
資料清洗很要命?那是因為你沒看到這份攻略!
對資料探勘和分析的人員來說,資料清洗和轉化是一項非常繁瑣和複雜的工作,佔用了很大的工作量。
目前,資料的挖掘和分析,基本都是採用pandas,numpy或者R語言,這種處理過程複雜,而且沒有一個統一的規範。本文將給大家介紹一項技術,使用FEA-spk技術,可以快速實現資料的清洗和轉化工作,而且任何人都能看懂。
FEA-spk技術,它的底層基於最流行的大資料開發框架spark,而且可以和很多流行大資料開發框架結合,比如Hadoop,hbase,mongodb等。使用FEA-spk來做互動分析,不但非常簡單易懂,而且幾乎和spark的功能一樣強大,更重要的一點,它可以實現視覺化,處理的資料規模更大,下面就實際的專案為例進行說明。
1. 要想使用FEA-spk技術,首先要建立一個spk的連線,所有的操作都是以它為上下文進行的。
在fea介面執行以下命令:
2. DataFrame的轉換
FEA-spk技術操作有2種dataframe,一種是pandas的dataframe,可以直接在fea裡面執行dump檢視。另外一種是spark的dataframe,它能夠進行各種各樣的spark運算元操作,比如group,agg等
spark dataframe需要轉換為pandas的dataframe才能執行dump命令檢視,轉換的原語如下
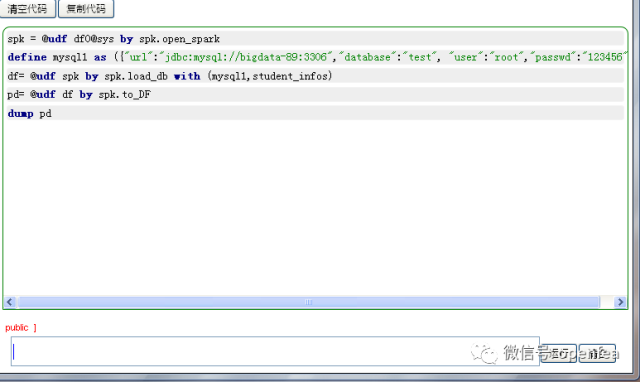
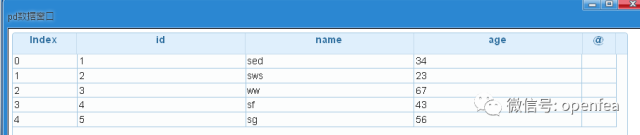
pd= @udf df by spk.to_DF #spark dataframe df轉換為pandas dataframe pd
dump pd #可以直接使用dump命令檢視
sdf= @udf spk,pd by spk.to_SDF #將pandas dataframe pd轉換為spark dataframe sdf,以便進行spark的各種操作
3. 匯入資料來源
FEA-spk技術支援各種各樣的資料來源,hive,mongodb,text,avro , json, csv , parquet,mysql,oracle, postgresql以及具有特定格式的檔案
下面舉其中幾個為例進行說明
(1) 載入csv資料來源。
csv資料來源分為2種,第一種是帶header的(即有欄位名的),另外一種是沒有header欄位名的,格式稍有區別
a.csv檔案格式如下
id,hash
1,ssss
2,333
3,5567
下面進行資料載入的命令。
原語如下
df= @udf spk by spk.load_csv with (header,/data/a.csv)
#header為具有欄位名的,/data/a.csv為hdfs上的檔案路徑,如果沒有heade欄位,原語為df= @udf spk by spk.load_csv with (/data/a.csv)

(2) 關係型資料來源的載入,比如mysql,oracle,postgresql等
首先需要定義一個json連線串,用來指定連線的地址,資料庫名,使用者名稱,密碼。
格式如下
define mysql1 as ({"url":"jdbc:mysql://bigdata-89:3306","database":"test",
"user":"root","passwd":"123456"})
在mysql的test資料庫裡面有一張student_infos表,下面進行載入
df= @udf spk by spk.load_db with (mysql1,student_infos)
#載入student_infos表

(3)hive資料來源的載入
在hive的mydb資料庫裡面有一張student表,下面來載入它
df= @udf spk by spk.load_hive with (mydb.student)
4. 對資料進行切割,提取對於日誌分析資料來說,最重要的一步就是對資料進行切割,提取,這樣才能進行下一步的分析。下面以美國宇航局肯尼迪航天中心WEB日誌為例進行說明。
資料的下載地址為
http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
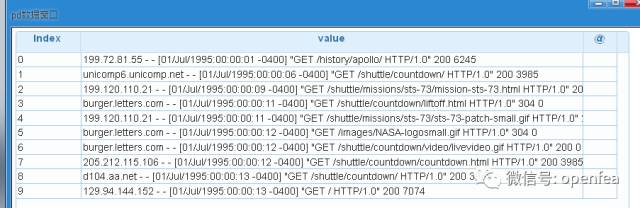
下面就到了至關重要的一步了,對資料進行正則化提取,提取出其中的主機名,時間戳,路徑,訪問狀態,返回的位元組數這5個欄位,原語命令如下
df1= @udf df by spk.reg_extract with (regexp_extract('value', r'^([^\s]+\s)', 1).alias("host"),
regexp_extract('value', r'^.*\[(\d\d/\w{3}/\d{4}:\d{2}:\d{2}:\d{2} -\d{4})]', 1).alias('timestamp'),
regexp_extract('value', r'^.*"\w+\s+([^\s]+)\s+HTTP.*"', 1).alias('path'),
regexp_extract('value', r'^.*"\s+([^\s]+)', 1).cast('integer').alias('status'),
regexp_extract('value', r'^.*\s+(\d+)$', 1).cast('integer').alias('content_size'))
#將df表的value欄位進行正則表示式提取出第一個匹配的主機名,將其重新命名為host列
將df表的value欄位進行正則表示式提取出第一個匹配的時間,將其重新命名為timestamp列
將df表的value欄位進行正則表示式提取出第一個匹配的路徑,將其重新命名為path列
將df表的value欄位進行正則表示式提取出第一個匹配的狀態碼,將它的型別轉化為int型別並將其重新命名為status列
將df表的value欄位進行正則表示式提取出第一個匹配的狀態碼,將它的型別轉化為int型別並將其重新命名為status列
將df表的value欄位進行正則表示式提取出第一個匹配的位元組數,將它的型別轉化為int型別並將其重新命名為content_size列
可以看到資料已經被切割成5列了
5. 清除無效語句
根據分析目標進行清洗得到所需要的資料,下面以fea經典的cd_esql為例進行說明
日誌的格式如下:
下面過濾掉日誌中的錯誤日誌
正常的日誌都包含有”-mylogger-”這個欄位內容,根據這個特徵過濾掉錯誤日誌。
df1= @udf df by spk.filter with (instr('value', '- mylogger -')<> 0)
# instr('value', '- mylogger -'),value欄位如果不包含- mylogger -,返回0,否則返回它所在的索引。<>表示不為0,這樣就過濾掉了錯誤日誌。


6. 分割有效欄位
經過無效語句清洗,保留有效語句,但是還是不能滿足我們基礎DF表的要求,下面進行有效欄位的分割,提取。
有效的一條語句完整結構如下:
時間(精確到毫秒)/分割符(-mylogger-)/字串(info-)/語句(事件)
2016-03-29 13:56:13,748 /- mylogger -/ INFO -/ select * from people_trail01_dest where KSSJ>=2001-02-28T01:05:24.000Z
整條語句中就是時間與事件是分析統計有用的,要從整條語句中分割出來,
原語如下所示。
df2= @udf df1 by spk.opfield with (split(value,'- mylogger - ')[0] as d1:split(value,'- mylogger - ')[1] as event)
#將df1表的value欄位按照- mylogger –分割,第一個欄位並存儲到d1列中、提取第二個欄位儲存到event列中

可以看到event列還是不能滿足要求,再進行分割
7. 提取時間,日期欄位
對上面的資料提取天數
還有很多資料清洗攻略,我們將在下一篇繼續介紹,敬請期待!
FEA-spk簡單,強大,視覺化
不懂Java,Python同樣玩轉Spark
專門為資料分析師打造!