
在caffe 中實現Generative Adversarial Nets(一)
阿新 • • 發佈:2019-02-06
目錄
一、Generative Adversarial Nets
1. GAN簡介
對抗生成網路(GAN)同時訓練兩個模型:能夠得到資料分佈的生成模型(generative model G)和能判夠區別資料是生成的還是真實的判別模型 (discriminative model D)。訓練過程使得G生成的資料儘可能真實,同時又使得D儘可能能夠區分生成的資料和真實的資料,最終G生成資料足以以假亂真,而D輸出資料的概率均為0.5 。 參考論文:Bengio大神的 Generative Adversarial Networks
2. GAN訓練過程

注意:這裡的loss在更新D梯度是上升方向,在caffe具體實現時,為了使得D模型梯度更新為梯度的下降方向,loss等價改為: oss=−[log(D(x(i))+log(1−D(G(z(i))))]
二、Deep Convolutional GANs (DCGAN)
1. DCGAN 網路結構
- DCGAN網路結構圖
- DCGAN結構內容
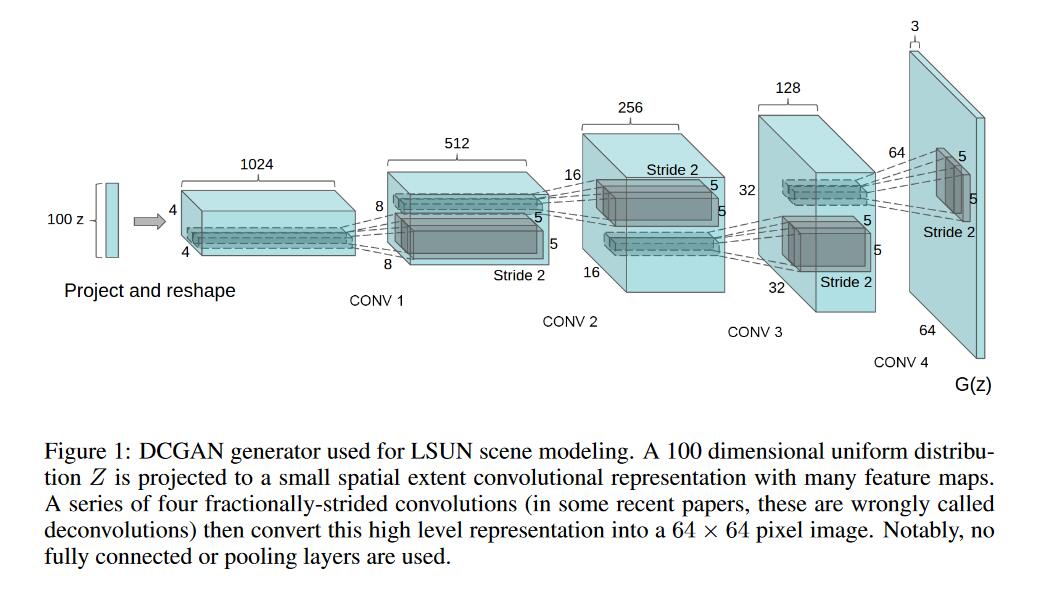

2. DCGAN caffe prototxt
1.train.prototxt
# Create on: 2016/10/22 ShanghaiTech
# Author: Yingying Zhang
name: "gan_newface"
layer {
name: "images"
type: "ImageData"
top: "face_images" 2.solver.prototxt
# Create on: 2016/10/22 ShanghaiTech
# Author: Yingying Zhang
net: "gan_configs/train.prototxt"
debug_info: false
display: 10
solver_type: ADAM
average_loss: 100
base_lr: 2e-4
lr_policy: "fixed"
max_iter: 15000
momentum: 0.5
snapshot: 100
gan_solver: true
snapshot_prefix: "models/gan_"
