
一個新型的混音演算法
阿新 • • 發佈:2019-02-05
針對傳統經典的線性混音,路數多時音量變小的缺點;自創了一個新的混音演算法,解決該問題,聲音不會忽大忽小,不會溢位,而且該方法還能一定程度抑制噪聲,突出人聲,能實時計算量小,專利已經受理。
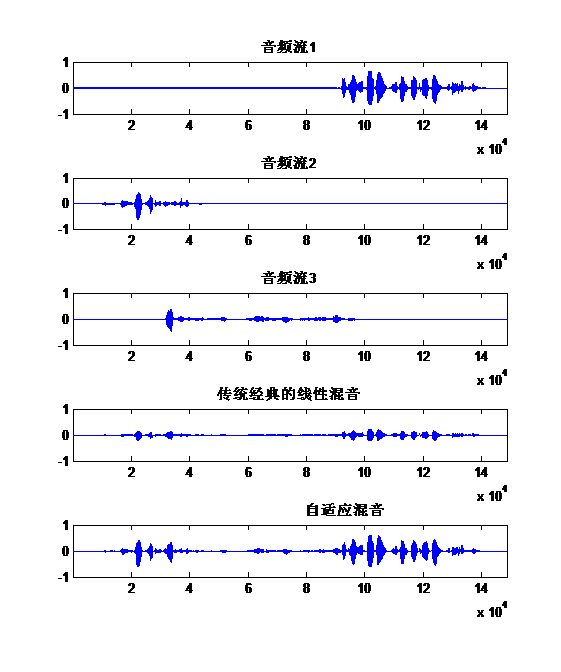
對於混音方法,網上和文獻上流傳許多方法。
1.平均權重
2.隨幅值變化的權重
3.利用衰減因子緩慢規整
4.絕對值處理
5.A+B-A*B(書寫不是很精確)
經過實驗,方法做了比較了:
方法1.唯一的缺陷就是正反時抵消的情況
方法2.計算量大,忽重忽輕
方法3.小值的時候 比 線性的 聲強要大,但是對於比較洪亮的歌曲,出現波形失真,會破音,也無法避免方法1的問題
放大4.能保證語義資訊,但是丟失了相位資訊,聲音失真。
方法5.網上流傳的經典演算法 A+B-A*B,能克服1的問題,但是聲音有些失真,其它情況,與方法1相當。
方法5的理解:
其實就是線性分量A+B與非線性分量A*B的一個疊加
(A+B)/A*B=1/A+1/B。 (-1<A<1,-1<B<1)
對於0<A<1,0<B<1時,平均算下,A與B都作0.5,A+B>4*A*B,也就是說A+B的分量遠遠大於A*B。為了進一步達到該目的,可以進一步做優化處理,目的就是使得
A和B都儘可能小,最後混音完後,再放大。
同樣的,其他情況也是如此。