
架構設計:系統間通訊(28)——Kafka及場景應用(中1)
在本月初的寫作計劃中,我本來只打算粗略介紹一下Kafka(同樣是因為進度原因)。但是,最近有很多朋友要求我詳細講講Kafka的設計和使用,另外兩年前我在研究Kafka準備將其應用到生產環境時,由於沒有仔細理解Kafka的設計結構所導致的問題最後也還沒有進行交代。所以我決定即使耽誤一些時間,也要將Kafka的原理和使用場景給讀者詳細討論討論。這樣,也算是對兩年來自己學習和使用Kafka的一個總結。
4、Kafka及特性
Apache Kafka最初由LinkedIn貢獻,目前它是Apache下的一個頂級開源專案。Apache Kafka設計的首要目標是解決LinkedIn網站中海量的使用者操作行為記錄、頁面瀏覽記錄
4-1、Kafka叢集安裝
4-1-1、安裝環境介紹
Apache Kafka的安裝過程非常簡單。為了節約篇幅我不準備像介紹Apache ActiveMQ那樣,專門花費筆墨來介紹它的單機(單服務節點)安裝過程和最簡單的生產者、消費者的編碼過程。而是換一種思路:
直接介紹Apache Kafka多節點叢集的安裝過程,並且在這個Apache Kafka叢集中為新的Topic劃分多個分割槽,演示Apache Kafka的訊息負載均衡原理。可能在這個過程中,我會使用一些您還不太瞭解的詞語(或者某些操作您暫時不會理解其中的原因),但是沒有關係,您只需要按照我給出的步驟一步一步的做——這些詞語和操作會在後文被逐一解釋。
首先我們列出將要安裝的Kafka叢集中需要的服務節點,以及每個服務節點在其中的作用:
| 節點位置 | 節點作用 |
|---|---|
| 192.168.61.139 | Apache Kafka Brocker 1 |
| 192.168.61.138 | Apache Kafka Brocker 2 |
| 192.168.61.140 | zookeeper server |
在這個Apache Kafka叢集安裝的演示例項中,我們準備了兩個Apache Kafka的Brocker服務節點,並且使用其中一個節點充當zookeeper的執行節點。
Apache Kafka叢集需要使用Zookeeper服務進行協調工作,所以安裝Apache Kafka前需要首先安裝和執行Zookeeper服務。由於這邊文章主要介紹的是Apache Kafka的工作原理,所以怎樣安裝和使用Zookeeper的內容就不再進行贅述了,不清楚的讀者可以參考我另一篇文章:《
4-1-2、Kafka叢集安裝過程
- 首先我們在192.168.61.140的伺服器上安裝Zookeeper以後,直接啟動zookeeper即可:
zkServer.sh start您可以直接使用wget命令,也可以通過瀏覽器(或者第三方軟體)下載:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz- 下載後,執行命令進行壓縮檔案的解壓操作:
tar -xvf ./kafka_2.10-0.8.1.1.tgz筆者習慣將可執行軟體放置在/usr目錄下,您可以按照您自己的操作習慣或者您所在團隊的規範要求放置解壓後的目錄(正式環境下不建議使用root賬號執行Kafka):
mv /root/kafka_2.10-0.8.1.1 /usr/kafka_2.10-0.8.1.1/- Apache Kafka所有的管理命令都存放在安裝路徑下的./bin目錄中。所以,如果您希望後續管理方便就可以設定一下環境變數:
export PATH=/usr/kafka_2.10-0.8.1.1/bin:$PATH
#記得在/etc/profile檔案的末尾加入相同的設定- Apache Kafka的配置檔案存放在安裝路徑下的./config目錄下。如下所示:
-rw-rw-r--. 1 root root 1202 4月 22 2014 consumer.properties
-rw-rw-r--. 1 root root 3828 4月 22 2014 log4j.properties
-rw-rw-r--. 1 root root 2217 4月 22 2014 producer.properties
-rw-rw-r--. 1 root root 5322 4月 28 23:32 server.properties
-rw-rw-r--. 1 root root 3326 4月 22 2014 test-log4j.properties
-rw-rw-r--. 1 root root 995 4月 22 2014 tools-log4j.properties
-rw-rw-r--. 1 root root 1023 4月 22 2014 zookeeper.properties如果您進行的是Apache Kafka叢集安裝,那麼您只需要關心“server.properties”這個配置檔案(其他配置檔案的作用,我們後續會討論到)。
其中目錄下有一個zookeeper.properties不建議使用。之所以有這個配置檔案,是因為Kafka中帶有一個zookeeper執行環境,如果您使用Kafka中的“zookeeper-server-start.sh”命令啟動這個自帶zookeeper環境,才會用到這個配置檔案。
- 開始編輯server.properties配置檔案。這個配置檔案中預設的配置項就有很多,但是您不必全部進行更改。下面我們列舉了更改後的配置檔案情況,其中您需要主要關心的屬性使用中文進行了說明(當然原有的註釋也會進行保留):
# The id of the broker. This must be set to a unique integer for each broker.
# 非常重要的一個屬性,在Kafka叢集中每一個brocker的id一定要不一樣,否則啟動時會報錯
broker.id=2
# The port the socket server listens on
port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
#host.name=localhost
# The number of threads handling network requests
num.network.threads=2
# The number of threads doing disk I/O
# 故名思議,就是有多少個執行緒同時進行磁碟IO操作。
# 這個值實際上並不是設定得越大效能越好。
# 在我後續的“儲存”專題會講到,如果您提供給Kafka使用的檔案系統物理層只有一個磁頭在工作
# 那麼這個值就變得沒有任何意義了
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=1048576
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=1048576
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
# A comma seperated list of directories under which to store log files
# 很多開發人員在使用Kafka時,不重視這個屬性。
# 實際上Kafka的工作效能絕大部分就取決於您提供什麼樣的檔案系統
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across the brokers.
num.partitions=2
# The number of messages to accept before forcing a flush of data to disk
# 從Page Cache中將訊息正式寫入磁碟上的閥值:以待轉儲訊息數量為依據
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
# 從Page Cache中將訊息正式寫入磁碟上的閥值:以轉儲間隔時間為依據
#log.flush.interval.ms=1000
# The minimum age of a log file to be eligible for deletion
# log訊息資訊儲存時長,預設為168個小時
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
# 預設為1GB,在此之前log檔案不會執行刪除策略
# 實際環境中,由於磁碟空間根本不是問題,並且記憶體空間足夠大。所以筆者會將這個值設定的較大,例如100GB。
#log.retention.bytes=1073741824
# The maximum size of a log segment file.
# When this size is reached a new log segment will be created.
# 預設為512MB,當達到這個大小,Kafka將為這個Partition建立一個新的分段檔案
log.segment.bytes=536870912
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
# 檔案刪除的保留策略,多久被檢查一次(單位毫秒)
# 實際生產環境中,6-12小時檢查一次就夠了
log.retention.check.interval.ms=60000
# By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# root directory for all kafka znodes.
# 到zookeeper的連線資訊,如果有多個zookeeper服務節點,則使用“,”進行分割
# 例如:127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002
zookeeper.connect=192.168.61.140:2181
# Timeout in ms for connecting to zookeeper
# zookeeper連線超時時間
zookeeper.connection.timeout.ms=1000000再次強調一下,以上配置屬性中必須按照您自己的環境更改的屬性有:“broker.id”、“log.dirs”以及“zookeeper.connect”。其中每一個Kafka服務節點的“broker.id”屬性都必須不一樣。
這樣我們就完成了其中一個Broker節點的安裝和配置。接下來您需要按照以上描述的步驟進行Kafka叢集中另一個Broker節點的安裝和配置。一定注意每一個Kafka服務節點的“broker.id”屬性都必須不一樣,在本演示例項中,我設定的broker.id分別為1和2。
接下來我們啟動Apache Kafka叢集中已經完成安裝和配置的兩個Broker節點。如果以上所有步驟您都正確完成了,那麼您將會看到類似如下的啟動日誌輸出:
#分別在兩個節點上執行這條命令,以便完成節點啟動:
kafka-server-start.sh /usr/kafka_2.10-0.8.1.1/config/server.properties
#如果啟動成功,您將看到類似如下的日誌提示:
......
[2016-04-30 02:53:17,787] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2016-04-30 02:53:17,799] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
......- 啟動成功後,我們可以在某一個Kafka Broker 節點上執行以下命令來建立一個topic。為了後續進行講解,我們建立的topic有4個分割槽和兩個複製因子:
kafka-topics.sh --create --zookeeper 192.168.61.139:2181 --replication-factor 2 --partitions 4 --topic my_topic24-1-3、Kafka中的常用命令
在安裝Kafka叢集的時候,我們使用到了Kafka提供的指令碼命令進行叢集啟動、topic建立等相關操作。實際上Kafka提供了相當豐富的指令碼命令,以便於開發者進行叢集管理、叢集狀態監控、消費者/生產者測試等工作,這裡為大家列舉一些常用的命令:
4-1-3-1 叢集啟動:
kafka-server-start.sh config/server.properties這個命令帶有一個引數——指定啟動服務所需要的配置檔案。預設的配置檔案上文已經提到過,存在於Kafka安裝路徑的./config資料夾下,檔名為server.properties。
4-1-3-2 建立Topic:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test帶有 –create引數的kafka-topics命令指令碼用於在Kafka叢集上建立一個新的topic。後續的四個引數為:
zookeeper 該引數用來指定Kafka叢集所使用的zookeeper的地址,這是因為當topic被建立時,zookeeper下的/config/topics目錄中會記錄新的topic的配置資訊。
replication-factor 複製因子數量。副本是Kafka V0.8.X版本中加入的保證訊息可靠性的功能,複製因為是指某一條訊息進行復制的副本數量,該功能以叢集中Broker服務節點的數量為單位。也就是說當Broker服務節點的數量為X時,複製因子的數量最多為X。否則在執行topic建立時會報告類似如下的錯誤:
Error while executing topic command replication factor: 3 larger than available brokers: 2Kafka的複製過程將在本文的後續章節進行介紹。當然,這個引數可以不進行設定,如果不進行設定該引數的預設值則為1。
partitions 分割槽數量(預設分割槽為1)。一個topic可以有若干分割槽,這些分割槽分佈在Kafka叢集的一個或者多個Broker上。後文我們將討論到,partition分割槽是Kafka叢集實現訊息負載均衡功能的重要基礎,且topic中partition分割槽一旦建立就不允許進行動態更改。所以一旦您準備在正式生產環境建立topic,就一定要慎重考慮它的分割槽數量。
topic 新建立的topic的名稱。該引數在建立topic時指定,且在Kafka叢集中topic的名稱必須是唯一的。
4-1-3-3 以生產者身份登入測試
kafka-console-producer.sh --broker-list localhost:9093 --topic test
# 或者
kafka-console-producer.sh --producer.config client-ssl.properties使用命令指令碼(而不是Kafka提供的各種語言的API),模擬一個訊息生產者登入叢集,主要是為了測試指定的topic的工作情況是否正常。可以有兩種方式作為訊息生產者登入Kafka叢集:
第一種方式指定broker-list引數和topic引數,broker-list攜帶需要連線的一個或者多個broker服務節點;topic為指定的該訊息生產者所使用的topic的名稱。
第二種方式是指定producer生產者配置檔案和客戶端ssl加密資訊配置檔案(後一個檔案也可不進行指定,如果您沒有在Kafka叢集中配置ssl加密規則的話)。預設的producer生產者配置檔案存放在kafka安裝路徑的./config目錄下,檔名為producer.properties。
4-1-3-4 以消費者身份登入測試
kafka-console-consumer.sh --zookeeper localhost:2181 --topic test同樣您可以使用命令指令碼的方式,以訊息消費者的身份登入Kafka叢集,目的相同:為了測試Kafka叢集下您建立的topic是否能夠正常工作。該命令有兩個引數:
zookeeper 指定的Kafka叢集所使用的zookeeper地址,如果有多個zookeeper節點就是用“,”進行分割。該引數必須進行指定。
topic 該引數用於指定使用的topic名稱資訊。如果您的topic在kafka叢集下工作正常的話,那麼在成功使用消費者身份登入後,就可以收到topic中有生產者傳送的訊息資訊了。
4-1-3-5 檢視Topic狀態
kafka-topics.sh --describe --zookeeper 192.168.61.139:2181 --topic my_topic2以上命令可以用來查詢指定的topic(my_topic2)的關鍵屬性,包括topic的名稱、分割槽情況、每個分期的主控節點、複製因子、複製序列已經賦值序列的同步狀態等資訊。命令可能的結果如下所示:
Topic:my_topic2 PartitionCount:4 ReplicationFactor:2 Configs:
Topic: my_topic2 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: my_topic2 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: my_topic2 Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: my_topic2 Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2請注意這個查詢命令,因為這個查詢命令所反映的結果透露出了Apache Kafka V0.8.X版本的主要設計原理,我們本節下半部分的內容將從這裡展開。
4-2、Kafka原理:設計結構
一個完整的Apache Kafka解決方案的組成包括四個要素:Producer(訊息生產者)、Server Broker(服務代理器)、Zookeeper(協調者)、Consumer(訊息消費者)。 Apache Kafka在設計之初就被認為是叢集化工作的,所以要說清楚Apache Kafa的設計結構除了要講述每一個Kafka Broker是如何工作的以外,還要講述清楚整個Apache Kafka叢集是如何工作的。
4-2-1、Kafka Broker工作結構
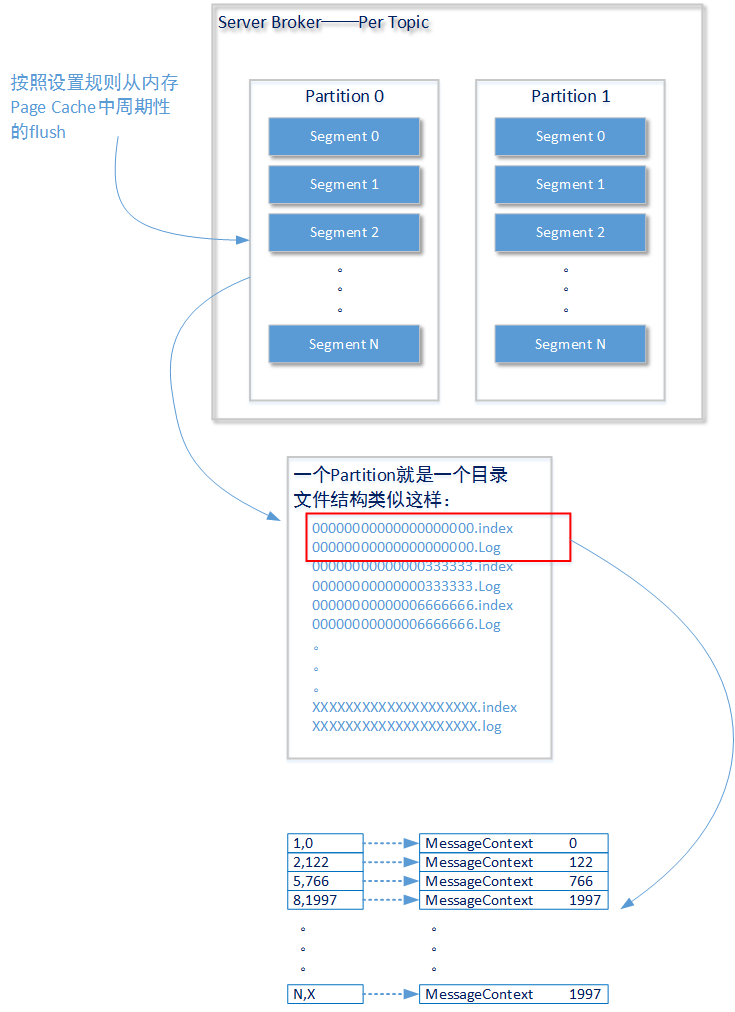
在Apache Kafka的Server Broker設計中,一個獨立進行訊息獲取、訊息記錄和訊息分送操作的佇列稱之為Topic(和ActiveMQ中Queue或者Topic的概念同屬一個級別)。以下我們討論的內容都是針對一個Topic而言,後續內容就不再進行說明了。
- 上圖描述了一個獨立的Topic構造結構:Apache Kafka將Topic拆分成多個分割槽(Partition),這些分割槽(Partition)可能存在於同一個Broker上也可能存在於不同的Broker上。如果您觀察Kafka的檔案儲存結構就會發現Kafka會為Topic中每一個分割槽建立一個獨立的檔案加,類似如下所示(以下的Topic——my_topic2一共建立了4個分割槽):
[[email protected] my_topic2-0]# ls
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-0
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-1
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-2
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-3由Producer傳送的訊息會被分配到各個分割槽(Partition)中進行儲存,至於它們是按照什麼樣的規則被分配的在後文會進行講述。一條訊息記錄只會被分配到一個分割槽進行儲存,並且這些訊息以分割槽為單位保持順序排列。這些分割槽是Apache Kafka效能的第一種保證方式:單位數量相同的訊息將分發到存在於多個Broker服務節點上的多個Partition中,並利用每個Broker服務節點的計算資源進行獨立處理。
每一個分割槽都中會有一個或者多個段(segment)結構。如上圖所示,一個段(segment)結構包含兩種型別的檔案:.index字尾的索引檔案和.log字尾的資料檔案。前一個index檔案記錄了訊息在整個topic中的序號以及訊息在log檔案中的偏移位置(offset),通過這兩個資訊,Kafka可以在後一個log檔案中找到這條訊息的真實內容。
我們在之前的文章中已經介紹過(在我後續的專題中還會繼續討論這個問題),在磁碟上進行的檔案操作只有採用順序讀和順序寫才能做到高效的磁碟I/O效能。這是Kafka保證效能的又一種方式——對索引index檔案始終保證順序讀寫:當在磁碟上記錄一條訊息時,始終在檔案的末尾進行操作;當在磁碟上讀取一條訊息時,通過index順序查詢到訊息的offset位置,再進行訊息讀取。後一種訊息讀取操作下,如果index檔案過大,Kafka的磁碟操作就會耗費掉相當的時間。所以Kafak需要對index檔案和log檔案進行分段。
實際上Kafka之所以“快”,並不只是因為它的I/O操作是順序讀寫和多個分割槽的概念;畢竟類似於AcitveMQ也有多節點叢集的概念,並且後者通過使用LevelDB或者KahaDB這樣的儲存方案也可以實現磁碟的順序I/O操作。要知道如果訊息消費者真正需要到磁碟上尋找資料了,那麼整個Kafka叢集的效能也不會好到哪兒去:目前SATA3串列埠通訊的理論速度也只有6Gpbs,使用SATA3串列埠通訊的固態硬碟,真實的順序讀取最快速度也不過550M/S。
Kafka對Linux作業系統下Page Cache技術的應用,才是其高效能的最大保證。檔案內容的組織結構只是其保證訊息可靠性的一種方式,真實的業務環境下Kafka一般不需要在磁碟上為消費者尋找訊息記錄(只要您的記憶體空間夠大)。關於Linux作業系統下的Page Cache技術又是另外一個技術話題,我會在隨後推出的“儲存”專題中為各位讀者進行詳細介紹(LevelDB也應用到了Linux Page Cache技術)。
4-2-2、Kafka Cluster結構
說清楚了單個Kafka Broker結構,我們再來看看整個Kafka叢集是怎樣工作的。以下檢視描述了某個Topic下的一條訊息是如何在Kafka 叢集結構中流動的(實線有向箭頭):
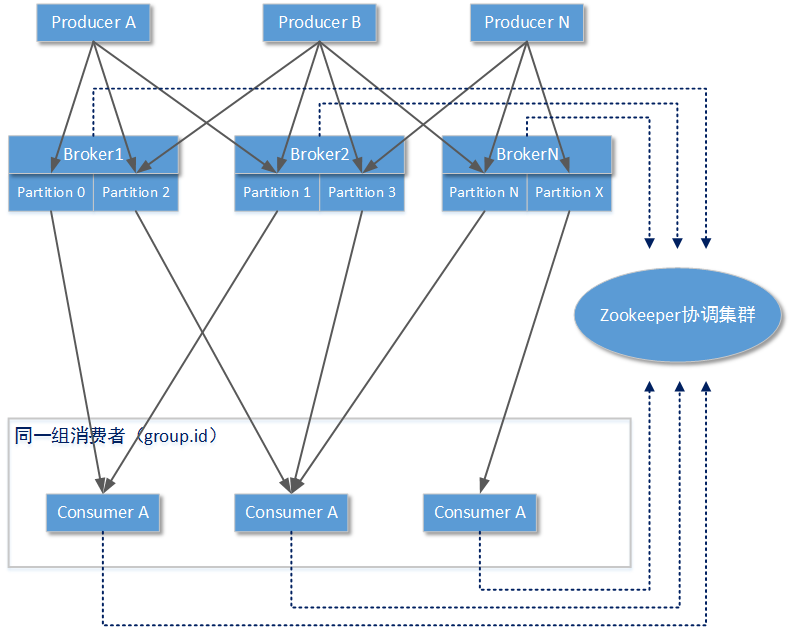
整個Kafka叢集中,可以有多個訊息生產者。這些訊息生產者可能在同一個物理節點上,也可能在不同的物理節點。它們都必須知道哪些Kafka Broker List是將要傳送的目標:訊息生產者會決定傳送的訊息將會送入Topic的哪一個分割槽(Partition)。
消費者都是按照“組”的單位進行訊息隔離:在同一個Topic下,Apache Kafka會為不同的消費者組建立獨立的index索引定位。也就是說當訊息生產者傳送一條訊息後,同一個Topic下不同組的消費者都會收到這條資訊。
同一組下的訊息消費者可以消費Topic下一個分割槽或者多個分割槽中的訊息,但是一個分割槽中的訊息只能被同一組下的某一個訊息消費者所處理。也就是說,如果某個Topic下只有一個分割槽,就不能實現訊息的負載均衡。另外Topic下的分割槽數量也只能是固定的,不可以在使用Topic時動態改變,這些分割槽在Topic被建立時使用命令列指定或者參考Broker Server中配置的預設值。
由於存在以上的操作規則,所以Kafka叢集中Consumer(消費者)需要和Kafka叢集中的Server Broker進行協調工作:這個協調工作者交給了Zookeeper叢集。zookeeper叢集需要記錄/協調的工作包括:當前整個Kafka叢集中有哪些Broker節點以及每一個節點處於什麼狀態(活動/離線/狀態)、當前叢集中所有已建立的Topic以及分割槽情況、當前叢集中所有活動的消費者組/消費者、每一個消費者組針對每個topic的索引位置等。
當一個消費者上線,並且在消費訊息之前。首先會通過zookeeper協調叢集獲取當前消費組中其他消費者的連線狀態,並得到當前Topic下可用於消費的分割槽和該消費者組中其他消費者的對應關係。如果當前消費者發現Topic下所有的分割槽都已經有一一對應的消費者了,就將自己置於掛起狀態(和broker、zookeeper的連線還是會建立,但是不會到分割槽Pull訊息),以便在其他消費者失效後進行接替。
如果當前消費者連線時,發現整個Kafka叢集中存在一個消費者(記為消費者A)關聯Topic下多個分割槽的情況,且消費者A處於繁忙無法處理這些分割槽下新的訊息(即消費者A的上一批Pull的訊息還沒有處理完成)。這時新的消費者將接替原消費者A所關聯的一個(或者多個)分割槽,並且一直保持和這個分割槽的關聯。
由於Kafka叢集中只保證同一個分割槽(Partition)下訊息佇列中訊息的順序。所以當一個或者多個消費者分別Pull一個Topic下的多個訊息分割槽時,您在消費者端觀察的現象可能就是訊息順序是混亂的。這裡我們一直在說消費者端的Pull行為,是指的Topic下分割槽中的訊息並不是由Broker主動推送到(Push)到消費者端,而是由消費者端主動拉取(Pull)。
===========================
(接下文)
相關推薦
架構設計:系統間通訊(28)——Kafka及場景應用(中1)
在本月初的寫作計劃中,我本來只打算粗略介紹一下Kafka(同樣是因為進度原因)。但是,最近有很多朋友要求我詳細講講Kafka的設計和使用,另外兩年前我在研究Kafka準備將其應用到生產環境時,由於沒有仔細理解Kafka的設計結構所導致的問題最後也還沒有進行交
架構設計:系統間通訊(36)——Apache Camel快速入門(上)
架構設計:系統間通訊(36)——Apache Camel快速入門(上) :http://blog.csdn.net/yinwenjie(未經允許嚴禁用於商業用途!) https://blog.csdn.net/yinwenjie/article/details/51692340 1、本專題主
架構設計:系統間通訊(34)——被神化的ESB(上)
1、概述 從本篇文章開始,我們將花一到兩篇的篇幅介紹ESB(企業服務匯流排)技術的基本概念,為讀者們理清多個和ESB技術有關名詞。我們還將在其中為讀者闡述什麼情況下應該使用ESB技術。接下來,為了加深讀者對ESB技術的直觀理解,我們將利用Apache Came
架構設計:系統間通訊(16)——服務治理與Dubbo 中篇(預熱)
1、前序 上篇文章中(《架構設計:系統間通訊(15)——服務治理與Dubbo 上篇》),我們以示例的方式講解了阿里DUBBO服務治理框架基本使用。從這節開始我們將對DUBBO的主要模組的設計原理進行講解,從而幫助讀者理解DUBBO是如何工作的。(由於這個章節的內容比較多,包括了知識準備、DUBBO框架概述
架構設計:系統間通訊(6)——IO通訊模型和Netty 上篇
1、Netty介紹 在Netty官網上,對於Netty的介紹是: Netty is a NIO client server framework which enables quick and easy development of network ap
架構設計:系統間通訊(23)——提高ActiveMQ工作效能(中)
6、ActiveMQ處理規則和優化 在ActiveMQ單個服務節點的優化中,除了對ActiveMQ單個服務節點的網路IO模型進行優化外,生產者傳送訊息的策略和消費者處理訊息的策略也關乎整個訊息佇列系統是否能夠高效工作。請看下圖所示的訊息生產者和訊息消費
架構設計:系統間通訊(15)——服務治理與Dubbo 上篇
1、上篇中“自定義服務治理框架”的問題 在之前的文章中(《架構設計:系統間通訊(13)——RPC例項Apache Thrift 下篇(1)》、《架構設計:系統間通訊(14)——RPC例項Apache Thrift 下篇(2)》),我們基於服務治理的基本原理,自
架構設計:系統間通訊(21)——ActiveMQ的安裝與使用
1、前言 之前我們通過兩篇文章(架構設計:系統間通訊(19)——MQ:訊息協議(上)、架構設計:系統間通訊(20)——MQ:訊息協議(下))從理論層面上為大家介紹了訊息協議的基本定義,並花了較大篇幅向讀者介紹了三種典型的訊息協議:XMPP協議、Stomp協議和
架構設計:系統間通訊(10)——RPC的基本概念
1、概述 經過了詳細的資訊格式、網路IO模型的講解,並且通過JAVA RMI的講解進行了預熱。從這篇文章開始我們將進入這個系列博文的另一個重點知識體系的講解:RPC。在後續的幾篇文章中,我們首先講解RPC的基本概念,一個具體的RPC實現會有哪些基本要素構成,然
架構設計:系統間通訊(40)——自己動手設計ESB(1)
1、概述 在我開始構思這幾篇關於“自己動手設計ESB中介軟體”的文章時,曾有好幾次動過放棄的念頭。原因倒不是因為對冗長的文章產生了惰性,而是ESB中所涉及到的技術知識和需要突破的設計難點實在是比較多,再冗長的幾篇博文甚至無法對它們全部進行概述,另外如果在思路上
架構設計:系統間通訊(39)——Apache Camel快速入門(下2)
4-2-1、LifecycleStrategy LifecycleStrategy介面按照字面的理解是一個關於Camel中元素生命週期的規則管理器,但實際上LifecycleStrategy介面的定義更確切的應該被描述成一個監聽器: 當Camel
架構設計:系統間通訊(24)——提高ActiveMQ工作效能(下)
7、ActiveMQ的持久訊息儲存方案 前文已經講過,當ActiveMQ接收到PERSISTENT Message訊息後就需要藉助持久化方案來完成PERSISTENT Message的儲存。這個介質可以是磁碟檔案系統、可以是ActiveMQ的內建資料庫
架構設計:系統間通訊(37)——Apache Camel快速入門(中)
(補上文:Endpoint重要的漏講內容) 3-1-2、特殊的Endpoint Direct Endpoint Direct用於在兩個編排好的路由間實現Exchange訊息的連線,上一個路由中由最後一個元素處理完的Exchange物件,將被髮送至由D
架構設計:系統間通訊(26)——ActiveMQ叢集方案(下)
3、ActiveMQ熱備方案 ActiveMQ熱備方案,主要保證ActiveMQ的高可用性。這種方案並不像上節中我們主要討論的ActiveMQ高效能方案那樣,同時有多個節點都處於工作狀態,也就是說這種方案並不提高ActiveMQ叢集的效能;而是從叢集中的多
架構設計:系統間通訊(38)——Apache Camel快速入門(下1)
3-5-2-3迴圈動態路由 Dynamic Router 動態迴圈路由的特點是開發人員可以通過條件表示式等方式,動態決定下一個路由位置。在下一路由位置處理完成後Exchange將被重新返回到路由判斷點,並由動態迴圈路由再次做出新路徑的判斷。如此迴圈執行
架構設計:系統間通訊(2)——概述從“聊天”開始下篇
【轉】https://blog.csdn.net/yinwenjie/article/details/48344989 4-3、NIO通訊框架 目前流行的NIO框架非常的多。在論壇上、網際網路上大家討論和使用最多的有以下幾種: 原生JAVA NIO框架:
架構設計:系統間通訊——ActiveMQ叢集方案(上)
1、綜述 通過之前的文章,我們討論了ActiveMQ的基本使用,包括單個ActiveMQ服務節點的效能特徵,關鍵調整引數;我們還介紹了單個ActiveMQ節點上三種不同的持久化儲存方案,並討論了這三種不同的持久化儲存方案的配置和效能特點。但是這還遠遠不夠,因為在生產環境
架構設計:系統間通訊——MQ:訊息協議
1、概述從本文開始,我們介紹另一型別的系統間通訊及輸:MQ訊息佇列。首先我們將討論幾種常用訊息佇列協議的基本原理和工作方式,包括MQTT、XMPP、Stomp、AMQP、OpenWire等。然後在這個基礎上介紹兩款MQ產品:ActiveMQ和RabbitMQ,它們是現在業務系
架構設計:系統存儲(28)——分布式文件系統Ceph(掛載)
all 兩個文件 原因 之前 來看 大數據 details 失敗 variable (接上文《架構設計:系統存儲(27)——分布式文件系統Ceph(安裝)》) 3. 連接到Ceph系統 3-1. 連接客戶端 完畢Ceph文件系統的創建過程後。就
架構設計:系統儲存(18)——Redis叢集方案:高效能
1、概述 通過上一篇文章(《架構設計:系統儲存(17)——Redis叢集方案:高可用》)的內容,Redis主從複製的基本功能和進行Redis高可用叢集監控的Sentinel基本功能基本呈現給了讀者。雖然本人並不清楚上一篇根據筆者實際工作經驗所撰寫的文章有什麼重