
Unity3d開發跳一跳AI(ML-agents)全紀錄
本文首發於“洪流學堂”微信公眾號。
洪流學堂,讓你快人幾步!
跳一跳介紹
最近微信上非常火的一個小遊戲,相信大家都已經玩過了。
玩法
- 小人跳躍的距離和你按壓螢幕的時長有關,按螢幕時間越長,跳的越遠
- 跳到盒子上可以加分,沒跳到盒子上游戲結束
- 連續跳到盒子中心可以成倍加分
開發歷程
閱讀此文章需要有一定的Unity3d基礎和unity-ml-agents基礎。
文中有任何紕漏歡迎指正。
用Unity開發跳一跳
先參照微信原版用Unity3d開發了簡版的跳一跳。
PPO中一些名詞解釋
Experience
每一次states,action及輸出稱為一次experience
episode_length
指的是每一次遊戲一個agent直到done所用的步數
batch size
進行gradient descent的一個batch
buffer size
先收集buffer size個數據,然後再計算進行gradient descent
Number of Epochs
會對buffer size的資料處理幾遍,比如為2,就會把這些資料處理2遍
Time Horizon
被加入experience的條件是agent done或者收集到time horizon個的資料量才加入,為了蒐集到更全的可能性,避免過擬合
模型迭代
迭代1
一開始模型建立很困惑,官方的demo裡並沒有這種給一個輸入以後,需要一段時間等結果才出來進行下一步的例子。
如果使用2個按鍵分別表示按下和擡起的事件,並且訓練出按鍵之間的聯絡,訓練起來會很慢而且有可能無法擬合。
一開始嘗試用Player型別的brain,結果發現無法實現,只能用兩個鍵的方式。然後使用Heuristic來直接模擬按鍵的時長,即action只有一個值,一個連續型的float,代表按空格的時長。
這樣的話只能去掉小人的縮放和臺子的縮放效果。(後注:現在想來其實是有一個對應關係的,可以直接通過引數設定出來,但是沒有過渡的動畫。)
這個模型用5個值作為state,分別是小人位置座標的x,小人位置座標的z,下一個盒子位置的x,下一個盒子位置的z,下一個盒子的localScale的x(x和z相同)
在最開始的時候一直在考慮如果小人在空中的時候,action還一直輸入,可能會在神經網路中建立出來奇怪的聯絡。所以本次迭代在小人在空中的時候如果給了大於0的action的時候給一個懲罰,reward -= 1**(這種想法其實是錯誤的)**
開始訓練…
迭代1-1
經過2個小時的訓練發現效果很不好
禁止輸入應該是一個規則,而不應該懲罰玩家,即使玩家輸入遊戲也不應該有反饋,所以去掉了小人在空中時候的懲罰。
另外用Academy中的Frame to Skip引數,設為30,來減少無用的輸入。
開始訓練…
迭代1-2
遊戲出現了卡死的情況,遊戲中的判定有BUG,導致可以一直接收action並且沒有獲得reward。
修復BUG…開始訓練…
迭代1-3
訓練效果一直不好,又重新將unity-ml-agents裡面的文件都看了一遍,特別參照best practice將引數重新調整了一遍開始訓練。
訓練了一個晚上,大概8個小時,效果依然不好…
迭代2
本來想著這麼簡單的模型,訓練出來一定的成果再用curriculum的方式重新訓練對比以下,看來只能直接上Curriculum看看效果了…
定義瞭如下的Curriculum檔案
{
"measure" : "reward",
"thresholds" : [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"max_distance" : [1.1,1.1,1.1,1.1,1.5,1.5,1.5,1.5,2,2,2,2,3,3,3,3],
"min_scale" : [1,1,0.5,0.5,1,1,0.5,0.5,1,1,0.5,0.5,1,1,0.5,0.5],
"random_direction":[0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1]
}
}這裡需要注意的是,thresholds的值要比下面parameters裡面的值少一個,因為最後一個lesson是會一直訓練下去的,沒有threshold
迭代2-1
忽然遊戲崩了,發現log是場景裡collider太多了
這次訓練的效果還不錯,但是遊戲裡還是有bug,導致box生成太多了
將box的生成方式改為物件池的方式,效能能優化不少,也應該不會有剛才的bug了
迭代2-2
嗯,這麼訓練確實不錯,tensorboard裡的cumulative_reward一直在增長,但是訓練了一段時間以後想到一個可能存在的問題,由於第一個max_distance是1.1,和最小distance是一樣的,也就是說下一個盒子總是距離現在的盒子1.1米,可能會有過擬合的問題,而且threshold貌似有點太大了,一直沒有切換到下一個lesson
於是趕緊停掉訓練,將第一個max_distance改成了1.2重新訓練
迭代2-3
發現了不會切換lesson的問題,趕緊去查,在issues裡面發現了答案,只有global_done為true時才會切換,需要將academy設為done或者設定一個max steps
這次將每次game over的時候academy設定為done
後來發現這樣其實是有點問題的,write_summary之後cumulative_reward會清空,如果剛好這之後的cumulative_reward波動出來大的值,那麼就會跳過lesson,這樣隨機性很大。怪不得官方的demo用的是max step 50000
迭代2-4
經過30小時的訓練,第一版終於訓練出來了,但是結果很不理想
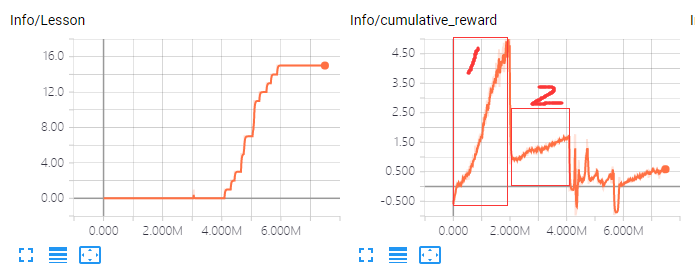
如圖:
1. 第一個過程就是開始設定max_distance是1.1的時候,增長的很快
2. 修改為1.2之後,又訓練了一段時間,發現不會切換lesson,然後改了bug
3. 後面lesson切換的很快
4. 最後訓練了很久,但是cumulative_reward也沒到1
於是開始反思模型上的問題,要簡化模型,優化Curriculum。
迭代3
將state重新定義為2個,一個是小人與下一個盒子之間的距離,一個是下一個盒子的size
Curriculum也重新定義為:
{
"measure" : "reward",
"thresholds" : [5,5,5,5,5,5,5,5,5,5,5,5,5,5,5],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"max_distance" : [1.2,1.2,1.2,1.2,1.5,1.5,1.5,1.5,2,2,2,2,3,3,3,3],
"min_scale" : [1,0.9,0.7,0.5,1,0.9,0.7,0.5,1,0.9,0.7,0.5,1,0.9,0.7,0.5],
"random_direction":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
}
}由於現在state中是小人與下一個盒子之間的距離,而生成與跳躍方向又是遊戲系統定的,所以random direction就沒有什麼用了。
而且問了能加快訓練速度,重構了遊戲和場景,使得可以有很多遊戲instance可以一起訓練,去掉random direction可以避免遊戲之間發生衝突

迭代3-1
出現了兩次Info/cumulative_reward突然劇烈下降並且再也回不去的情況,雖然這兩次發生的時候都進行了別的工程webgl的編譯,但是應該還是引數的問題
1. 懷疑是layer為1的鍋,雖然模型很簡單,因為並不是線性關係那麼簡單,所以把layer加為2重新訓練
1. 看來不是layer為1的鍋。懷疑原地跳的話-0.1的懲罰有點太大了,改為-0.01重新訓練試一下
1. 再次訓練還是出現了劇烈下降,這次直接刪掉原地跳的懲罰,再試驗看看是什麼問題
1. 還是會出現劇烈下降,試著尋找問題的原因
1. 修改了以下內容:
- 去掉normalization,改為手動normalization
- academy max steps改為1000
還是不行!!!!!!!!!!!!!!!
開始懷疑是多個instance同時執行出現的問題,但是沒找到多個instance同時執行的邏輯問題
經過反覆思考,得到是遊戲機制問題。小人跳躍時不應該接收輸入,否則的話前一個step的輸入得到的reward值會是0,無法對應起來。之前設定的skipfram30確實有問題,無法將states,action和reward對應起來
2018年1月27日23點19分
但是經過debug發現,有超過200幀還無法接收下次輸入的情況,高達5000幀,這樣就沒法用skip frame這個值了,訓練速度會太慢太慢,懷疑程式有bug,除錯中。。。
發現高達5000幀時,有player掉到地面以下的情況,可能是物理穿透,,加上一個y位置的判斷,如果y的值小於1,那麼表示小人穿透了地面gameover,並且將ground的box厚度改大
而且發現frame skip 有bug,還是我沒理解對,竟然每幀都會執行step
Edit:
I find in Academy.cs line:345 that following code is not surrounded by if (skippingFrames == false).
Am I misunderstanding something?
AcademyStep();
foreach (Brain brain in brains)
{
brain.Step();
}在github上發了個issuse,尋求建議
重新除錯測試,用程式碼的方式檢測skipframe的最佳值,設為了200
是否跳到盒子上端的檢測方式改為法線檢測
並且將上述的程式碼加到了if判斷裡面
迭代3-2
2018年1月28日
今天早上起來發現模型還是不行,而且遊戲裡還有bug
14點29分
在github上發了個issuse,作者給了個建議,可以使用unsubscribe和resubscribe的方式來讓小人在空中的時候不接受action
但是測試後發現不行,因為動態unsubscribe和resubscribe的話,agents數量是動態變化的,python端上次輸入和這次輸出的資訊,可能長度不相等
輸入的時候可能有10個小人的資訊,但是輸出的時候只有8個或20個
修復了遊戲裡的bug:跳到了下一個盒子側面,又和當前的盒子發生了碰撞,會造成邏輯問題
最終解決方案還是得用frame skip,這次遊戲執行穩定了,通過統計找到一個最佳值是137,而且小人每一步都不會超過137幀。將場景中game instance的數量設定為100個,layer 1,hidden units 32
開始訓練
發現一個報錯,game instance數量太多,導致socket buffer超出的問題,復現了幾次,出現問題時收到的buffer長度都是1460或者1460的倍數。然後意識到這是由於socket的包分包所致
路由器有一個MTU( 最大傳輸單元),一般是1500位元組,除去IP頭部20位元組,留給TCP的就只有MTU-20位元組。所以一般TCP的MSS為MTU-20=1460位元組。
還是會出現劇烈下降的問題,應該是learning rate的問題,learning rate太大了,降低learning rate到1e-4
終於訓練成功了,但是跳到中心的機率不高,感覺需要修改reward,給跳到中心加分多一些 試試中心+1,臺子上+0.1試試
迭代3-3
2018年1月29日13點21分
終於訓練出比較成功的模型了,當前設定了小人最多跳100步,所以cumulative_reward最好也就是100
Step: 349000. Mean Reward: 88.70098911968347. Std of Reward: 10.67634076995865.
Saved Model
Step: 350000. Mean Reward: 89.22838773491591. Std of Reward: 9.210647049058082.
Saved Model
Step: 351000. Mean Reward: 89.44072978303747. Std of Reward: 12.138629221972357.
Saved Model其實所有東西都搞對以後訓練的速度還是挺快的,大概到200K步的時候Mean Reward就能到70了
後記
搞完以後嘗試修復socket分包的問題,修復完建立PR的時候發現:
development-0.3的分支中已經修復這個問題
哈哈,白費功夫了~不過對python的socket通訊以及粘包有了更深的瞭解
總結
這個遊戲也算是開創了一個mg-agents的遊戲型別:需要等待一些時間才能得到reward的情況。
雖然最終是用skip frame解決的,但是中間做了很多的探索,也發現了ml-agents的一些侷限。
貢獻:在GitHub上提了一個pull request(解決了env含有子目錄時export_graph的bug)和2個issue(一個是尋求這種型別遊戲的建議——作者回復會跟進這種型別遊戲的支援;一個是unity端解析socket buffer的json失敗的問題,自己修復了這個問題,不過development-0.3的分支中已經修復這個問題)。
自己在Unity3d的一些細節開發,增強學習、ml-agents的使用和理解上也有不小的進步。
共同交流,共勉~

交流群:492325637
關注“洪流學堂”微信公眾號,讓你快人幾步

