用。
每次reduece能夠拉取多少資料,就由buffer來決定。因為拉取過來的資料,都是先放在buffer中的。然後才用後面的executor分配的堆記憶體佔比(0.2),hashmap,去進行後續的聚合、函式的執行。
再來說說,reduce端緩衝大小的另外一面,關於效能調優的一面:
咱們假如說,你的Map端輸出的資料量也不是特別大,然後你的整個application的資源也特別充足。200個executor、5個cpu core、10G記憶體。
其實可以嘗試去增加這個reduce端緩衝大小的,比如從48M,變成96M。那麼這樣的話,每次reduce task能夠拉取的資料量就很大。需要拉取的次數也就變少了。比如原先需要拉取100次,現在只要拉取50次就可以執行完了。
對網路傳輸效能開銷的減少,以及reduce端聚合操作執行的次數的減少,都是有幫助的。
最終達到的效果,就應該是效能上的一定程度上的提升。
一定要注意,資源足夠的時候,再去做這個事兒。
reduce端緩衝(buffer),可能會出什麼問題?
可能是會出現,預設是48MB,也許大多數時候,reduce端task一邊拉取一邊計算,不一定一直都會拉滿48M的資料。可能大多數時候,拉取個10M資料,就計算掉了。
大多數時候,也許不會出現什麼問題。但是有的時候,map端的資料量特別大,然後寫出的速度特別快。reduce端所有task,拉取的時候,全部達到自己的緩衝的最大極限值,緩衝,48M,全部填滿。
這個時候,再加上你的reduce端執行的聚合函式的程式碼,可能會建立大量的物件。也許,一下子,記憶體就撐不住了,就會OOM。reduce端的記憶體中,就會發生記憶體溢位的問題。
針對上述的可能出現的問題,我們該怎麼來解決呢?
這個時候,就應該減少reduce端task緩衝的大小。我寧願多拉取幾次,但是每次同時能夠拉取到reduce端每個task的數量,比較少,就不容易發生OOM記憶體溢位的問題。(比如,可以調節成12M)
在實際生產環境中,我們都是碰到過這種問題的。這是典型的以效能換執行的原理。reduce端緩衝小了,不容易OOM了,但是,效能一定是有所下降的,你要拉取的次數就多了。就走更多的網路傳輸開銷。
這種時候,只能採取犧牲效能的方式了,spark作業,首先,第一要義,就是一定要讓它可以跑起來。分享一個經驗,曾經寫過一個特別複雜的spark作業,寫完程式碼以後,半個月之內,就是跑不起來,裡面各種各樣的問題,需要進行troubleshooting。調節了十幾個引數,其中就包括這個reduce端緩衝的大小。總算作業可以跑起來了。
然後才去考慮效能的調優。
spark.reducer.maxSizeInFlight,48
spark.reducer.maxSizeInFlight,24