
【神經網路與深度學習】【計算機視覺】Fast R-CNN
阿新 • • 發佈:2019-02-06
先回歸一下: R-CNN ,SPP-net
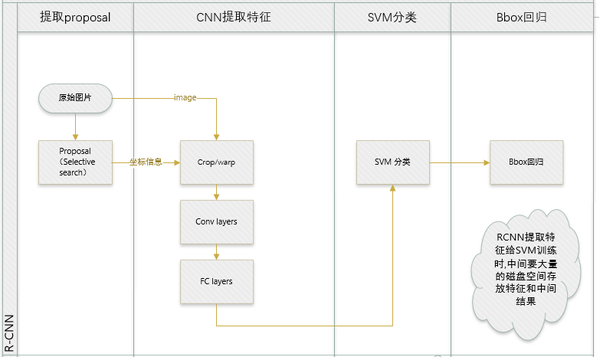
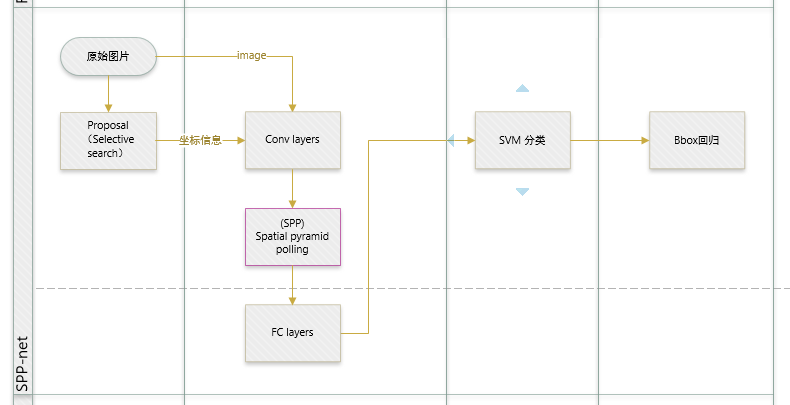
R-CNN和SPP-net在訓練時pipeline是隔離的:提取proposal,CNN提取特徵,SVM分類,bbox regression。
Fast R-CNN 兩大主要貢獻點 :
-
1 實現大部分end-to-end訓練(提proposal階段除外): 所有的特徵都暫存在視訊記憶體中,就不需要額外的磁碟空。
- joint training (SVM分類,bbox迴歸 聯合起來在CNN階段訓練)把最後一層的Softmax換成兩個,一個是對區域的分類Softmax(包括背景),另一個是對bounding box的微調。這個網路有兩個輸入,一個是整張圖片,另一個是候選proposals演算法產生的可能proposals的座標。(對於SVM和Softmax,論文在SVM和Softmax的對比實驗中說明,SVM的優勢並不明顯,故直接用Softmax將整個網路整合訓練更好。對於聯合訓練: 同時利用了分類的監督資訊和迴歸的監督資訊,使得網路訓練的更加魯棒,效果更好。這兩種資訊是可以有效聯合的。)
-
2 提出了一個RoI層,算是SPP的變種,SPP是pooling成多個固定尺度,RoI只pooling到單個固定的尺度 (論文通過實驗得到的結論是多尺度學習能提高一點點mAP,不過計算量成倍的增加,故單尺度訓練的效果更好。)
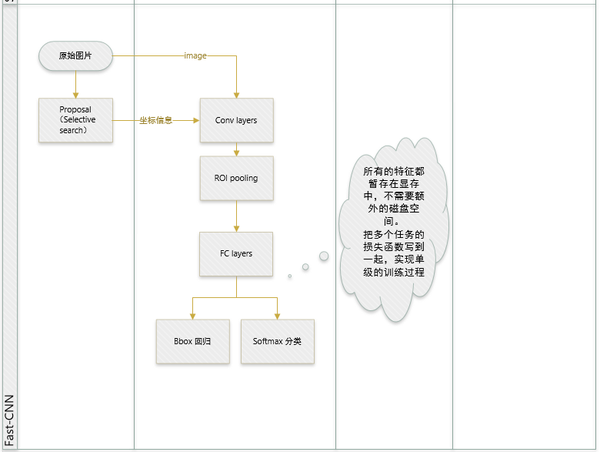
其它貢獻點:
- 指出SPP-net訓練時的不足之處,並提出新的訓練方式,就是把同張圖片的prososals作為一批進行學習,而proposals的座標直接對映到conv5層上,這樣相當於一個batch一張圖片的所以訓練樣本只卷積了一次。文章提出他們通過這樣的訓練方式或許存在不收斂的情況,不過實驗發現,這種情況並沒有發生。這樣加快了訓練速度。 (實際訓練時,一個batch訓練兩張圖片,每張圖片訓練64個RoIs(Region of Interest))
注意點:
- 論文在迴歸問題上並沒有用很常見的2範數作為迴歸,而是使用所謂的魯棒L1範數作為損失函式。
- 論文將比較大的全連結層用SVD分解了一下使得檢測的時候更加迅速。雖然是別人的工作,但是引過來恰到好處(矩陣相關的知識是不是可以在檢測中發揮更大的作用呢?)。
ROI Pooling
與SPP的目的相同:如何把不同尺寸的ROI對映為固定大小的特徵。ROI就是特殊的SPP,只不過它沒有考慮多個空間尺度,只用單個尺度(下圖只是大致示意圖)。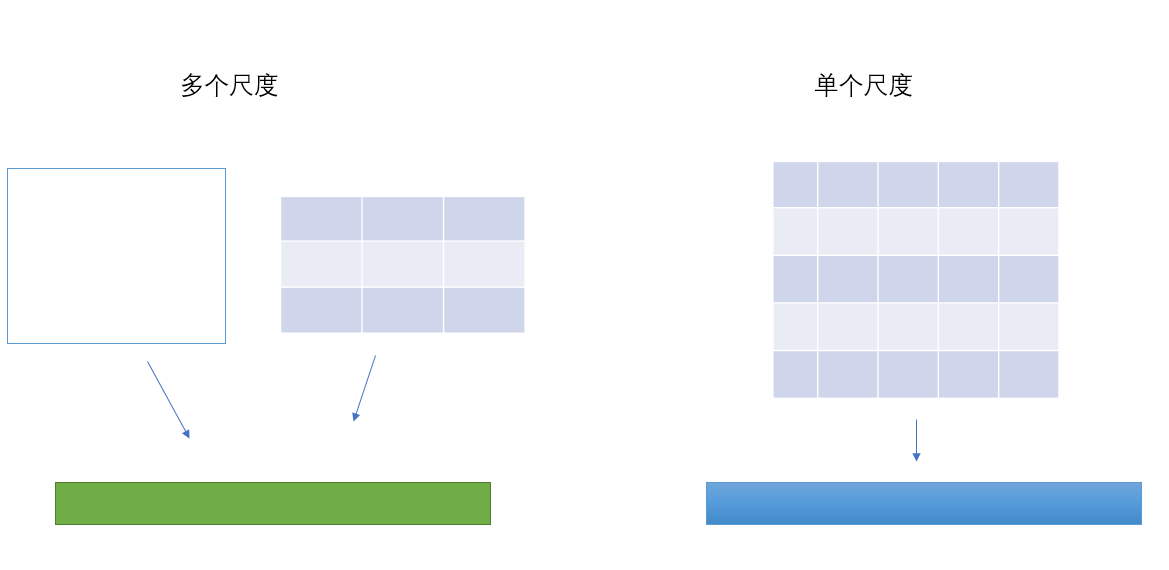
ROI Pooling的具體實現可以看做是針對ROI區域的普通整個影象feature map的Pooling,只不過因為不是固定尺寸的輸入,因此每次的pooling網格大小得手動計算,比如某個ROI區域座標為
Bounding-box Regression
有了ROI Pooling層其實就可以完成最簡單粗暴的深度物件檢測了,也就是先用selective search等proposal提取演算法得到一批box座標,然後輸入網路對每個box包含一個物件進行預測,此時,神經網路依然僅僅是一個圖片分類的工具而已,只不過不是整圖分類,而是ROI區域的分類,顯然大家不會就此滿足,那麼,能不能把輸入的box座標也放到深度神經網路裡然後進行一些優化呢?rbg大神於是又說了"yes"。在Fast-RCNN中,有兩個輸出層:第一個是針對每個ROI區域的分類概率預測,第二個則是針對每個ROI區域座標的偏移優化 ,是多類檢測的類別序號。這裡我們著重介紹第二部分,即座標偏移優化。
假設對於類別,在圖片中標註了一個groundtruth座標:,而預測值為 ,二者理論上越接近越好,這裡定義損失函式:
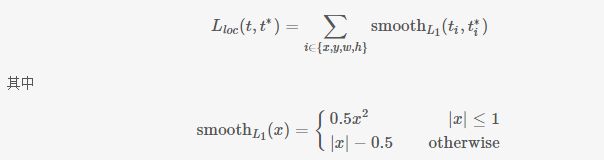
這裡, 中的x即為 即對應座標的差距。該函式在 (−1,1) 之間為二次函式,而其他區域為線性函式,作者表示這種形式可以增強模型對異常資料的魯棒性,整個函式在matplotlib中畫出來是這樣的
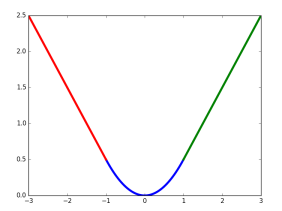
對應的程式碼在smooth_L1_loss_layer.cu中。