
CSDN爬蟲(二)——部落格列表分頁爬蟲+資料表設計
CSDN爬蟲(二)——部落格列表分頁爬蟲+資料庫設計
說明
- 開發環境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬蟲框架:webMagic
- 建議:建議首先閱讀webMagic的文件,再檢視此係列文章,便於理解,快速學習:http://webmagic.io/
- 開發所需jar下載(不包括資料庫操作相關jar包):點我下載
- 該系列文章會省略webMagic文件已經講解過的相關知識。
部落格列表爬蟲核心程式碼預覽
package com.wgyscsf.spider; import java.util.List; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.selector.Html; import us.codecraft.webmagic.selector.Selectable; import com.wgyscsf.utils.MyStringUtils; /** * @author wgyscsf</n> 編寫日期 2016-9-24下午7:25:36</n> 郵箱[email protected]</n> 部落格 * http://blog.csdn.net/wgyscsf</n> TODO</n> */ public class CsdnBlogListSpider extends BaseSpider { private Site site = Site .me() .setDomain("blog.csdn.net") .setSleepTime(300) .setUserAgent( "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31"); @Override public void process(Page page) { // 列表頁: 這裡進行匹配,匹配出列表頁進行相關處理。在列表頁我們獲取必要資訊。對於全文、評論、頂、踩在文章詳情中。 if ((page.getUrl()).regex( "^http://blog.csdn.net/\\w+/article/list/[0-9]*[1-9][0-9]*$") .match()) { // 遍歷出頁碼:遍歷出div[@class=\"pagelist\"]節點下的所有超連結,該連結下是頁碼連結。將其加入到爬蟲佇列。【核心程式碼】 page.addTargetRequests(page .getHtml() .xpath("//div[@class=\"list_item_new\"]//div[@class=\"pagelist\"]") .links().all()); // 作者 Selectable links = page.getHtml() .xpath("//div[@class=\"header\"]//div[@id=\"blog_title\"]") .links(); String blogUrl = links.get(); String id_author = MyStringUtils.getLastSlantContent(blogUrl); id_author = id_author != null ? id_author : "獲取作者id失敗"; // System.out.println(TAG + author); // 獲取列表最外層節點的所有子節點。經過分析可以知道子節點有3個,“置頂文章”列表和“普通文章列表”和分頁div。 List<String> out_div = page.getHtml() .xpath("//div[@class=\"list_item_new\"]/div").all(); // 判斷是否存在置頂文章:如何div的個數為3說明存在置頂文章,否則不存在置頂文章。 if (out_div.size() == 3) { // 存在 processTopArticle(out_div.get(0), id_author); processCommArticle(out_div.get(1), id_author); } else if (out_div.size() == 2) { // 不存在 processCommArticle(out_div.get(0), id_author); } else { System.err.println(TAG + ":邏輯出錯"); } } else if (page.getUrl() .regex("http://blog.csdn.net/\\w+/article/details/\\w+") .match()) { // 這裡的邏輯還沒處理,主要是為了獲取全文、標籤、頂、踩、評論等在列表頁獲取不到的資料 } } /** * 處理普通文章列表 */ private void processCommArticle(String str, String id_author) { // 從列表頁獲取列表資訊 List<String> all; all = new Html(str).xpath("//div[@id=\"article_list\"]/div").all(); if (!all.isEmpty()) for (String string : all) { // 這裡開始獲取具體內容 // 單項第一部分:article_title // 文章地址 String detailsUrl = new Html(string) .xpath("//div[@class='article_title']//span[@class='link_title']//a/@href") .toString(); // 文章id String id_blog = MyStringUtils.getLastSlantContent(detailsUrl); // 文章標頭 String title = new Html(string) .xpath("//div[@class='article_title']//span[@class='link_title']//a/text()") .toString(); // 文章型別 String type = getArticleType(string); // 單項第二部分:article_description String summary = new Html(string).xpath( "//div[@class='article_description']//text()") .toString(); // 單項第三部分:article_manage String publishDateTime = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_postdate']//text()") .toString(); // 閱讀量 String viewNums = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_view']//text()") .toString(); viewNums = MyStringUtils.getStringPureNumber(viewNums); // 評論數 String commentNums = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_comments']//text()") .toString(); commentNums = MyStringUtils.getStringPureNumber(commentNums); // 開始組織資料 System.out.println(TAG + ":,文章id:" + id_blog + ",文章標頭:" + title + ",文章型別('0':原創;'1':轉載;'2':翻譯):" + type + ",發表日期:" + publishDateTime + ",閱讀量:" + viewNums + ",評論數:" + commentNums + ",文章地址:" + detailsUrl + ",文章摘要:" + summary + ""); } } /** * 處理置頂文章列表 */ private void processTopArticle(String topListDiv, String id_author) { // 從列表頁獲取列表資訊 List<String> all; all = new Html(topListDiv).xpath("//div[@id=\"article_toplist\"]/div") .all(); if (!all.isEmpty()) for (String string : all) { // 單項第一部分:article_title // 文章地址 String detailsUrl = new Html(string) .xpath("//div[@class='article_title']//span[@class='link_title']//a/@href") .toString(); // 文章id String id_blog = MyStringUtils.getLastSlantContent(detailsUrl); // 文章標頭 String title = new Html(string) .xpath("//div[@class='article_title']//span[@class='link_title']//a/text()") .toString(); // 文章型別 String type = getArticleType(string); // 單項第二部分:article_description String summary = new Html(string).xpath( "//div[@class='article_description']//text()") .toString(); // 單項第三部分:article_manage String publishDateTime = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_postdate']//text()") .toString(); // 閱讀量 String viewNums = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_view']//text()") .toString(); viewNums = MyStringUtils.getStringPureNumber(viewNums); // 評論數 String commentNums = new Html(string) .xpath("//div[@class='article_manage']//span[@class='link_comments']//text()") .toString(); commentNums = MyStringUtils.getStringPureNumber(commentNums); // 開始組織資料 System.out.println(TAG + ":,文章id:" + id_blog + ",文章標頭:" + title + ",文章型別('0':原創;'1':轉載;'2':翻譯):" + type + ",發表日期:" + publishDateTime + ",閱讀量:" + viewNums + ",評論數:" + commentNums + ",文章地址:" + detailsUrl + ",文章摘要:" + summary + ""); } } /** * 獲取文章型別 */ private String getArticleType(String string) { String type; type = new Html(string) .xpath("//div[@class='article_title']//span[@class='ico ico_type_Original']//text()") .get();// 原創型別 if (type != null) return 0 + ""; type = new Html(string) .xpath("//div[@class='article_title']//span[@class='ico ico_type_Repost']//text()") .get();// 原創型別 if (type != null) return 1 + ""; type = new Html(string) .xpath("//div[@class='article_title']//span[@class='ico ico_type_Translated']//text()") .get();// 原創型別 if (type != null) return 2 + ""; return 3 + ""; } @Override public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new CsdnBlogListSpider()) .addPipeline(null) .addUrl("http://blog.csdn.net/" + "wgyscsf" + "/" + "article/list/1").run(); } }
關鍵程式碼解釋
page.getUrl()).regex("^http://blog.csdn.net/\\w+/article/list/[0-9]*[1-9][0-9]*$").match(),每次正則表示式都是一個難點。這句話的意思是:http://blog.csdn.net/使用者id/article/list/頁碼,這個網址包含兩個可變字串:使用者id和頁碼,這個正則主要是為了匹配這個規則。如果是爬取單個使用者就不用這個麻煩。但是,後期如果我們有很多使用者id,這樣寫才能更加方便的去爬取任意使用者。page.addTargetRequests(page.getHtml().xpath("//div[@class=\"list_item_new\"]//div[@class=\"pagelist\"]").links().all())這句話是整個部落格列表爬取的核心。它負責找到個頁面下所有有效的列表連結,加入到爬蟲佇列,到爬蟲佇列,還會走上面所提到的正則進行匹配,加入到列表頁的解析,是一個迭代的過程。當然,如果想要更加嚴謹,也可以做一個正則的匹配,比如我只抓取div[@class=\"pagelist\"]下符合頁表頁規則的連結。當然,這裡是進行了分析,裡面只包含有效連結,就沒有再進行判斷。頁碼所在的div如下:<!--顯示分頁--> <div id="papelist" class="pagelist"> <span> 49條 共4頁</span> <a href="/wgyscsf/article/list/1">首頁</a> <a href="/wgyscsf/article/list/1">上一頁</a> <a href="/wgyscsf/article/list/1">1</a> <strong>2</strong> <a href="/wgyscsf/article/list/3">3</a> <a href="/wgyscsf/article/list/4">4</a> <a href="/wgyscsf/article/list/3">下一頁</a> <a href="/wgyscsf/article/list/4">尾頁</a> </div>page.getHtml().xpath("//div[@class=\"list_item_new\"]/div").all();這裡需要注意的是,需要判斷返回List的個數,進而判斷是否存在“置頂文章”。如果存在先處理“置頂文章”邏輯,再處理普通文章邏輯。經過分析可以知道子節點有3個,“置頂文章”列表div和“普通文章”列表div和分頁div。getArticleType(String string)特別注意這個方法裡面關於文章型別的處理,如何判斷是何種型別的文章,可以嘗試獲取對應文章所處的div,如果返回不為null,即說明存在,否則不存在。大致如下:String type; type = new Html(string).xpath("//div[@class='article_title']//span[@class='ico ico_type_Original']//text()").get();// 原創型別 if (type != null) return 0 + "";// 說明是原創
資料庫設計
設計原則
- 全部欄位允許為空,包括相關所屬唯一id。另外新建一個id,隨機生成UUID,作為主鍵。原因:因為爬蟲可能會出現爬不到的資料,或者“髒資料”,所以儘可能使資料庫不那麼“嚴謹”,保證程式能夠正常走下去。在表中新建一個id作為主鍵,這個可以保證在獲取相應表id失敗的情況下,仍然可以正常執行。
- 每個表的所屬id(不是新建的),比如作者id、文章id、個人id等可以標示一行資料的欄位,全部加上【索引】。原因:後期需要儲存大量使用者以及文章資料,儲存之前我們需要拿獲取到表的id去查詢資料庫中是否存在,需要有一個查詢的過程。查詢是一個遍歷的過程,加與不加【索引】對程式影響巨大。簡單測試如下(不帶索引與帶索引的查詢時間,資料量:80W):
- 儘可能加上所有直接相關的所有欄位,不管現有爬蟲技術是否能實現。並且,再加上必要的備用欄位。原因:資料表修改麻煩,儘可能後期不要修改。不能直接過去的資料,可能會在其它模組獲取,比如“部落格詳情”與“部落格列表”之間的關係。
- 不使用外來鍵,原因:同第一條。
- 主鍵不用自增的,而是採用手動生成。

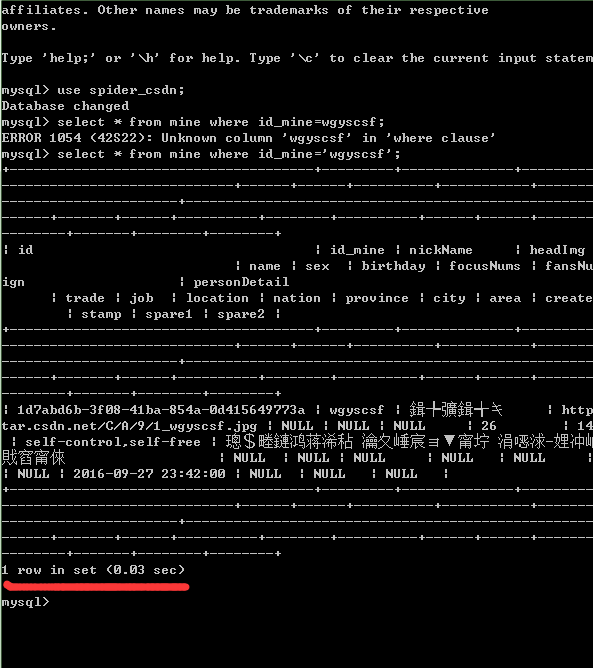
表結構

建表語句
- 在操作程式碼中附帶
操作程式碼
個人公眾號,及時更新技術文章(請移步公眾號,文章會被官方刪除)

相關推薦
CSDN爬蟲(二)——部落格列表分頁爬蟲+資料表設計
CSDN爬蟲(二)——部落格列表分頁爬蟲+資料庫設計 說明 開發環境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2 爬蟲框架:webMagic 建議:建議首先閱讀webM
Python開發簡單爬蟲(二)---爬取百度百科頁面數據
class 實例 實例代碼 編碼 mat 分享 aik logs title 一、開發爬蟲的步驟 1.確定目標抓取策略: 打開目標頁面,通過右鍵審查元素確定網頁的url格式、數據格式、和網頁編碼形式。 ①先看url的格式, F12觀察一下鏈接的形式;② 再看目標文本信息的
Python學習之路 (三)爬蟲(二)
版權 特殊 機器人 zhang col 取出 log arch robots 通用爬蟲和聚焦爬蟲 根據使用場景,網絡爬蟲可分為 通用爬蟲 和 聚焦爬蟲 兩種. 通用爬蟲 通用網絡爬蟲 是 捜索引擎抓取系統(Baidu、Google、Yahoo等)的重要組成部分。主要目
爬蟲(二):Urllib庫詳解
lib lwp ces lin 設置 內置 col http測試 url 什麽是Urllib: python內置的HTTP請求庫 urllib.request : 請求模塊 urllib.error : 異常處理模塊 urllib.parse: url解析模塊 urllib
Python爬蟲(二)網絡爬蟲的尺寸與約束
.cn 哪些 com 尺寸 網頁 inf robot robots 搜索 Infi-chu: http://www.cnblogs.com/Infi-chu/ 一、網絡爬蟲的尺寸: 1.小規模,數據量小,爬取速度不敏感,Requests庫,爬取網頁 2.中規模,數據
基於C#.NET的高端智能化網絡爬蟲(二)(攻破攜程網)
nbsp net article 智能 tail 攜程網 .net 網絡爬蟲 準備工作 轉:https://www.toutiao.com/i6304492725462893058/ https://blog.csdn.net/hjkl950217/article/det
Python從零開始寫爬蟲(二)BeautifulSoup庫使用
Beautiful Soup 是一個可以從HTML或XML檔案中提取資料的Python庫, BeautifulSoup在解析的時候是依賴於解析器的,它除了支援Python標準庫中的HTML解析器,還支援一些第三方的解析器比如lxml等。可以從其官網得到更詳細的資訊:http://beau
爬蟲(二):Lucene
搜尋引擎: * 什麼是搜尋引擎 * 搜尋引擎基本執行原理 * 原始資料庫做搜尋有什麼弊端 * 倒排索引(敲黑板) lucene lucene相關的概念 lucene和solr的關係 lucene入門程式(寫入索引的操作程式碼)
自學Python爬蟲(二)Requests庫的使用
前言 Urllib和requests庫都是python3中傳送請求的庫,但是比較而言,Requests庫更加強大和易用,所以學習python3就不要學習urllib了,2020年python2的庫就不再更新,所以我們學習python3更有意義! 例項引入 import requ
爬蟲(二)
scrapy 一.什麼是Scrapy? Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,非常出名,非常強悍。所謂的框架就是一個已經被集成了各種功能(高效能非同步下載,佇列,分散式,解析,持久化等)的具有很強通用性的專案模板。對於框架的學習,重點是要學習其
Python爬蟲(二):爬蟲獲取資料儲存到檔案
接上一篇文章:Python爬蟲(一):編寫簡單爬蟲之新手入門 前言: 上一篇文章,我爬取到了豆瓣官網的頁面程式碼,我在想怎樣讓爬取到的頁面顯示出來呀,爬到的資料是html頁面程式碼,不如將爬取到的程式碼儲存到一個檔案中,檔案命名為html格式,那直接開啟這個檔案就可以在瀏覽器上看到爬取資料的
python爬蟲(二)----正則表示式
正則表示式 本部落格主要講正則表示式在爬蟲網頁解析中的作用 需要的是python的re模組 python版本:3.x (一) 正則表示式的基本知識 1 匹配字元 常見匹配模式—匹配字元 模式 描述
網路爬蟲(二)urllib包使用
隨著網路的快速發展,全球資訊網成為了大量資訊的載體,如何有效地獲取那些對我們而言有用的資訊呢?一種可行的工具就是網路爬蟲。 可以把全球資訊網想象成一張“蜘蛛網”, 我們日常訪問的京東,百度,
python爬蟲(二)
HTTP和HTTPS HTTP,全稱超文字傳送協議,是屬於計算機網路中應用層的協議,而HTTPS是HTTP加上SSL,HTTP是明文傳輸,速度快,但安全係數很低,而HTTPS比HTTP安全很多,但缺點是傳輸速度比較慢。 一.HTTP之請求 這是一個請求報文的例子: GET /review/best/ HTT
Python3使用selenium庫簡單爬蟲(二)
使用selenium爬取豆瓣圖書top250書籍資訊 1、上一篇文章Python3使用selenium庫簡單爬蟲(一)通過元素的id、name、class_name定位元素,這次使用xpath定位元素 (1)使用xpath定位元素的幾種表示方法: * 匹
[Python]網路爬蟲(二):利用urllib2通過指定的URL抓取網頁內容
版本號:Python2.7.5,Python3改動較大,各位另尋教程。 所謂網頁抓取,就是把URL地址中指定的網路資源從網路流中讀取出來,儲存到本地。 類似於使用程式模擬IE瀏覽器的功能,把URL作為HTTP請求的內容傳送到伺服器端, 然後讀取伺服器端的響應資源。 在
scrapy專利爬蟲(二)——請求相關
scrapy專利爬蟲(二)——請求相關 在這裡筆者將會介紹一些關於傳送request的相關內容。 Spider Spider預設需要填寫三個引數: name spider的獨立名稱,必須唯一 allowe
Python爬蟲(二):Scrapy框架的配置安裝
Windows安裝方式 預設支援Python2、Python3,通過pip安裝Csrapy框架: pip install Scrapy Ubuntu(9.10以上版本)安裝方式 預設支援Python2、Python3,通過pip安裝Csrapy框架: sud
WebMagic爬蟲(二)升級版
我在爬取頁面的時候發現有很多資料是js渲染進去的,通過: String htm = page.getHtml().xpath("*/html/html()").toString(); page.putField("html",htm); 就可以看到爬取下來的頁面資料,可以很清晰的看出頁面
分布式豆瓣爬蟲(二): 控制節點-數據存儲器
電影 ram 分布 修改 豆瓣 tput col spa 節點 一、實現原理 因為存儲方式相同所以數據存儲器的代碼無需修改 二、代碼如下 1 import csv 2 3 class DataOutput: 4 def __init__(self):