
ImageNet 歷屆冠軍最新評析:哪個深度學習模型最適合你?
深度神經網路自出現以來,已經成為計算機視覺領域一項舉足輕重的技術。其中,ImageNet 影象分類競賽極大地推動著這項新技術的發展。精確計算水平取得了穩步的增長,但頗具吸引力的模型應用尚未得到合理的利用。
本文將綜合分析實際應用中的幾項重要指標:準確度、記憶體佔用、引數、操作時間、操作次數、推理時間、功耗,並得出了以下幾項主要研究結論:
功耗與批量大小、體系結構無關;
準確度與推理時間呈雙曲線關係;
能量限制是最大可達準確度和模式複雜度的上限;
操作次數可以有效評估推理時間。
自從2012年的 ImageNet 競賽上,Alexnet取得突破發展,成為第一個應用深度神經網路的應用,其他關於DNN的更復雜的應用也陸續出現。
影象處理軟體分類挑戰賽的終極目標是,在考慮實際推理時間的情況下,提高多層分類框架的準確度。為了達到這個目標,就要解決以下三方面的問題。第一,一般情況下,我們會在每個驗證影象的多個類似例項中執行一個給定模型的多個訓練例項。這種方法叫做模型平均或DNN整合,可以極大提高推理所需的計算量,以獲得published準確度。第二,不同研究報告中對驗證影象做的預估模型(集合)的操作次數不一樣,模型選擇會受到影響,因此不同的抽樣方法(以及取樣集合的大小不同)得出的報告準確度結果就會有所偏差。第三,加速推理過程是模型實際應用的關鍵,影響著資源利用、功耗以及推理延遲等因素,而目前尚無方法使推理時間縮短。
本文旨在對過去4年影象處理軟體分類挑戰賽上出現的不同種類的先進的DNN架構做對比,從計算需要和準確度兩個角度做分析,主要比較這些架構與資源利用實際部署相關的多個指標,即準確度、記憶體佔用、引數、操作時間、操作次數、推理時間、功耗。
文章主要目的是通過分析,強調這些指標的重要性,因為這些指標是優化神經網路實際部署與應用的基本硬性限制條件。
評析方法為了比較不同模型的質量,我們收集了文獻中的一些資料,分析發現不同的抽樣方法得出的結論也不一樣。比如,VGG-16和GoogleNet 的central-crop誤差分別是8.7%和10.07%,表明VGG-16效能優於googleNet,而用10-crop抽樣,則誤差分別是9.33%和9.15%,VGG-16又比GoogleNet差了。於是,我們決定基於分析,對所有網路重新評估,使用單個central-crop抽樣方法。

圖1: Top1 vs. 網路. Single-crop top-1 用最高評分體系檢測準確度。上圖中不同的配色方案表示不同的架構和作者。注意,同組網路共享相同的色相,比如所有的ResNet系列都是用粉色系表示的。
圖 2: Top1 vs. 操作、數量大小、引數 Top-1 one-crop 準確度與單向前進傳遞所需操作次數的對比。圖中氣泡大小與網路引數數量成正比;右下角記錄的是從5*106 到155*106引數值的歷史最大值;所有資料都共享一個y軸,灰色點表示氣泡中心的值。

我們使用 cuDNN-v5和CUDA-v8配置的Torch 7來做推理時間和記憶體佔用測算。所有的試驗都使用的是JstPack-2.3 NVIDIA Jetson TX1,內建視覺計算系統,64-bit ARM A57 CPU。
使用這種限量級的裝置是為了更好地強調網路架構的不同,主要是因為使用現存的大多數GPU,比如NVIDIA K40或者Titan X得出的結果基本都一樣。為了測算功耗,我們使用的是Keysight 1146B Hall電流探頭,內建Keysight MSO-X 2024A 200MHz 數字顯波器,抽樣週期2s,取樣率50kSa/s。該系統由 Keysight E3645A GPIB數控直流電源供電。
我們比較了以下 DDN:
AlexNet (Krizhevsky et al., 2012);batch normalised AlexNet (Zagoruyko, 2016);batch normalised Network In Network (NIN) (Lin et al., 2013);
ENet (Paszke et al., 2016) for ImageNet (Culurciello, 2016);
GoogLeNet (Szegedy et al., 2014);
VGG-16 and -19 (Simonyan & Zisserman, 2014);
ResNet-18, -34, -50, -101 and -152 (He et al., 2015);
Inception-v3 (Szegedy et al., 2015) 以及 Inception-v4 (Szegedy et al., 2016)。
1. 準確率(Accuracy)
圖 1 展示了提交給 ImageNet 挑戰賽的架構的 1-crop 準確率,最左邊的是 AlexNet,最右邊的是 Inception -v4。最新的 ResNet 和 Inception 架構相比其他架構準確率至少高 7%。本文中,我們使用不同的顏色區分不同的架構和他們的作者,同一個網路的色系相同,例如粉色系的都是 ResNet。
圖2 則提供了各網路更詳細的準確率值,將計算成本和網路引數的數量視覺化呈現。首先非常明顯的是,VGG 不管從計算需求還是引數數量方面來說,都是迄今為止最昂貴的架構,儘管它已經被廣泛應用於許多應用程式。VGG 的16層和19層的實現實際上與其他所有網路都是隔絕的。其他的架構形成了一條斜線,到 Inception 和 ResNet 時,這條線開始變平緩。這表明這些模型在該資料集上到達一個拐點。在這個拐點上,計算成本(複雜性)開始超過準確率上的好處。
2. 推理時間(Inference Time)

上圖(圖3)顯示了各架構在每個影象上的推理時間,作為一個影象批大小(從1到64)函式。我們注意到 VGG 處理一張影象所需時間約1/5秒,這使它在 NVIDIA TX1 上實時應用的可能性較小。AlexNet 的批大小從1到64的變化中,處理速度提升了3倍,這是由於它的完全連線層的弱優化,這個發現令人驚訝。
3. 功耗(Power)

由於電流消耗的高頻率波動,功耗的測量相當複雜,需要高取樣電流讀出以避免混淆。在本研究中,我們使用的測量工具是帶電流探頭的 200 MHz 數字示波器。如上圖所示,功耗多數情況下與批大小無關。由圖3可見,AlexNet (批大小為1)和 VGG(批大小為2)的低功耗與較慢的推理時間相關。
4 記憶體(Memory)
分析使用 CPU 和 GPU 共享記憶體的 TX1 裝置的系統記憶體消耗得到的結果由下圖可見,最初最大系統記憶體使用情況是不變的,隨著批大小增加,記憶體消耗增大。這是由於網路模型的初始記憶體分配以及批處理時的記憶體需求隨著影象數量的增加而成比例地增加。
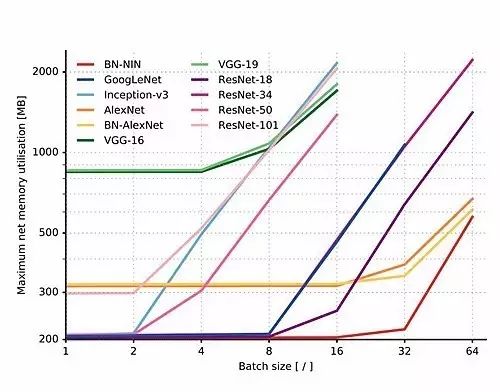
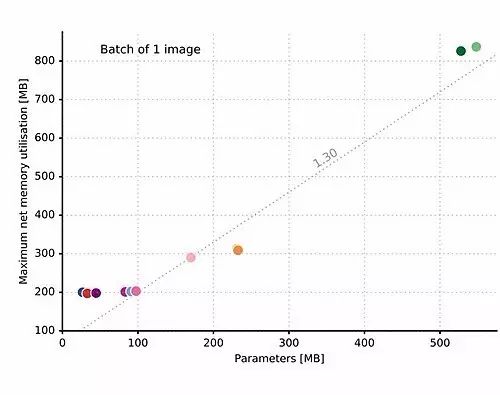
從上圖中我們注意到,對規模小於 100 MB的網路,初始記憶體分配不會小於 200 MB,而且隨後呈現為一條斜率為1.3的線性函式。
5 運算(Operations)
在神經網路加速器的自定義實現中,運算量(operation count)對於預估推理時間和硬體電路體積是必要的。

分析發現,對批大小為16的影象,每個影象的運算量和推理時間之間存線上性關係。因此,在設計網路時,可以控制運算量,以使處理速度保持在實時應用或資源有限的應用的可接受範圍內。
6. 運算和功耗

分析功耗和給定模型所需的運算次數之間的關係後,我們發現不同架構之間沒有特定的 power footprint(見上圖)。當達到完全的資源利用時,通常批大小較大,所有網路的額外消耗大致為 11.8 W,標準偏差為 0.7 W,空閒功率為 1.30 W。這是資源完全利用時的最大系統功耗。因此,如果功耗是我們要關注的點之一,例如電池裝置限制,可以簡單地選擇滿足最低功耗要求的最慢的架構。
7 準確率和吞吐量
我們注意到,在單位時間裡,準確率和推理數量之間存在非平凡的線性上限。下圖顯示,對於給定的幀速率,可以實現的最大準確率與幀速率本身形成線性比例。這裡分析的所有網路均來自公開出版論文,並且已經得到其他研究團隊的獨立訓練。準確率的線性擬合顯示了所有架構的準確率與速度之間的關係。
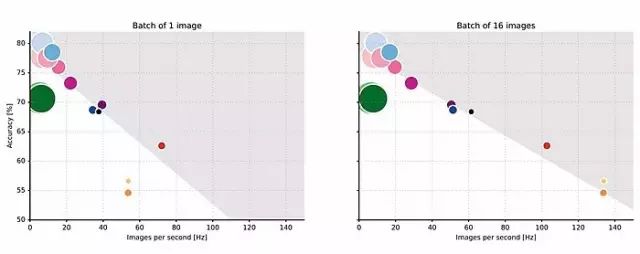
此外,選定一個推理時間,可以得出資源充分利用條件下理論上的最大準確率。由於功耗固定,我們甚至可以進一步得出能耗限制下的最大準確率,這可以作為需要在嵌入式系統上執行的網路的基本設計因素。由於沒有了擾流器,考慮前向推理時間時,準確率與吞吐量之間的線性關係轉變為雙曲線關係。那麼,假設運算量與推理時間是線性關係,準確率對網路需要的運算量則具有雙曲線依賴性(hyperbolical dependency)。
8 引數使用

我們已經知道,DNN 在利用全部學習能力(引數數量/自由度)方面非常低效。Han et al., 2015 的研究利用 DNN 的這個缺陷,使用權重剪枝(weights pruning)、量化(quantisation)和變長編碼(variable-length symbol encoding)將網路規模減小了50倍。值得注意的是,使用更高效的架構能夠產生更緊湊的呈現。如上圖所示,雖然 VGG 比 AlexNet 的準確率更高(圖1),但其資訊密度不如 AlexNet。這意味著在 VGG 架構中引入的自由度帶來的準確率上的提高不大。
結語本文從準確性、記憶體佔用、引數、運算量、推理時間和功耗方面,對 ImageNet 競賽中多個先進深層神經網路進行了分析,從而對設計用於實際應用的高效神經網路提供參考並優化資源,因為在實際部署中我們能使用的資源往往十分有限。從上文可知,神經網路的精度和推理時間呈雙曲關係:準確度的微量增加也會花費大量的計算時間。此外,網路模型的運算量能有效估計推理所需要的時間。
這也是我們為 ImageNet 建立 ENet(Efficient-Network)的原因。ENet 是當前對引數空間利用率最好的架構。

論文下載地址:https://arxiv.org/pdf/1605.07678v3.pdf