
PL/SQL效能優化技巧
1、理解執行計劃
1-1.什麼是執行計劃
Oracle資料庫在執行sql語句時,oracle的優化器會根據一定的規則確定sql語句的執行路徑,以確保sql語句能以最優效能執行.在oracle資料庫系統中為了執行sql語句,oracle可能需要實現多個步驟,這些步驟中的每一步可能是從資料庫中物理檢索資料行,或者用某種方法準備資料行,讓編寫sql語句的使用者使用,oracle用來執行語句的這些步驟的組合被稱為執行計劃。
當執行一個sql語句時oracle經過了4個步驟:
①.解析sql語句:主要在共享池中查詢相同的sql語句,檢查安全性和sql語法與語義。
②.建立執行計劃及執行:包括建立sql語句的執行計劃及對錶資料的實際獲取。
③.顯示結果集:對欄位資料執行所有必要的排序,轉換和重新格式化。
④.轉換欄位資料:對已通過內建函式進行轉換的欄位進行重新格式化處理和轉換.
1-2.檢視執行計劃
檢視sql語句的執行計劃,比如一些第三方工具 需要先執行utlxplan.sql指令碼建立explain_plan表。
- SQL> conn system/123456 as sysdba
- -- 如果下面語句沒有執行成功,可以找到這個檔案,單獨執行這個檔案裡的建表語句
- SQL> @/rdbms/admin/utlxplan.sql
- SQL> grantallon sys.plan_table topublic;
set autotrace on explain:執行sql,且僅顯示執行計劃
set autotrace on statistics:執行sql 且僅顯示執行統計資訊
set autotrace on :執行sql,且顯示執行計劃與統計資訊,無執行結果
set autotrace traceonly:僅顯示執行計劃與統計資訊,無執行結果
set autotrace off:關閉跟蹤顯示計劃與統計
比如要執行SQL且顯示執行計劃,可以使用如下的語句:
- SQL> set autotrace on explain
-
SQL> col ename format a20;
- SQL> select empno,ename from emp where empno=7369;
- SQL> explain plan for
- 2 select * from cfreportdata where outitemcode='CR04_00160'and quarter='1'andmonth='2015';
- Explained
- SQL> select * fromtable(dbms_xplan.display);
- PLAN_TABLE_OUTPUT
- --------------------------------------------------------------------------------
- Plan hash value: 3825643284
- --------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%C
- --------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 115 | 3
- | 1 | TABLE ACCESS BYINDEX ROWID| CFREPORTDATA | 1 | 115 | 3
- |* 2 | INDEX RANGE SCAN | PK_CFREPORTDATA | 1 | | 2
- --------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("OUTITEMCODE"='CR04_00160'AND"MONTH"='2015'AND"QUARTER"='1')
- filter("MONTH"='2015'AND"QUARTER"='1')
- 15 rows selected
PL/SQL DEVELOPER提供了一個執行計劃視窗,如果在SQL Windows的視窗,按F8是執行該sql,按f5會顯示該sql的執行計劃。
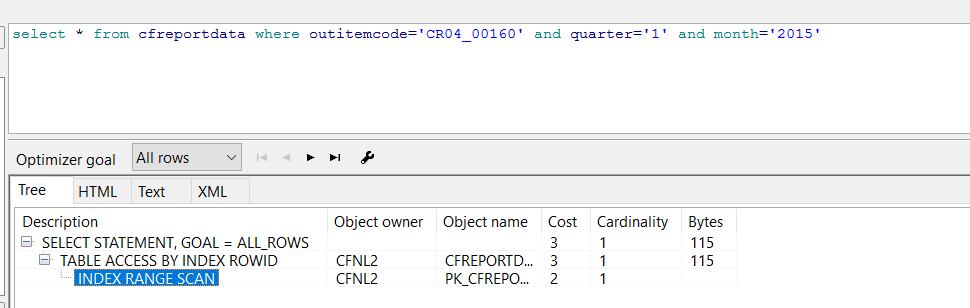
3.理解執行計劃
1.全表掃描(full table scans):這種方式會讀取表中的每一條記錄,順序地讀取每一個數據塊直到結尾標誌,對於一個大的資料表來說,使用全表掃描會降低效能,但有些時候,比如查詢的結果佔全表的資料量的比例比較高時,全表掃描相對於索引選擇又是一種較好的辦法。
2.通過ROWID值獲取(table access by rowid):行的rowid指出了該行所在的資料檔案,資料塊及行在該塊中的位置,所以通過rowid來存取資料可以快速定位到目標資料上,是oracle存取單行資料的最快方法。
3.索引掃描(index scan):先通過索引找到物件的rowid值,然後通過rowid值直接從表中找到具體的資料,能大大提高查詢的效率。
2.連線查詢的表順序
預設情況下,優化器會使用all_rows優化方式,也就是基於成本的優化器CBO生成執行計劃,CBO方式會根據統計資訊來產生執行計劃.
統計資訊給出表的大小,多少行,每行的長度等資訊,這些統計資訊起初在庫內是沒有的,是做analyee後才發現的,很多時候過期統計資訊會令優化器做出一個錯誤的執行計劃,因此應及時更新這些資訊。
在CBO模式下,當對多個表進行連線查詢時,oracle分析器會按照從右到左的順序處理from子句中的表名。例如:
- select a.empno,a.ename,c.deptno,c.dname,a.log_action from emp_log a,emp b,dept c
如果有3個以上的表連線查詢,就需要選擇交叉表作為基礎表。交叉表是指那個被其他表所引用的表,由於emp_log是dept與emp表中的交叉表,既包含dept的內容又包含emp的內容。
- select a.empno,a.ename,c.deptno,c.dname,a.log_action from emp b,dept c,emp_log a;
3.指定where條件順序
在查詢表時,where子句中條件的順序往往影響了執行的效能。預設情況下,oracle採用自下而上的順序解析where子句,因此在處理多表查詢時,表之間的連線必須寫在其他的where條件之前,但是過濾資料記錄的條件則必須寫在where子句的尾部,以便在過濾了資料之後再進行連線處理,這樣可以提升sql語句的效能。
- SELECT a.empno, a.ename, c.deptno, c.dname, a.log_action, b.sal
- FROM emp b, dept c, emp_log a
- WHERE a.deptno = b.deptno AND a.empno=b.empno AND c.deptno IN (20, 30)
- SELECT a.empno, a.ename, c.deptno, c.dname, a.log_action, a.mgr
- FROM emp b, dept c, emp_log a
- WHERE c.deptno IN (20, 30) AND a.deptno = b.deptno
4.避免使用*符號
有時我們習慣使用*符號,如
- SELECT * FROM emp
5.使用decode函式
是Oracle才具有的一個功能強大的函式
比如統計emp表中部門編號為20和部門編號為30的員工的人數和薪資彙總,如果不使用decode那麼就必須用兩條sql語句
- selectcount(*),SUM(sal) from emp where deptno=20;
- union
- selectcount(*),SUM(sal) from emp where deptno=30;
通過decode語句,可以再一個sql查詢中獲取到相同的結果,並且將兩行結果顯示為單行。
- SELECTCOUNT (DECODE (deptno, 20, 'X', NULL)) dept20_count,
- COUNT (DECODE (deptno, 30, 'X', NULL)) dept30_count,
- SUM (DECODE (deptno, 20, sal, NULL)) dept20_sal,
- SUM (DECODE (deptno, 30, sal, NULL)) dept30_sal
- FROM emp;
6.使用where而非having
where子句和having子句都可以過濾資料,但是where子句不能使用聚集函式,如count max min avg sum等函式。因此通常將Having子句與Group By子句一起使用
注意:當利用Group By進行分組時,可以沒有Having子句。但Having出現時,一定會有Group By
需要了解的是,WHERE語句是在GROUP BY語句之前篩選出記錄,而HAVING是在各種記錄都篩選之後再進行過濾。也就是說HAVING子句是在從資料庫中提取資料之後進行篩選的,因此在編寫SQL語句時,儘量在篩選之前將資料使用WHERE子句進行過濾,因此執行的順序應該總是這樣。
①.使用WHERE子句查詢符合條件的資料
②.使用GROUP BY子句對資料進行分組。
③.在GROUP BY分組的基礎上執行聚合函式計算每一組的值
④.用HAVING子句去掉不符合條件的組。
例子:查詢部門20和30的員工薪資總數大於1000的員工資訊
- select empno,deptno,sum(sal)
- from emp groupby empno,deptno
- havingsum(sal) > 1000 and deptno in (20,30);
- select empno,deptno,sum(sal)
- from emp where deptno in (20,30)
- groupby empno,deptno havingsum (sal) > 1000;
7.使用UNION而非OR
如果要進行OR運算的兩個列都是索引列,可以考慮使用union來提升效能。
例子:比如emp表中,empno和ename都建立了索引列,當需要在empno和ename之間進行OR操作查詢時,可以考慮將這兩個查詢更改為union來提升效能。
- select empno,ename,job,sal from emp where empno > 7500 OR ename LIKE 'S%';
- select empno,ename,job,sal from emp where empno > 7500
- UNION
-
select empno,ename,job,sal
相關推薦
PL/SQL效能優化技巧
1、理解執行計劃 1-1.什麼是執行計劃 Oracle資料庫在執行sql語句時,oracle的優化器會根據一定的規則確定sql語句的執行路徑,以確保sql語句能以最優效能執行.在oracle資料庫系統中為了執行sql語句,oracle可能需要實現多個步
PL/SQL Developer使用技巧(部分)
技巧 gin sel mar png ctrl+ chan 編譯 margin PL/SQL Developer使用技巧(部分) 關鍵字自動大寫 在sql命令窗口中輸入SQL語句時,想要關鍵字自動大寫,引人註目該怎麽辦呢? 一步設置就可以達成了。點擊Tools
30個MySQL千萬級大數據SQL查詢優化技巧詳解
!= 結果 exist 進行 cluster date 有意義 參數 rop 本文總結了30個mysql千萬級大數據SQL查詢優化技巧,特別適合大數據裏的MYSQL使用。 1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建
PL/SQL Developer使用技巧(轉)
1、PL/SQL Developer記住登陸密碼 在使用PL/SQL Developer時,為了工作方便希望PL/SQL Developer記住登入Oracle的使用者名稱和密碼; 設定方法:PL/SQL Developer 7.1.2 ->tools->Prefer
sql效能優化第二篇之mybatis如何能夠執行多條sql
在第一篇基礎上,資料庫能夠成功執行語句,但是放到Java程式碼中會報錯有木有。 原來,mybatis在我們使用連結連線資料庫時,需要我們手動在連線上加上程式碼: &allowMultiQueries=true //允許執行多條sql 寫全就是:spring.datasour
sql效能優化第一篇之分頁資料與count資料一次性獲取
相信大部分人都會遇到:在資料庫的資料量很大時,分頁需要幾秒鐘才會全部完成;包括分頁list的獲取和count的獲取。那我們完全可以將這兩步放到一次sql去執行獲取,減少一半的查詢時間。這裡get到sql_calc_found_rows和SELECT FOUND_ROWS()這兩個知識點。看程式碼
sql效能優化,資料庫面試
SQL 效能優化 總結 (1)選擇最有效率的表名順序(只在基於規則的優化器中有效): ORACLE的解析器按照從右到左的順序處理FROM子句中的表名,FROM子句中寫在最後的表(基礎表 driving table)
Java效能優化技巧集錦
一、通用篇 “通用篇”討論的問題適合於大多數Java應用。 1.1 不用new關鍵詞建立類的例項 用new關鍵詞建立類的例項時,建構函式鏈中的全部建構函式都會被自己主動呼叫。但假設一個物件實現了Cloneable介面。我們能夠呼叫它的clone()方法。 clone
【Egret優化分享】白鷺引擎王澤:重度H5遊戲效能優化技巧
本文轉自:https://mp.weixin.qq.com/s/GIzXA51D7_hMqajCRuJE2g 9月15日,無懼17級颱風“山竹”,320名開發者齊聚廣州貝塔空間共同探討“怎樣做一款賺錢的小遊戲”。針對眾多開發者關心的重度H5遊戲效能優化技巧,我們整理了現場速記分享給
微信小程式效能優化技巧
摘要: 如果小程式不夠快,還要它幹嘛? 原文:微信小程式效能優化方案——讓你的小程式如此絲滑 作者:杜俊成要好好學習 Fundebug經授權轉載,版權歸原作者所有。 微信小程式如果想要優化效能,有關鍵性的兩點: 提高載入效能 提高渲染效能 接下來分別來介紹一下: 提高載
SQL效能優化(不斷總結)
1.查詢的模糊匹配 儘量避免在一個複雜查詢裡面使用 LIKE '%parm1%'—— 紅色標識位置的百分號會導致相關列的索引無法使用,最好不要用. 解決辦法: 其實只需要對該指令碼略做改進,查詢速度便會提高近百倍。改進方法如下: &nbs
SQL 效能優化 總結
SQL 效能優化 總結 (1)選擇最有效率的表名順序(只在基於規則的優化器中有效): ORACLE的解析器按照從右到左的順序處理FROM子句中的表名,FROM子句中寫在最後的表(基礎表 driving table)
Oracle SQL效能優化的40條軍規 Oracle SQL效能優化的40條軍規
Oracle SQL效能優化的40條軍規 1. SQL語句執行步驟 語法分析> 語義分析> 檢視轉換 >表示式轉換> 選擇優化器 >選擇連線方式 >選擇連線順序 >選擇資料的搜尋路徑 >執行“執行計劃” 2. 選
Java程式設計效能優化技巧,乾貨分享!
Java程式設計效能優化技巧,乾貨分享! 此時靜態變數b的生命週期與A類同步,如果A類不會解除安裝,那麼b物件會常駐記憶體,直到程式終止。 3儘量避免過多過常的建立Java物件 儘量避免在經常呼叫的方法,迴圈中new物件,由於系統不僅要花費時間來建立物件,而且還要花時間對這些
SQL效能優化十條經驗,後臺程式設計師都需要掌握
1.查詢的模糊匹配儘量避免在一個複雜查詢裡面使用 LIKE '%parm1%'—— 紅色標識位置的百分號會導致相關列的索引無法使用,最好不要用.解決辦法:其實只需要對該指令碼略做改進,查詢速度便會提高近百倍。改進方法如下:a、修改前臺程式——把查詢條件的供應商名稱一欄由原來的文字輸入改為下拉列表,使用者模糊輸
面試被問之-----sql優化中in與exists的區別 Mysql中 in or exists not exists not in區別 (網路整理) Sql語句中IN和exists的區別及應用 [筆記] SQL效能優化 - 避免使用 IN 和 NOT IN
曾經一次去面試,被問及in與exists的區別,記得當時是這麼回答的:''in後面接子查詢或者(xx,xx,xx,,,),exists後面需要一個true或者false的結果",當然這麼說也不算錯,但別人想聽的是sql優化相關,肯定是效率的問題,只是那個時候確實不知道它們在sql優化上的區別,只知道用in會進
白鷺引擎王澤:重度H5遊戲效能優化技巧
9月15日,無懼17級颱風“山竹”,320名開發者齊聚廣州貝塔空間共同探討“怎樣做一款賺錢的小遊戲”。針對眾多開發者關心的重度H5遊戲效能優化技巧,我們整理了現場速記分享給大家,詳見下文: 王澤:各位開發者下午好!我叫王澤,是白鷺引擎的首席架構師。 今天給大家分享的
PL/SQL教程:PL/SQL Developer使用技巧
1、PL/SQL Developer記住登陸密碼 在使用PL/SQL Developer時,為了工作方便希望PL/SQL Developer記住登入Oracle的使用者名稱和密碼; 設定方法:tools->Preferences->Oracle-&
Oracle SQL效能優化 - 根據大表關聯更新小表
需求: 小表資料量20w條左右,大表資料量在4kw條左右,需要根據大表篩選出150w條左右的資料並關聯更新小表中5k左右的資料。 效能問題: 對篩選條件中涉及的欄位加index後,如下常規的update語句仍耗時半小時左右。 UPDATE WMOCDCREPORT.DM_WM_TRADI
Oracle SQL效能優化的40條軍規
1. SQL語句執行步驟 語法分析> 語義分析> 檢視轉換 >表示式轉換> 選擇優化器 >選擇連線方式 >選擇連線順序 >選擇資料的搜尋路徑 >執行“執行計劃” 2. 選用適合的Oracle優化器 RULE(基於規則) COST