Python爬蟲從入門到放棄(十七)之 Scrapy框架中Download Middleware用法
本文出自“python修行路”部落格,http://www.cnblogs.com/zhaof/p/7198407.html
這篇文章中寫了常用的下載中介軟體的用法和例子。
Downloader Middleware處理的過程主要在排程器傳送requests請求的時候以及網頁將response結果返回給spiders的時候,所以從這裡我們可以知道下載中介軟體是介於Scrapy的request/response處理的鉤子,用於修改Scrapy request和response。
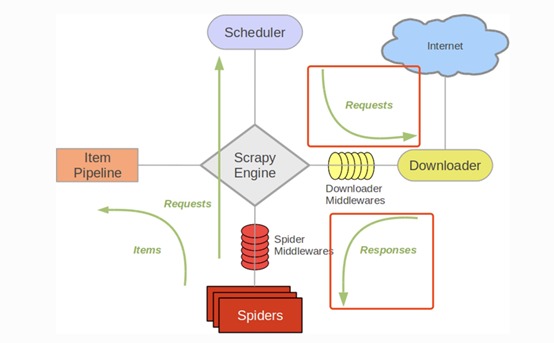
編寫自己的下載器中介軟體
編寫下載器中介軟體,需要定義以下一個或者多個方法的python類
為了演示這裡的中介軟體的使用方法,這裡建立一個專案作為學習,這裡的專案是關於爬去httpbin.org這個網站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
建立好後的目錄結構如下:

這裡我們先寫一個簡單的代理中介軟體來實現ip的偽裝
建立好爬蟲之後我們講httpbin.py中的parse方法改成:
def parse(self, response):
print(response.text)然後通過命令列啟動爬蟲:scrapy crawl httpbin
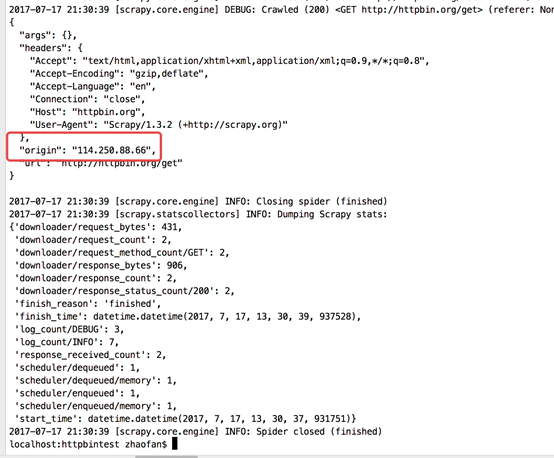
在最下面我們可以看到"origin": "114.250.88.66"
我們在檢視自己的ip:
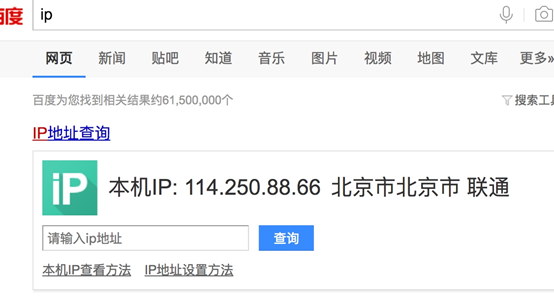
而我們要做就是通過代理中介軟體來實現ip的偽裝,在middleares.py中寫如下的中介軟體類:
class ProxyMiddleare(object):
logger = logging.getLogger(__name__)
def process_request(self,request, spider):
self.logger.debug("Using Proxy")
request.meta['proxy'] = 'http://127.0.0.1:9743'
return None這裡因為我本地有一個代理FQ地址為:http://127.0.0.1:9743
所以直接設定為代理用,代理的地址為日本的ip
然後在settings.py配置檔案中開啟下載中介軟體的功能,預設是關閉的
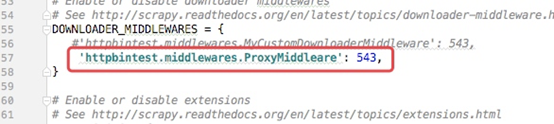
然後我們再次啟動爬蟲:scrapy crawl httpbin
從下圖的輸入日誌中我們可以看書我們定義的中介軟體已經啟動,並且輸入了我們列印的日誌資訊,並且我們檢視origin的ip地址也已經成了日本的ip地址,這樣我們的代理中介軟體成功了
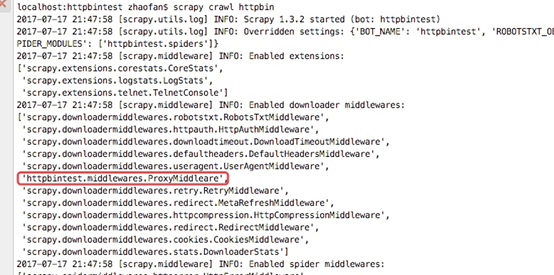
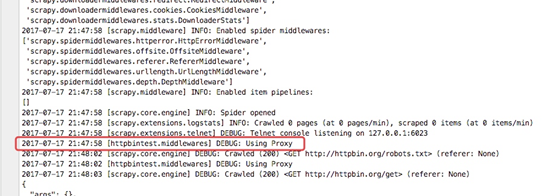
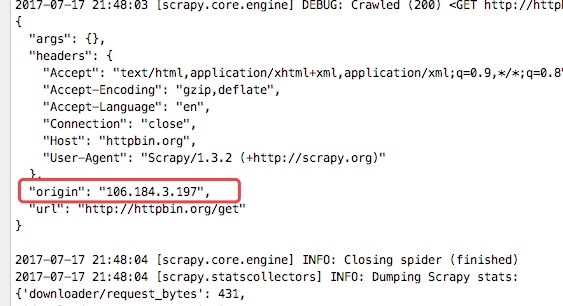

詳細說明
class Scrapy.downloadermiddleares.DownloaderMiddleware
process_request(request,spider)
當每個request通過下載中介軟體時,該方法被呼叫,這裡有一個要求,該方法必須返回以下三種中的任意一種:None,返回一個Response物件,返回一個Request物件或raise IgnoreRequest。三種返回值的作用是不同的。
None:Scrapy將繼續處理該request,執行其他的中介軟體的相應方法,直到合適的下載器處理函式(download handler)被呼叫,該request被執行(其response被下載)。
Response物件:Scrapy將不會呼叫任何其他的process_request()或process_exception() 方法,或相應地下載函式;其將返回該response。 已安裝的中介軟體的 process_response() 方法則會在每個response返回時被呼叫。
Request物件:Scrapy則停止呼叫 process_request方法並重新排程返回的request。當新返回的request被執行後, 相應地中介軟體鏈將會根據下載的response被呼叫。
raise一個IgnoreRequest異常:則安裝的下載中介軟體的 process_exception() 方法會被呼叫。如果沒有任何一個方法處理該異常, 則request的errback(Request.errback)方法會被呼叫。如果沒有程式碼處理丟擲的異常, 則該異常被忽略且不記錄。
process_response(request, response, spider)
process_response的返回值也是有三種:response物件,request物件,或者raise一個IgnoreRequest異常
如果其返回一個Response(可以與傳入的response相同,也可以是全新的物件), 該response會被在鏈中的其他中介軟體的 process_response() 方法處理。
如果其返回一個 Request 物件,則中介軟體鏈停止, 返回的request會被重新排程下載。處理類似於 process_request() 返回request所做的那樣。
如果其丟擲一個 IgnoreRequest 異常,則呼叫request的errback(Request.errback)。 如果沒有程式碼處理丟擲的異常,則該異常被忽略且不記錄(不同於其他異常那樣)。
這裡我們寫一個簡單的例子還是上面的專案,我們在中介軟體中繼續新增如下程式碼:
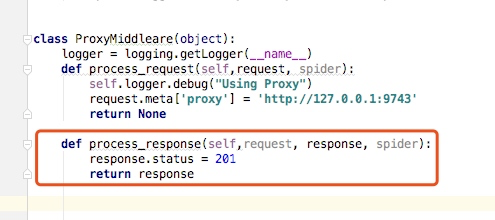
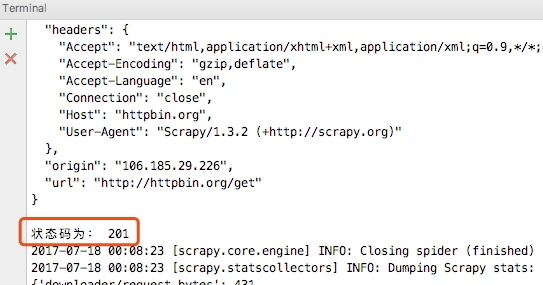
然後在spider中列印狀態碼:

這樣當我們重新執行爬蟲的時候就可以看到如下內容
process_exception(request, exception, spider)
當下載處理器(download handler)或 process_request() (下載中介軟體)丟擲異常(包括 IgnoreRequest 異常)時,Scrapy呼叫 process_exception()。
process_exception() 也是返回三者中的一個: 返回 None 、 一個 Response 物件、或者一個 Request 物件。
如果其返回 None ,Scrapy將會繼續處理該異常,接著呼叫已安裝的其他中介軟體的 process_exception() 方法,直到所有中介軟體都被呼叫完畢,則呼叫預設的異常處理。
如果其返回一個 Response 物件,則已安裝的中介軟體鏈的 process_response() 方法被呼叫。Scrapy將不會呼叫任何其他中介軟體的 process_exception() 方法。
如果其返回一個 Request 物件, 則返回的request將會被重新呼叫下載。這將停止中介軟體的 process_exception() 方法執行,就如返回一個response的那樣。 這個是非常有用的,就相當於如果我們失敗了可以在這裡進行一次失敗的重試,例如當我們訪問一個網站出現因為頻繁爬取被封ip就可以在這裡設定增加代理繼續訪問,我們通過下面一個例子演示
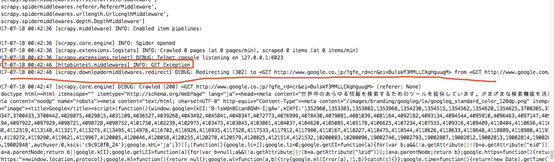
scrapy genspider google www.google.com 這裡我們建立一個谷歌的爬蟲,
然後啟動scrapy crawl google,可以看到如下情況:
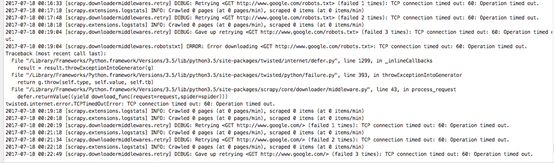
這裡我們就寫一箇中間件,當訪問失敗的時候增加代理
首先我們把google.py程式碼進行更改,這樣是白超時時間設定為10秒要不然等待太久,這個就是我們將spider裡的時候的講過的make_requests_from_url,這裡我們把這個方法重寫,並將等待超時時間設定為10s

這樣我重新啟動爬蟲:scrapy crawl google,可以看到如下:
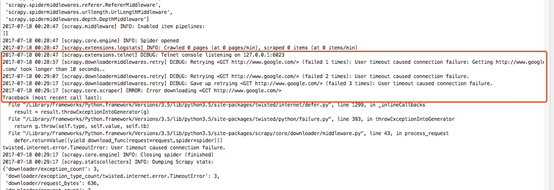
這裡如果我們不想讓重試,可以把重試中介軟體關掉:
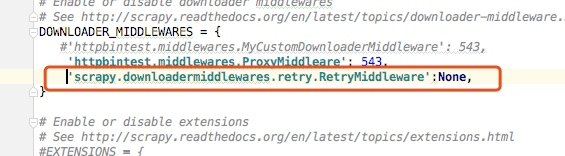
這樣設定之後我們就把失敗重試的中介軟體給關閉了,設定為None就表示關閉這個中介軟體,重新啟動爬蟲我們也可以看出沒有進行重試直接報錯了

我們將代理中介軟體的代理改成如下,表示遇到異常的時候給請求加上代理,並返回request,這個樣就會重新請求谷歌
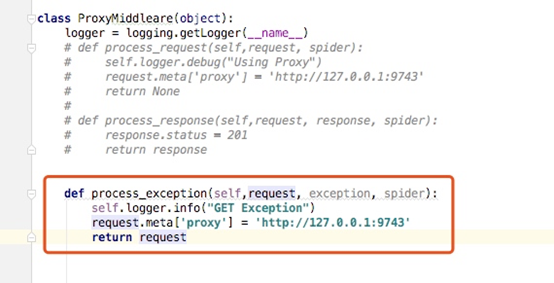
重新啟動谷歌爬蟲,我們可以看到,我們第一次返回我們列印的日誌資訊GET Exception,然後加上代理後成功訪問了谷歌,這裡我的代理是日本的代理節點,所以訪問到的是日本的谷歌站