
十小時入門大資料學習筆記(二)
第二章 初識Hadoop
2.1Hadoop概述
名稱由來:專案作者的孩子對黃色大象玩具的命名
開源、分散式儲存與分散式計算的平臺
Hadoop能做什麼:
1. 搭建大型資料倉庫,PB級資料的儲存、處理、分析、統計等業務
2. 搜尋引擎、日誌分析、資料探勘、商業智慧
2.2Hadoop核心元件
HDFS(分散式檔案系統)
1. 源於Google在2003年10月發表的GFS論文
2. 對GFS的克隆
3. 特點:擴充套件性、容錯性、海量資料儲存
4. 將檔案切分成指定大小的資料塊並且多副本存於多個機器上
5. 資料切分、多副本、容錯對使用者是透明的

YARN(資源管理系統)
1. 整個叢集資源的管理與排程
2. 特點:擴充套件性、容錯性、多框架資源統一排程
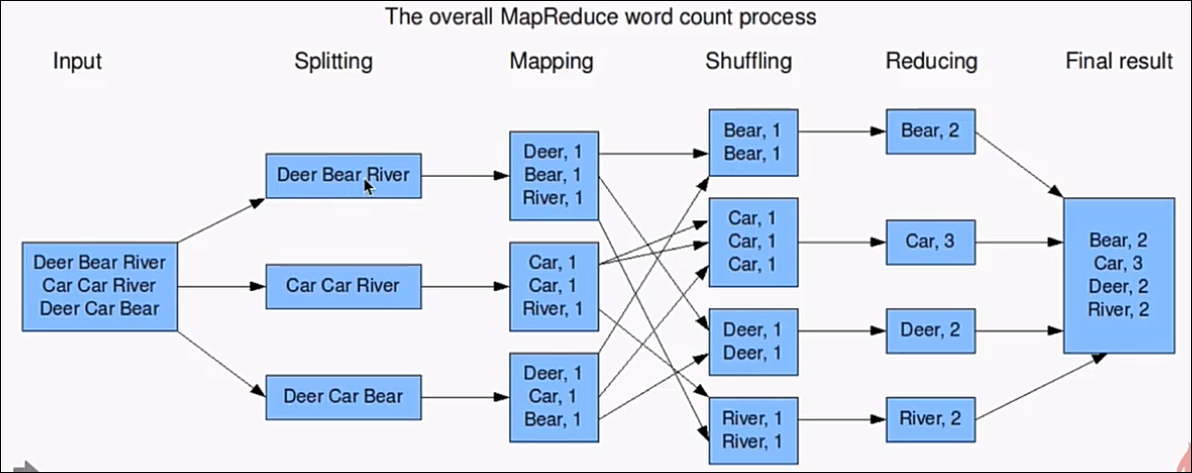
MapReduce(分散式計算框架)
1. 2004年12月的GoogleMapReduce論文
2. Google MapReduce的克隆版
3. 特點:擴充套件性、容錯性、海量資料的離線處理
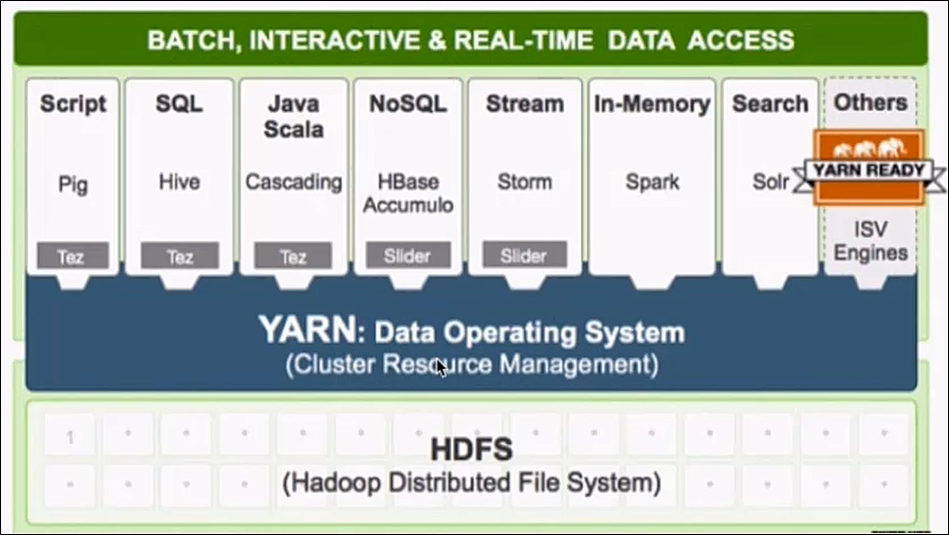
2.3Hadoop優勢
Hadoop優勢之高擴充套件性
1. 儲存/計算資源不夠可以橫向線性的擴充套件機器
2. 一個叢集可以包含數以千計、萬計的節點
Hadoop其他優勢
1. 儲存在低廉機器上、成本低廉
2. 成熟的生態圈
2.4Hadoop發展史
《Hadoop十年解讀與發展預測》
狹義的Hadoop:適合於大資料的分散式儲存(HDFS)、分散式計算(MapReduce)和資源排程(YARN)的平臺。
廣義的Hadoop:
2.5Hadoop的生態系統
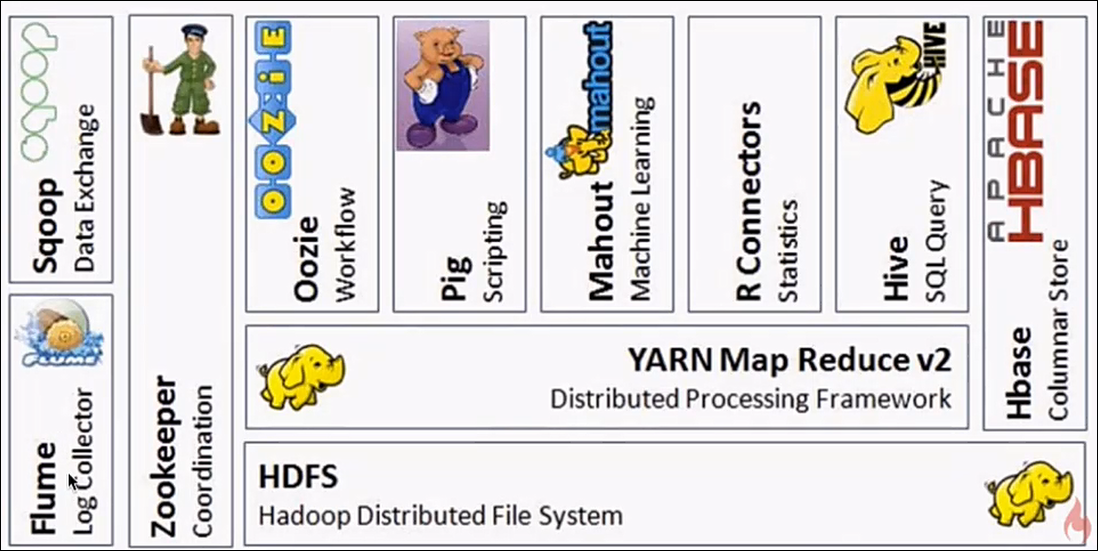
生態系統特點:
1. 開源、社群活躍
2. 囊括了大資料處理的方方面面
2.6Hadoop發行版的選擇
1. Apache Hadoop
2. CDH(Cloudera Distributed Hadoop)
3.HDP(Hortonworks Data Platform)
2.7企業中的應用案例
1. 消費大資料
2. 商品零售大資料